






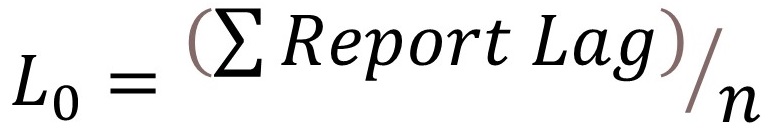
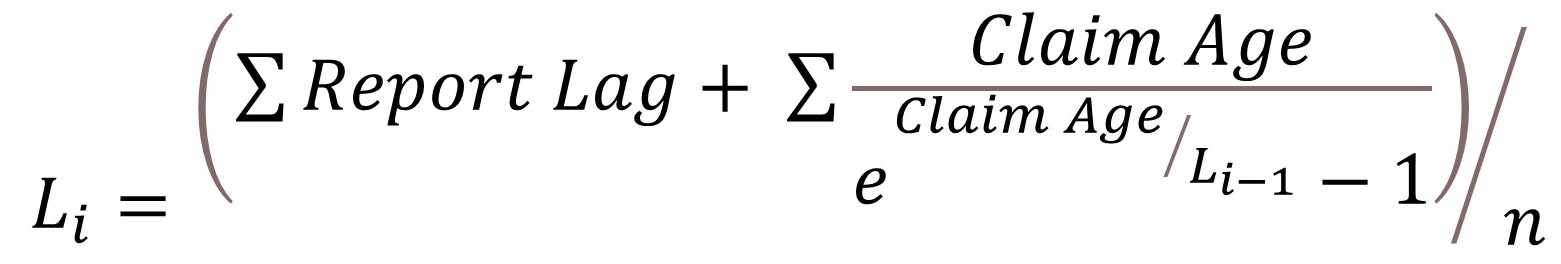





Note regarding the use of ‘IBNR’ in this paper:
Unless specifically noted to the contrary, in this paper, “IBNR” will refer to only the provision for those claims that have truly not been reported as of the date of the analysis, and “case development” will be used to refer to the provision for additional development for known claims.
Note on organization of this paper:
This is a lengthy document owing to the significant work necessary to build a claim life cycle model. A reader that already accepts the argument of why such a framework is important may want to skip section 2. Another reader that is primarily interested in the motivation for this approach and down-stream applications may want to skip sections 4 and 5, which are focused on the modeling details.
1.0. Introduction[1]
This paper describes approaches to incorporate detailed claim and exposure data into the actuarial process of estimating property-casualty reserves. Using detailed data provides additional insight into needed reserves. Since loss development considerations are critical to questions of pricing, significant insight can be gained in actuarial pricing as well. Internal management reporting also benefits, allowing for more reliable reporting of results at various levels of detail.
Predictive models of various aspects of claim development (such as closure rate, claim revaluation, payment rates, etc.) within a time-step (month, quarter, year, etc.) are described, differentiating by policy and claim characteristics. Simulation then projects each open claim to an ultimate value using the combination of these models.
We then describe actuarial case reserves, which provide an important bridge between detailed development models and the traditional triangle reserving framework. We illustrate the use of this algorithm as an alternative to traditional case reserves and discuss its benefits. Validation of the algorithm using report-period triangles will also be discussed.
To develop a provision for unreported claims, the paper describes the creation of emergence models – report lag, frequency, and severity. Simulation is used to generate true IBNR claims, or the emergence models can be used directly to provide mean estimates of their value at a policy level at a point in time. Like actuarial case reserves, these policy reserves can be used as data element in the traditional triangle approach.
The implications of using detailed actuarial claim and unreported claim reserves to support actuarial pricing efforts as well as internal management reporting will also be discussed.
There is a growing body of literature regarding actuarial reserve estimation using detailed claim and policy data that the reader may wish to consider in addition to this paper, such as Parodi (2013), Antonio and Plat (2014), Korn (2016), and Landry and Martin (2022).
2.0. Why a Claim Life Cycle Model is Needed
Analysis of triangle data is well established within the actuarial profession. The output from triangle analysis is well understood by professionals across the industry.
Computing power and increased use of predictive analytics make it possible to substantially improve reserve analysis by systematically considering detailed claim and policy information. It is well documented in the actuarial literature[2] that underlying changes in claim mix, case reserve adequacy, or settlement speed, if left undetected and unadjusted for, can lead to erroneous estimates. Most approaches within the profession have focused on identifying and correcting for such distortions.
Several actuarial problems illustrate the advantages of using detailed data rather than reliance on traditional development triangles alone. We will discuss a number of these problems below.
2.1. Mix Shifts
Any significant difference in loss development patterns across claims and differences in expected loss ratios across policies has the potential to cause problems for triangle analysis unless the mix of claims and exposures is held reasonably constant. This problem is well-known, but due to the wide variety of exposures (deductibles, locations, policy forms, customer characteristics, etc.), mix changes can remain hidden for years without detection, when patterns have been shown to be conclusively different than in the past.
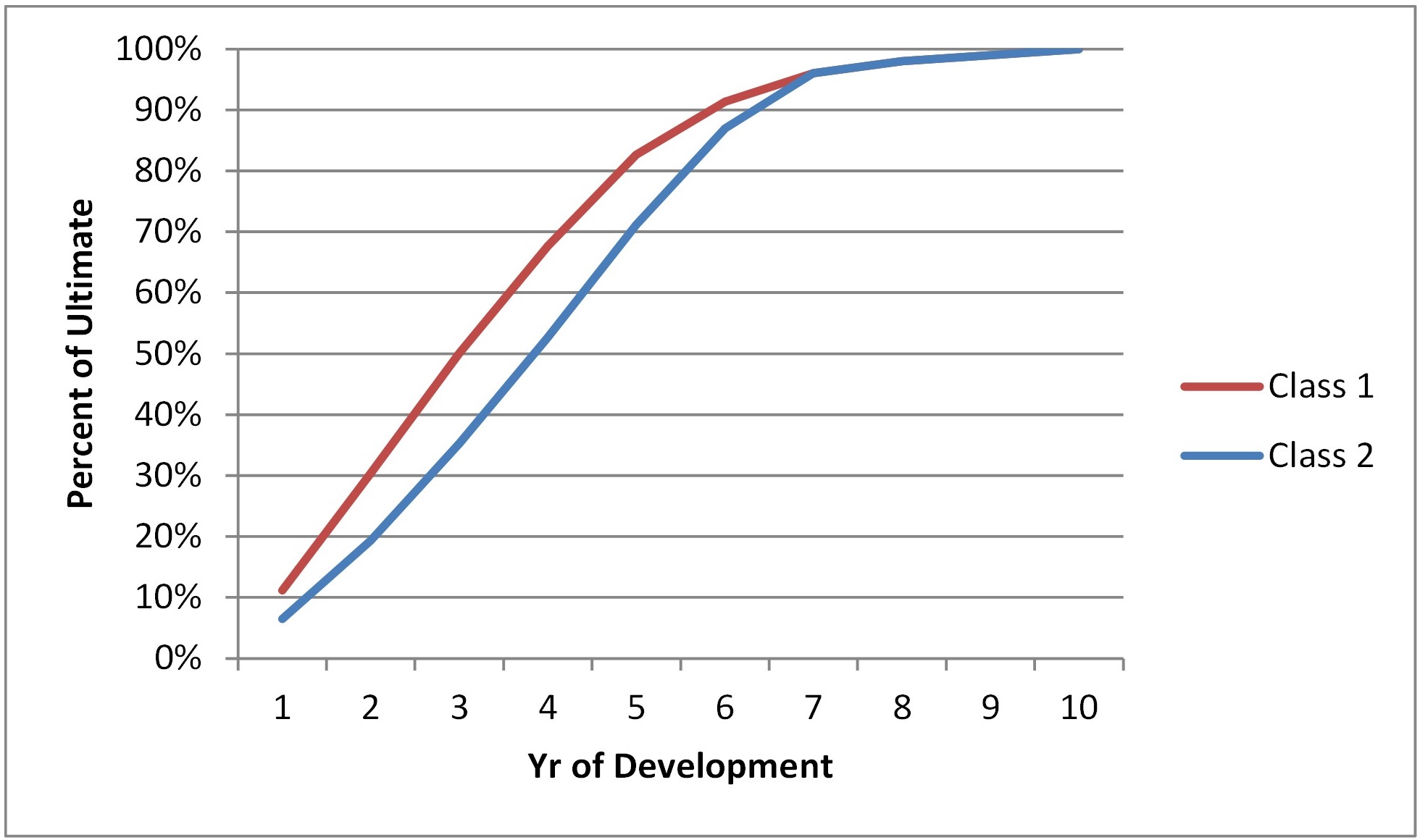
Consider an underwriting unit that writes two classes of business. Until recently there has been a stable mix of business between these two classes with Class 1 making up the majority of the business. The book has had a loss ratio near 60%. Due to this acceptable loss ratio and the relatively insignificant amount of Class 2 business, differences in the performance of the two classes has remained undetected. Class 2 develops slower and has a higher expected loss ratio (90% vs. 60%). The graph below shows the different expected development patterns of the two classes. At year 3, Class 1 is 50% developed while Class 2 is only 35% developed.

Differing development patterns of Class 1 and Class 2 business
The mix of business between the two classes was unchanging until 2013 when the company grew its Class 2 business. The triangle below shows the case-incurred losses:

Loss Triangle

Development Factors
Examination of the triangle reveals little. The 2014 age 1-2 factor is the highest in the triangle, but not dramatically higher. The 2013 age 2 to age 3 factor isn’t the highest for this age. Since the beginning of the change in mix, there are only three data points in the triangle with which to observe a change in loss development. Since nothing significant is observed, it is reasonable for the actuary to conclude that there is no change. Even if a change in development were detected within the first two development periods, there is no information in the triangle about how this development will continue beyond age 3.
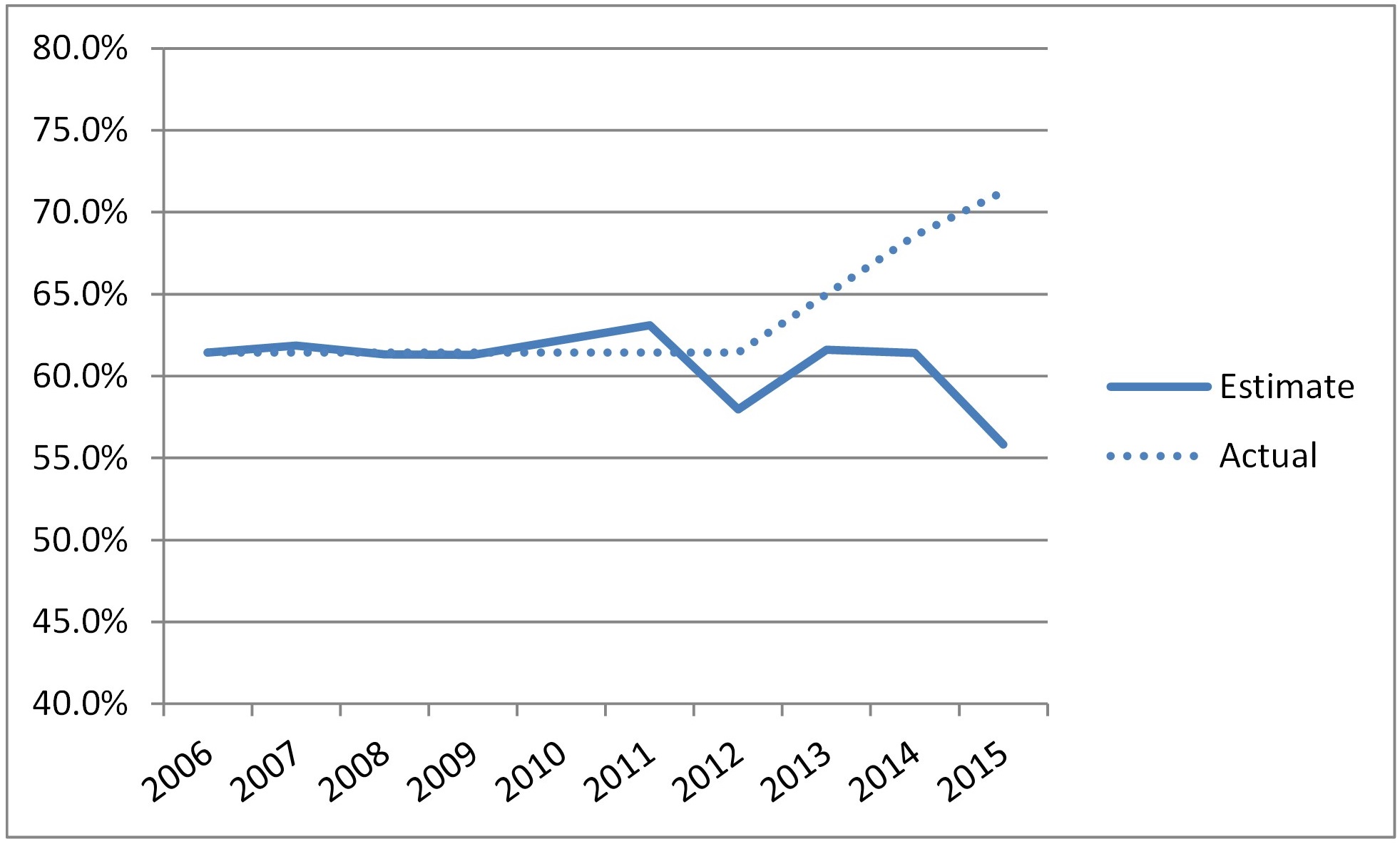
Applying the measured LDFs produces the estimated ultimate loss ratios shown in the graph below. These estimated ultimate loss ratios for the last three years are very different from the true underlying loss ratios of the book.

Estimated Ultimate Loss Ratio vs. True Loss Ratio
The estimated ultimate loss ratio for 2015 is particularly distorted. This is a result of the slower reporting of the Class 2 business and the application of a loss development factor which is not appropriate for the current mix of business. Without a mechanism to capture differences in expected loss ratios and development patterns at a level below the triangle, the actuary will be late in identifying the deteriorating loss performance and will mistakenly estimate an improving loss ratio.
This example demonstrates how the impact of a shift in the mix of business can mislead the actuary. Detection of the problem could take years. Meanwhile the late detection can have devastating effects, as it will likely influence underwriting decisions. If the increase in Class 2 writings is noticed together with the apparent improvement in loss ratio, management could conclude that additional growth in Class 2 should be encouraged. Financial statements reinforce the idea until booked reserves deteriorate, years later.
It is tempting to dismiss this example. In hindsight, the problem was easy to identify –a shift in the mix of business by class. Perhaps there are mechanisms in place to report on shifts of mix by class so changes can be evaluated early. The challenge lies in the wide variety of exposures commonly underwritten. Avoidance of this problem depends upon identifying that a mix-shift has occurred that results in a change in development. Companies can monitor for shifts by class, by geography, by deductible, limit, etc., but differences in development will not be obvious unless triangles are segmented along the dimensions that are shifting. It is not feasible to develop and analyze triangles by every dimension. Further, if differences in development are not identified, differences in loss ratios cannot be adequately identified until losses are mature. In the example given above, assume that the actuary was monitoring the mix of classes and considering the loss ratios of the individual classes, assuming that the development patterns were the same. In this case, it would look like Class 2 had seen a dramatic improvement in loss ratio (a mistaken view caused by an insufficient development pattern). Class 2 might be viewed as having a high loss ratio in the past when less of it was written, but now that it is a focus of the business, the loss ratio has improved dramatically. This is an illusion created by the slower development while in reality the loss ratio is still high.
It is not at feasible to monitor a book of business for this type of problem across all possible dimensions, without a systematic, multivariate approach to modeling loss development and identifying problematic mix-shifts. Changing actuarial loss reserving from the current, aggregated approach is necessary to detect such problems before they cause significant financial damage.
2.2. Changes in case reserving/timing
Changes in case reserving practices within a company can cause significant difficulty in triangle-based reserving approaches. As with mix shifts, the problem is lack of detection. Diagnostics such as triangles of average case outstanding and triangles of closure rates are commonly used to detect changes, but the aggregation of data obscures measurement. Changes in case reserve adequacy may not be detectable in a triangle until evidenced by changes in loss development factors. Consider a scenario with a claim department under pressure to set case reserves lower while the underwriting department is under pressure to write higher severity accounts (both possible when a company is under pressure). This could result in average case reserve amounts that are similar to the past, despite the drop in case reserve adequacy. Aggregated data is insufficient to alert the actuary to the changes. The natural variability in loss development clouds the picture and makes it even harder to detect the change. It is financially harmful to wait until the evidence from the aggregated data becomes conclusive. If the changes can be detected earlier, through systematic investigation of detailed data, significant damage can be avoided.
Most actuaries are comfortable with inadequate or redundant case reserves, provided the aggregate level of adequacy does not change[3]. However, case reserve adequacy can vary widely across different segments of the claim portfolio. With the mix of claims constantly changing across many dimensions, aggregate case reserve adequacy is constantly changing, even with no change to how case reserves are being set for any particular type of claim.
2.3. Projections and Monitoring of Results
It is common to allocate aggregate reserves to a finer level of detail for the purpose of monitoring and managing various segments of the business (profit center, region/office, agency, etc.)
Typically, the allocation is simple and based on earned premium, outstanding case reserves, payments to date, etc. The simplistic allocations can create distortions. When the allocation of these bulk reserves impacts bonus and other incentive payments it is likely to also impact business decisions. If the bulk reserves are allocated in a way that does not reflect reality, misguided business decisions can result.
It is natural when losses develop differently than projected to investigate the variance. When reserve estimates and development projections are calculated at a broad level and allocated naively the search for explanations is challenging. Answers often focus on large claims but miss broader issues until more variances are exhibited in subsequent periods. Similarly, underlying issues can remain hidden because the random nature of large claims obscures them.
When the reserve analysis is performed based on individual claims (and policies in the case of unreported claims), the resulting estimate already exists at the finest level possible. There still will likely be some difference between management’s booked reserve and the analysis, but the detailed analysis provides a natural allocation basis for this difference. Not only does this lead to more appropriate business decisions, but also enables powerful management reporting that allows thoughtful drill-downs to other segmentations of the business without additional reserve development analysis. A detailed allocation that is tied directly to open claims, based on their individual potential to develop and to individual policies based on their likelihood of generating additional claims is more robust. Regular examination of development versus expectations can be monitored statistically at a detailed level to identify emerging trends instead of hunting for an answer when large variances are observed.
2.4. Detect changes in environment
There are often changes within a triangle over time that have nothing to do with mix of business, claims handling practices, or any other action of the insurance company. Examples of these types of changes are inflation, changes in litigiousness, or changes in nature of awards arrived at through litigation.
Companies are certainly aware of and concerned about these changes and are often thinking about them. However, it is likely that these will go undetected, especially if traditional triangles are the only tools being used.
A predictive analysis in which transaction date is itself a predictive variable is very helpful in detecting these environmental changes, identifying and measuring impacts observed in the past and giving context for the relative level of stability or instability in the observed environment.
2.5. Cohesive framework across reserving and pricing
Actuarial reserving functions and pricing functions are often seen as being distinct. Since pricing usually begins with a reserving analysis (explicitly or implicitly), and since reserve estimates are improved by a thorough understanding of changes in pricing and product strategy, the two disciplines are linked. When these functions operate separately, important information may not be communicated. Reserving actuaries may not be aware of all the changes across the products being written (mix changes, pricing decisions, etc.).
Pricing actuaries may miss important information about reserve development (changing case adequacy, differences in development across policies, etc.). This can distort pricing indications. With expanded use of predictive analytics in insurance pricing, it is easy to make erroneous conclusions by assuming that case-incurred loss differentials are indicative of ultimate loss differentials. Often this can lead to concluding that slower developing segments of the portfolio are performing better than they truly are and that faster developing segments of the portfolio are performing worse than they truly are.
Using individual claim-based actuarial reserving approaches leads the reserving actuary to systematically consider changes in the mix of business and price level. Additionally, the resulting policy level reserve estimates allow the pricing actuaries to use more sound ultimate values in their analyses.
2.6. Layer results/Reinsurance
When considering expected loss within a loss layer, either for pricing or reserving for primary or reinsurance layers, there are additional challenges when using traditional triangle analysis. Excess layers may have limited experience in the history. The use of selected development patterns in different layers can lead to inconsistent results. For example, analyses performed gross and net of reinsurance, with development factors selected independently for each, with a thin ceded layer could lead to accident periods with negative ceded reserve estimates.
Models of detailed reserve development help with this problem. The potential for claims to pierce into individual layers can be considered as part of one cohesive development model.
For a ceding company, organizing the necessary information is straightforward. For assuming companies, this can be more problematic. Often, however, there is a requirement to report claim activity to the excess carrier/reinsurer when a claim exceeds a threshold, such as 50% of the retention. Modeling the detailed claim behavior of these sub-layer claims can provide significant information about the layer of interest.
3.0. Model Overview
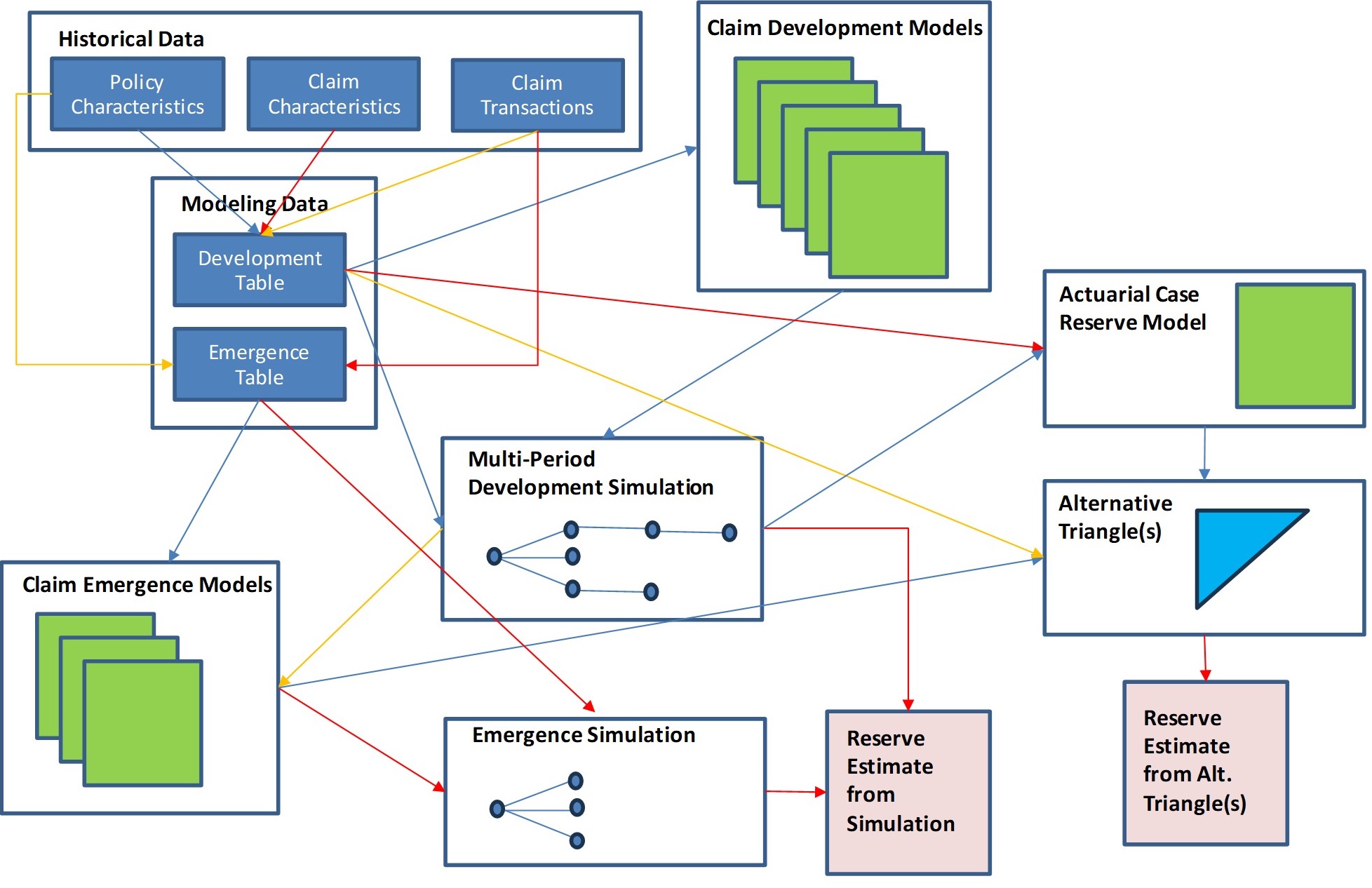
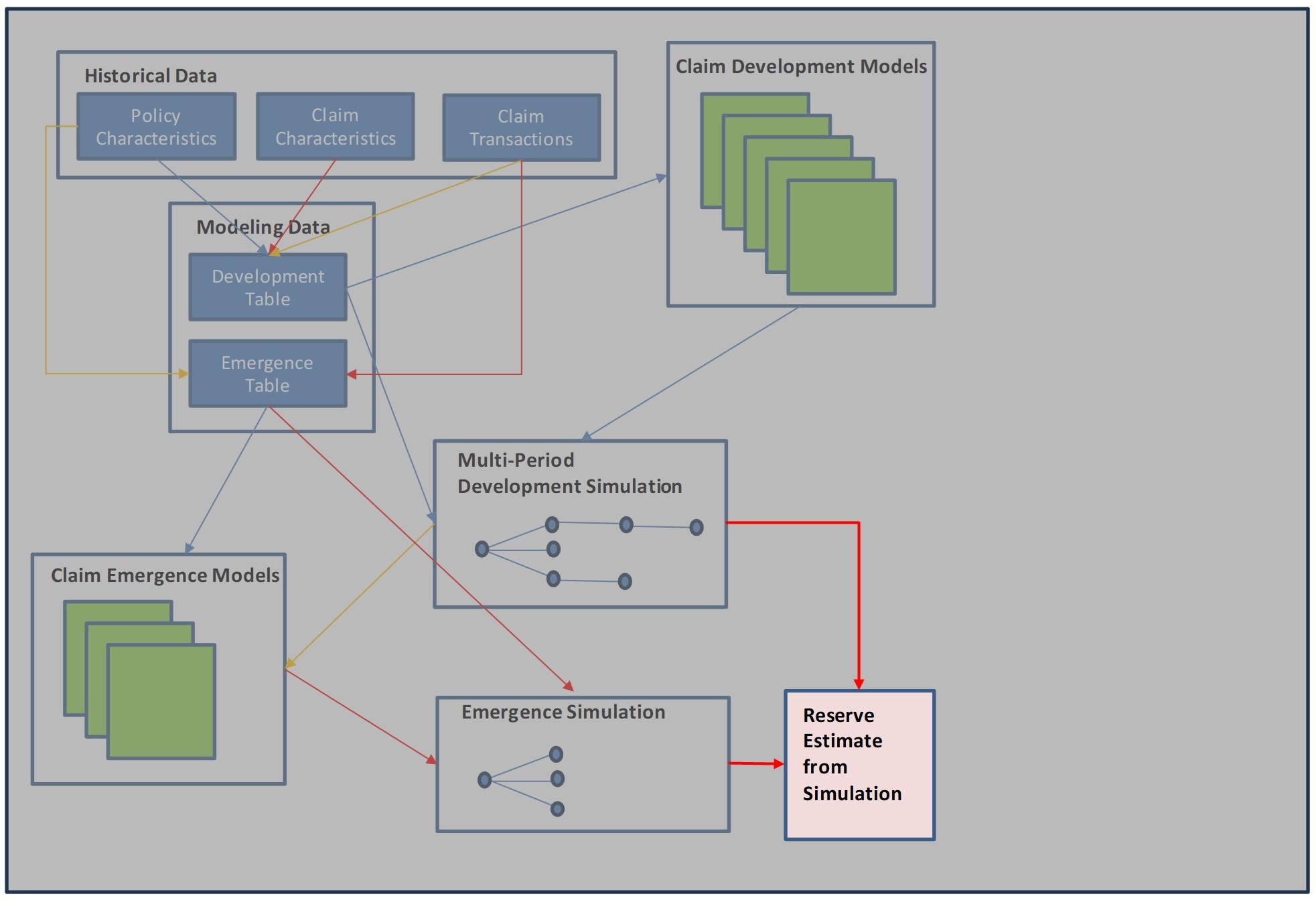
The Claim Life Cycle Model (CLCM) described in this paper involves:
-
organization of data elements into tables that are readily modeled
-
development models that describe the time-step behavior of known claims
-
emergence models that describe the emergence of IBNR claims
-
simulation of future development and emergence at a detailed level
-
creation of actuarial case and policy reserves
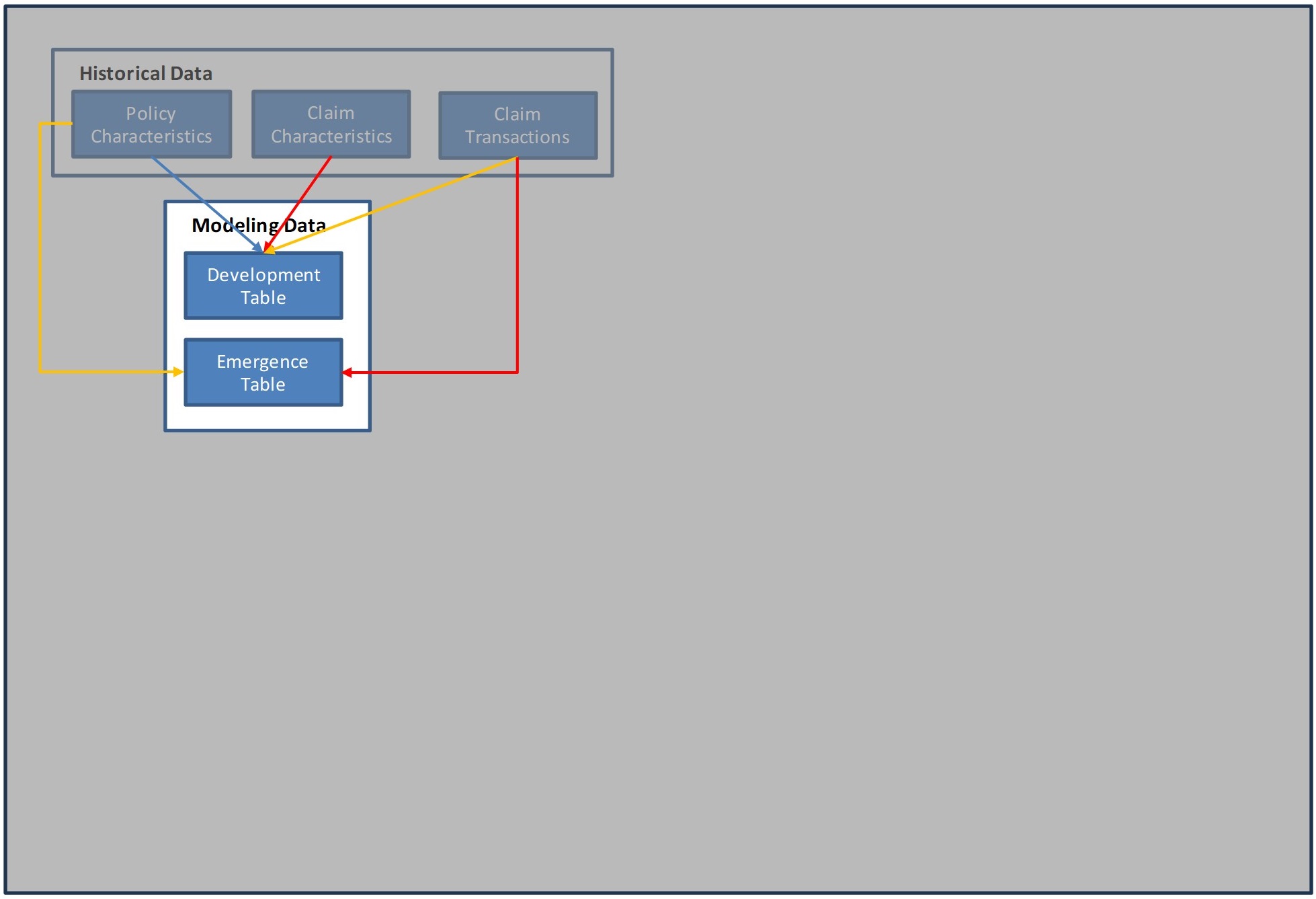
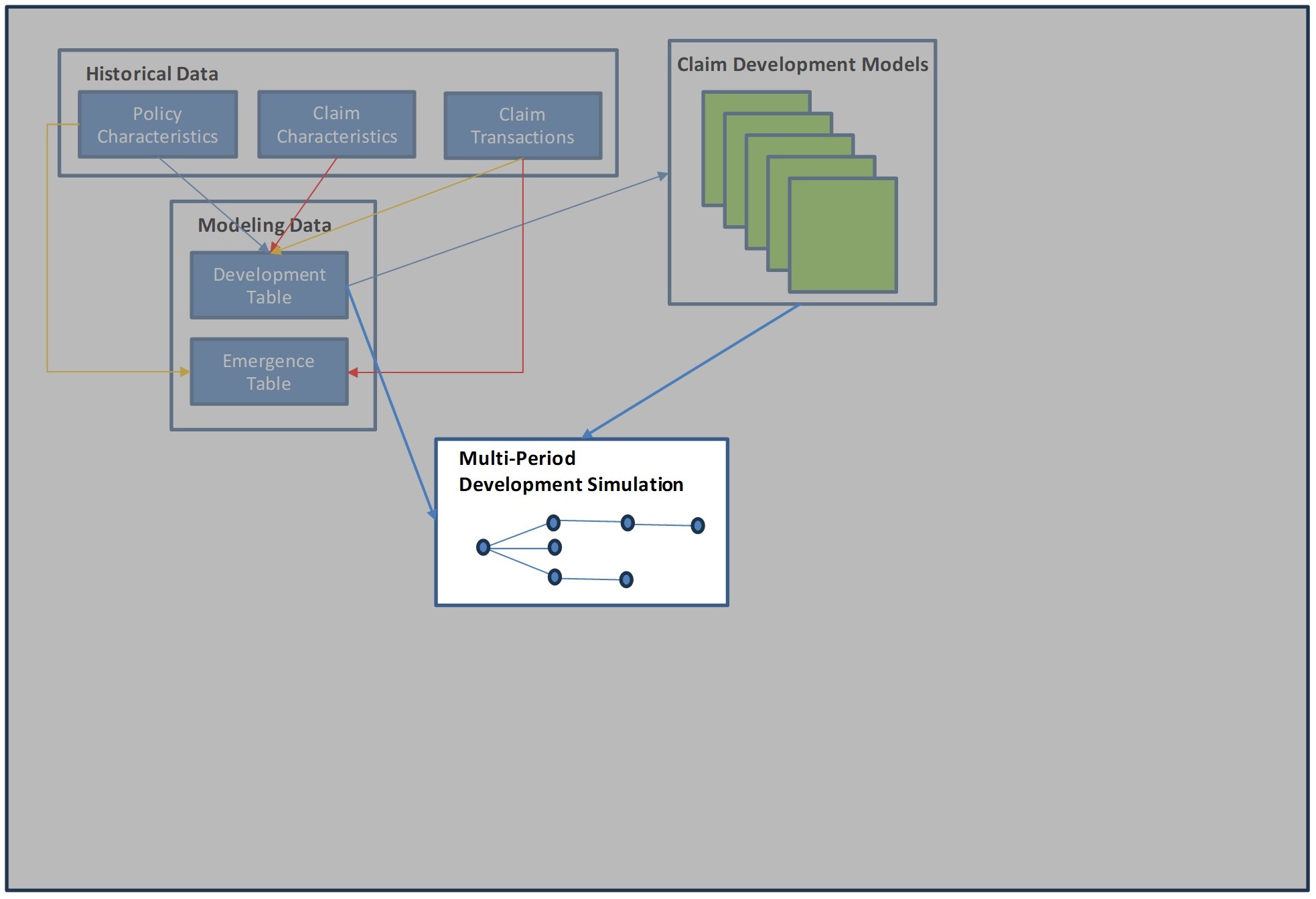
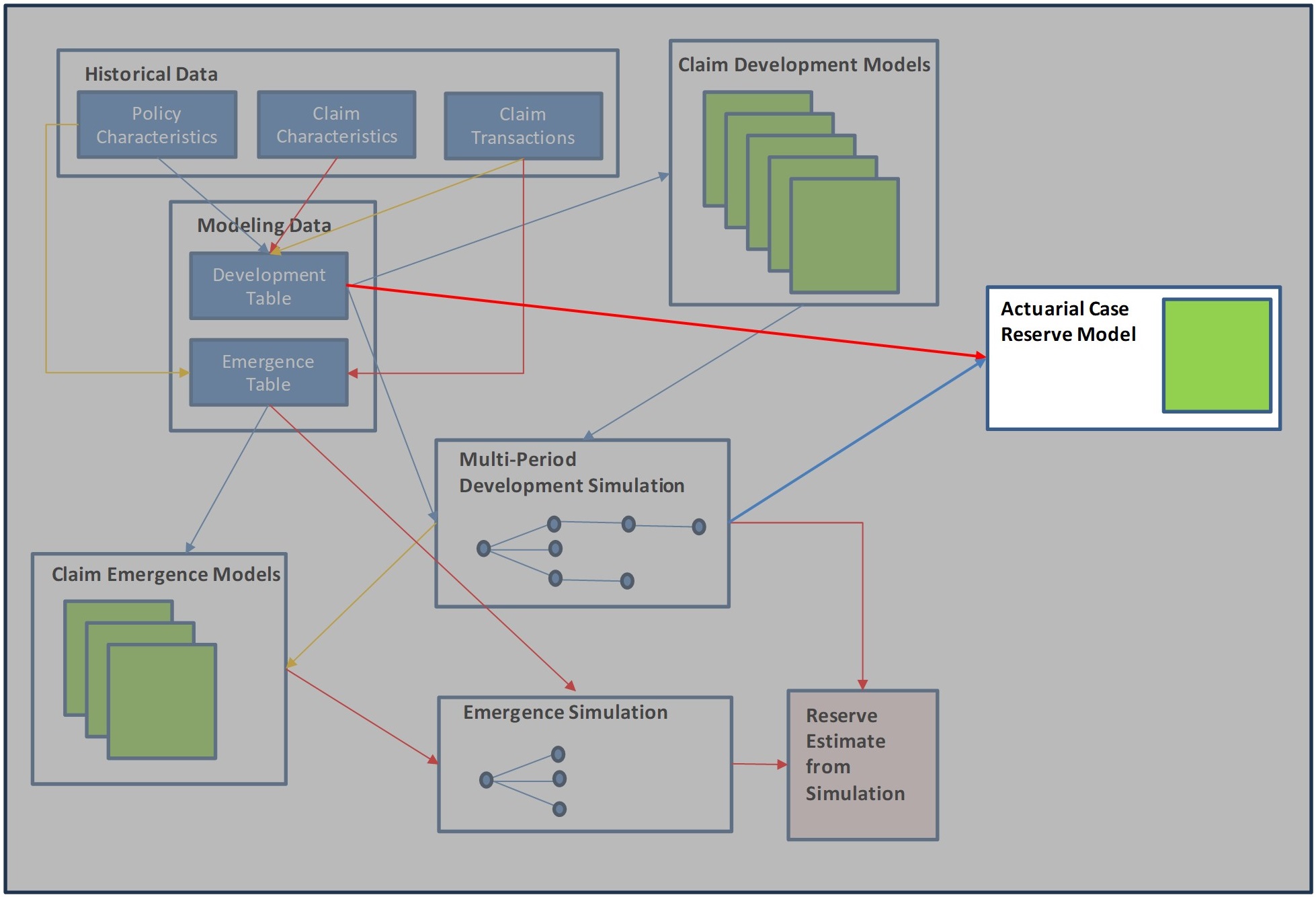
The flow chart below summarizes this process. We will focus on individual parts of this process in the following sections. Blue rectangles represent data tables. Green squares represent predictive models. The arrows show dependencies within the process (colors added to improve readability).

3.1. General Predictive Model Commentary
Predictive models form the backbone of this approach. This paper does not prescribe the form of the predictive models, instead focusing on the various targets of prediction and how the different models work together to build the overall approach. But generally, as is the case with most predictive modeling, the models should:
-
Provide a framework for predicting the mean of the target variable, given the predictive characteristics.
-
Aim for parsimony. All potential predictive variables should be considered, but only those that are found to have predictive power should remain in the final model that is selected. Validation data should be used to compare alternative models to reveal which characteristics are actually providing predictive power, marginal to the other characteristics. Overfitting to training data should be rigorously avoided.
-
Test data should be held out. In addition to describing model veracity, this data becomes critical in this approach when simulating future results as will be discussed in section 5.1.3.
Since the individual time-step models will be used to simulate future development, with simulation results from one time step being used as inputs into the next time step, it is critical that models are robust. To that end, it is useful to use a modeling approach that includes credibility adjustment of model parameters, instead of a purely binary choice of whether the parameter remains in the model. Using iterative techniques such as Multiplicative Bailey Minimum Bias with credibility adjustments is a practical and robust approach to model parameterization, taken together with the discipline to remove extraneous variables, test model results, consider variable interactions, etc.,[4].
It is helpful to define the training dataset as the claims associated with a specific subset of policies. With all claims from an individual policy in one set or the other, overfitting risk due to non-independence of data between training and validation/test is reduced. When detailed data is later organized into triangles, the results will be more meaningful for training or test triangles, because all transactions for a policy will be in either one or the other, not scattered across both test and training data sets.
4.0. Input Data
4.1. Necessary Data
Three tables are necessary to perform this type of analysis, a Claim Transaction table, a Claim Characteristic Table and a Policy Characteristic table:

The Claim Transaction table contains the financial history of the claims. Every time there has been a payment (loss or DCC) or a change in case reserves, there is a record with the transaction, the date, and the claim ID.
The Claim Characteristics table contains information about the claim, including the incurred date, and other available information. In addition to coded fields specific to the line of business, claim notes are a valuable predictor, typically through the use of topic assignment, such as by Latent Dirichlet Allocation. The Claim ID allows for joining to the transaction history. Also necessary is a policy ID, so that the data can be joined to the policy data.
Some variables may be dynamic in nature (changing over the lifetime of a claim). These should not be used as predictors unless the changes themselves are modeled. To do this, a history of changes in the variable at the claim level needs to be made available, similar to the Claim Transactions table.
The Policy Characteristics table includes the policy ID, the premium for the policy, and any available characteristics describing the policy. In some cases, the records can be more specific than policy (e.g., policy, class, and state), but only if the premium is available at that level and the Claim Characteristic table has the same dimensions.
4.2. Data Organization
Two tables are created to organize the data for modeling purposes, a Development Table and an Emergence Table

The Development Table organizes the information by claim and age of development. A time step is first determined (monthly, quarterly, yearly), and every claim will have a record for each step, starting with the step in which the claim first appears. The following fields are necessary on this table:
-
Case Reserve at the beginning of the step
-
Case Reserve at the end of the step
-
Payments during the step
-
Payments to date
Each record should contain the characteristics from the Claim Characteristics table and the Policy Characteristics table. The table can be thought of as being similar to a development triangle, but at the claim level and containing all the characteristics.
The Emergence Table will be used for modeling IBNR claims and is a copy of the Policy Characteristics table, but with non-zero claim count added. For closed claims with positive payment amounts, these are taken from the transaction table. For claims that are still open, the claim count will be determined after simulation (to avoid counting future claims with no payment)
Other fields will be added to the Development Table and Emergence Table in subsequent sections of this paper.
5.0. Component Development Models and Simulation
We next will describe the various predictive models that describe the behavior of claims and the simulation used to bring these various models together into reserve estimates, first for the reported claims and then for the unreported claims.
5.1. Reported Claims

This section will focus on developing a detailed description of the claim development process, by considering what happens within an individual time-step and how that behavior varies across claim and policy characteristics. Rather than focus on the ultimate value of claims (which is only observable for the older claims), we examine the behavior of a claim in a time-step. What is the likelihood that a claim will close in the next quarter? What is the likelihood that it will change in value? If it does change in value, how much? What is the probability of a payment? If the claim does have a payment, how much? By considering these components of development, we can develop an understanding of the process that can be extended to ultimate while still incorporating information from immature claims.
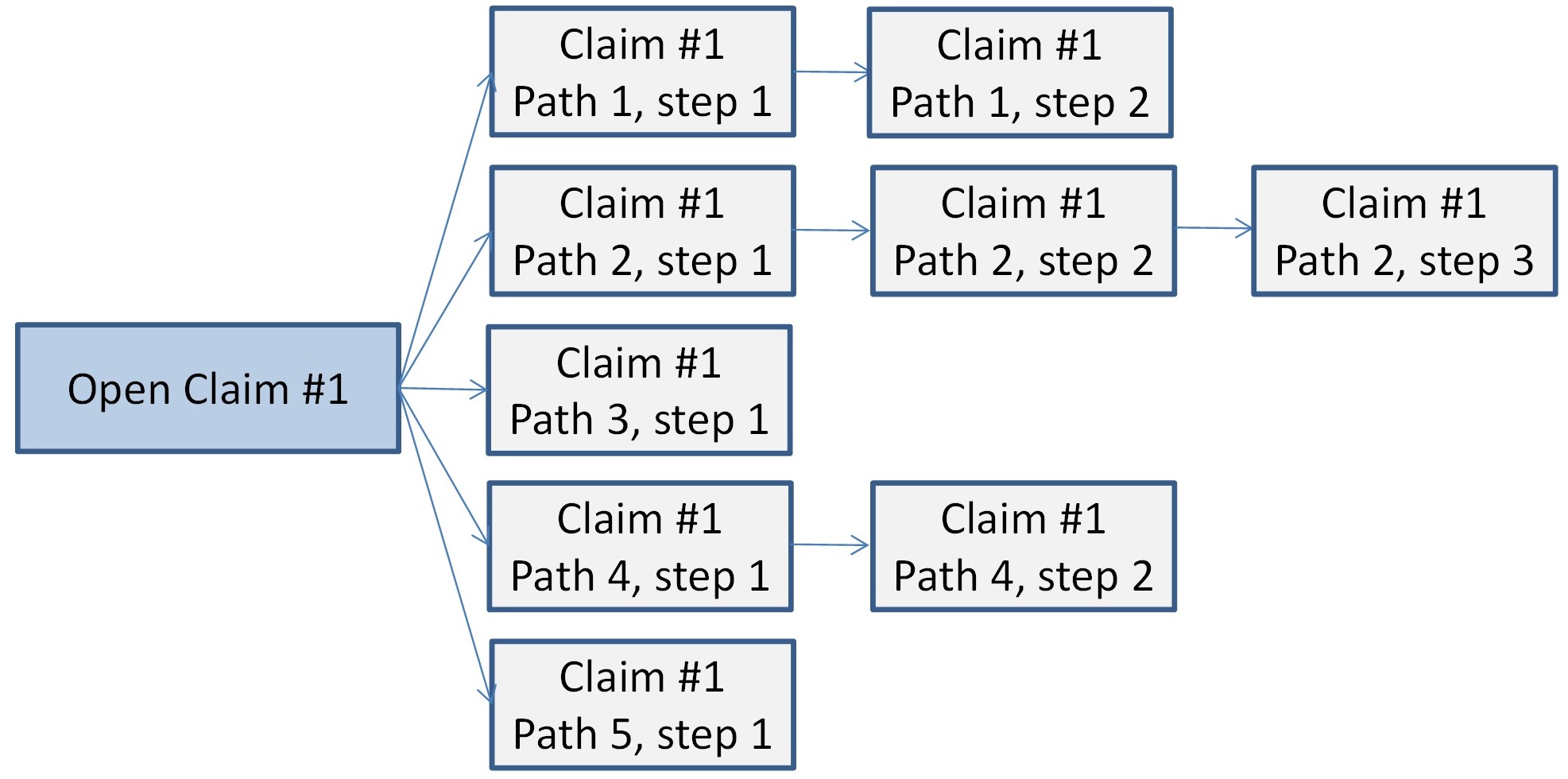
Including covariates introduces modeling challenges when we extend the model to ultimate. For example, the case reserve is itself a predictive variable. The single period time-step model is not easily combined together across development ages to project an ultimate value. An individual claim may develop to varied potential values in the next step. Using the mean predicted case reserve and using it as a predictor for the next step is inappropriate. This is not an issue with more commonly used actuarial reserving methods because there is an implicit assumption of independence of the development factors and the paid and/or incurred amounts to which they are applied[5]. Using this assumption of independence at an individual claim level is extremely problematic and unrealistic, which is why simulation across alternative paths is necessary. The following example illustrates this concept.
Consider a simple claim development process in which an open claim has three possibilities in the next time-step:
-
the claim will close for nothing (with 1/3 probability)
-
the claim will close, paying out the current case reserve (with 1/3 probability)
-
the reserve will increase by 1, with no payment in the time-step
In this example, a claim currently open, with a case reserve of 1 has an expected value after one time-step also equal to 1 (0*1/3 + 1*1/3 + 2*1/3). If we take this expected value, treat it as a case reserve in the next time-step, and move it forward, it will also have an expected value of 1. Carried forward infinitely, the value is always 1.
But when we consider each of the possible paths that this open claim could take, we see that this approach is incorrect. The expected value one time-step out is indeed 1, but two time-steps out it is (0*4/9 + 1*1/3 + 2*1/9 + 3*1/9) = 8/9. After three time-steps the expected value is 22/27. As the number of time-steps approaches infinity, the expected value of the claim approaches 3/4. This illustrates the problem of using the mean of a probabilistic model as an input in a subsequent model (either a later time-step or another component model).
In order to develop an estimate of ultimate loss from these time-step models with covariates, we need to describe not only the mean result in a time-step for a given claim with its given characteristics, but also the distribution of potential results in that time-step for that claim. With the introduction of various component models, as discussed below, this becomes even more important.
Possible approaches to projecting results for individual claims over multiple time-steps (and combining together the component models discussed below) include formulaic or numerical integration and stochastic simulation. With the level of complexity involved, and with flexibility of model choices regarding characterization of the distributions of the component models (and to a certain extent the component models themselves), this paper will concentrate on the simulation approach.
Simulation practicalities suggest a need for modeling specific facets of claim development. When considering payment amounts and changes in case reserves, there are probability masses at zero (i.e., no payment and/or no change in the reserve). Instead of trying to incorporate these probability masses in the distribution of results, it is helpful to break the development process down into components which are modeled at each time-step for each open claim within the simulation. Examples of these components are whether a claim closes, whether the value of a claim changes, whether there is an incremental payment, how much is the change in the value of a claim given that one occurs, and how much is the payment given that one occurs. The process is to model these behaviors individually and sequentially for each open claim at each time-step and simulate them accordingly[6].
Thus, the initial task on the path to building a comprehensive model of claim-level development is to build time-step models of each of these development components. In addition to highlighting differences between claim-types, this yields insight into changes occurring within the development process and their impacts on the needed reserve.
A specific model framework is provided here as an example. This is by no means the only approach that could be taken. By showing a specific example, we illustrate how to overcome some particular challenges.
Claim Development Models:
-
Closure Probability
-
Change Probability
-
Payment Probability
-
Change Amount (Large)
-
Change Amount (Small)
-
Reopen Probability
-
Reopen Amount
-
Recovery Probability
-
Recovery Amount
Before discussing each of these models individually, we first define some terms that will be used across the different models.
5.1.1. Definitions (for a given claim at a given time-step)
Beginning Case Reserve –case reserve at the beginning of the time-step
Ending Case Reserve – case reserve at the end of the time-step
Paid Loss – incremental paid loss amount within the time-step
Previous Paid to Date – total of all paid Loss for previous time-steps
Ending Value – Ending Case Reserve + Paid Loss. This represents an amount that is comparable to the Beginning Case Reserve.
“Loss” here is used generically to mean indemnity, expense, medical payment, or any combination of these[7].
General Variables included in each model
Beginning Case Reserve
Development Age
Transaction Date
Accident Period
Claim Characteristics
Exposure Characteristics
Previous Payments
Development Age, Transaction Date, and Accident Period are redundant within two time dimensions. It is useful to consider each of them when constructing a component model because they each represent different things, but in a final version of any component model, it is advisable to include at most two of these variables to avoid model instability and complexity. Parameters for Transaction Date can reflect systematic changes that have occurred, but care will need to be taken to consider the prospective outlook, which may differ from the past. Accident period parameters can also be predictive, but often indicate changes in characteristics that have not been identified. Where possible, it is optimal to find and include such characteristics directly. Care should be taken to avoid using accident period as a proxy for development age (since the more recent periods will contain only immature development ages). In such cases development age should be used in place of accident period to avoid projecting development for immature accident periods that is characteristic of early development as they progress into later development periods.
5.1.2. Potential Models to be Employed in a Time-Step Model
The following are examples of component models which can be used in the development of a time-step modeling process.
5.1.2.1. Closure Probability Model
This model estimates the probability that a given claim will close within the time-step.
Definition: P(Ending Case Reserve = 0 | Beginning Case Reserve > 0 or Reopened = True)
We are defining a claim as being open by considering the case reserve. When the case reserve is larger than zero, the claim is considered open. Using the case reserve as the indicator avoids potential issues with inconsistent coding of claim status over time or timing discrepancies between status changes and case reserve changes. There are sometimes notices of claims, particularly in claims made lines, that may be then considered open but have no case reserves. Consider using a notional case reserve of some small amount to identify such claims for actuarial modeling purposes if this approach to defining claim status is used.
5.1.2.2. Change Probability Model (for claims remaining open)
This model estimates the probability that a claim will change in value during the time-step.
There is a possibility that in a time-step there may be no change in value. When projecting losses forward, reflecting this probability mass is more realistic than simply modeling the change in values broadly.
The probability of claim changing in value is typically very high for a claim that is in the process of closing. Including a variable that indicates whether the claim closes in the quarter would capture this, but it is likely that there would be numerous interaction effects between this variable and the others. For that reason, we have separated this model into one that considers only those claims that are remaining open vs. those that are closing.
Definition: P(Ending Value ≠Beginning Case Reserve | Beginning Case Reserve > 0 and Ending Case Reserve > 0)
Note that we are excluding claims that have zero case reserve at the beginning of the time-step. Changes in values of these claims is contemplated by the reopen probability and reopen amount models.
Also note that the very definition of this model depends on what is considered the result of one of the other component models (the closure probability model). This dependency will be important to consider when it comes time to simulate development.
5.1.2.3. Change Probability Model (for closing claims)
This models the probability that a claim which is closing will change in value.
Definition: P(Ending Value ≠Beginning Case Reserve | Beginning Case Reserve > 0 and Ending Case Reserve = 0)
Often this probability is very close to 1. For many cases quantifying this probability across all claims may be sufficient, with no additional differentiation provided by predictive variables.
5.1.2.4. Reopen Probability Model
This model is for the possibility that a given claim, closed at the beginning of the timestep, will have additional payments during or case reserve at the end of the time-step. This also includes payments on claims technically not reopened, but where additional payments occur after the case reserve goes to zero.
Definition: P(Ending Value > 0 | Beginning Case Reserve = 0)
The number of time periods that the claim has been closed is a key predictor, with additional payments often occurring in the period immediately following claim closure.
5.1.2.5. Reopen Amount Model
Given that a claim which was closed at the beginning of the time-step has additional (positive) payments or case reserves in the time-step, what is the amount?
Definition: E(Ending Value | Beginning Case Reserve = 0 and Ending Value > 0)
In this approach, the ending value, i.e., the ending case reserve amount plus the incremental payment, is used as the target variable of the model. The portion of this value that is paid out vs. that that remains as case reserves at the end of the time-step will be covered in the partial payment model.
5.1.2.6. Change Amount Model(s)
This model defines the changes in value of a claim that is open at the beginning of a time-step, given that it changes.
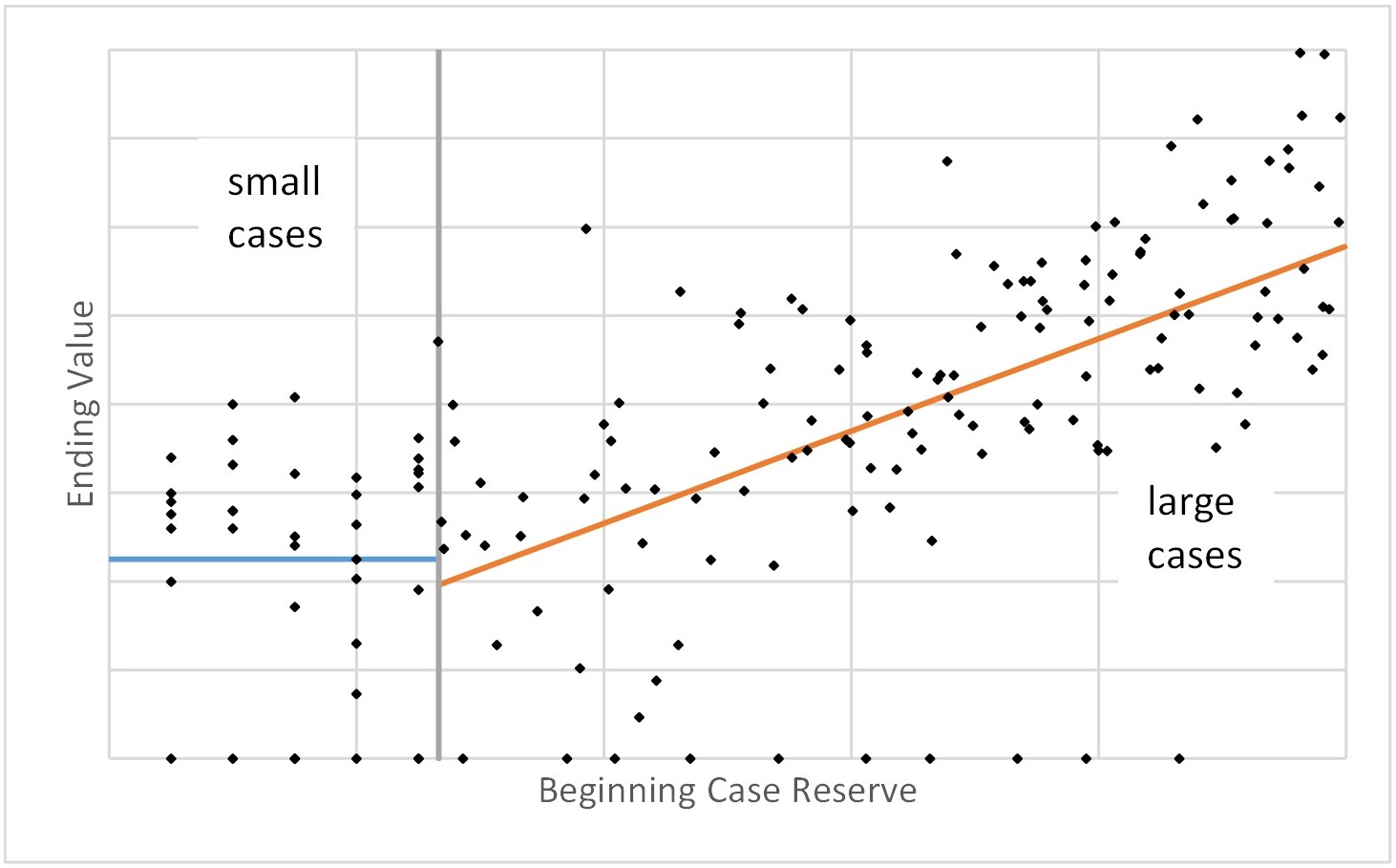
The ending value (incremental payment plus ending reserve) of the claim in the time-step is expected to be strongly related to the case reserve at the beginning of the time-step (i.e., a strong positive correlation between the two), albeit with significant variation. This relationship is far from proportional, however, with small case reserve amounts growing by much larger factors on average than large case reserve amounts. It is easier for a $1000 reserve to grow by a factor of 20 than it is for a $1,000,000 reserve. With a multiplicative factor model framework, the case reserve amount itself will often become the most important predictive variable, and the model can become very sensitive to slight binning changes for small case reserves.
Another issue is that often for very small case reserve amounts, the monotone increasing relationship between the beginning case reserve and the ending value breaks down. Often this is due to the existence of “signal” reserves or other place holders that do not necessarily have a monotone relationship with the ending value. For example, a value of “1” for the beginning reserve may specify a particular type of claim, “2” indicate a different type of claim and there be no expectation that a “2” claim would be double the severity of a “1” claim or even that it would have a higher severity. For this reason, it is often beneficial to use separate models for small case reserve claims and for large case reserve claims.
It is helpful to transform the beginning case reserve itself into an exposure variable more closely related to the ending value, before even considering the impact of other predictive variables. One such “change amount exposure” variable is shown graphically below:

Below the small case cutoff value, there is not an increasing modeled relationship between the beginning case reserve and the expected ending value. Above that value there is a linear, increasing relationship between Beginning Case Reserve and the expected Ending Value. The inclusion of an intercept in the relationship for large cases provides the more significant multiplicative differential between smaller beginning values and the ending value. This avoids the problem of sensitivity to bin determination for the case reserve variable. The parameters defining this transformation are the two linear parameters above the cutoff (two for claims that are closing and two for claims that will remain open), the single parameter below the cutoff, and the cutoff itself (six total parameters). Given a specific cutoff, the linear parameters can be calculated by least squares regression, and the parameter below can be calculated as an average of the ending value below the cutoff. The total least squares across the entire set of observations can be tabulated, and the optimum cutoff value can be determined using numerical minimization of the least squares amount. In some cases, the minimum least-squares amount will be at a cutoff of zero. It is appropriate to limit the other parameters to be non-negative as well, so boundary solutions should be considered.
Preliminary Calculation
Where Ending Value ≠ Beginning Case Reserve, define Change Amount Exposure =
Csmall,0 where Beginning Case Reserve ≤ Small Case Cutoff
Cclose,0 + Cclose,1 * Beginning Case Reserve where Beginning Case Reserve > Small Case Cutoff and Ending Case Reserve = 0
Copen,0 + Copen,1 * Beginning Case Reserve where Beginning Case Reserve > Small Case Cutoff and Ending Case Reserve > 0
with Csmall,0,Cclose,0, Cclose,1, Copen,0, Copen,1 and Small Case Cutoff estimated by minimizing least squares on the training data with Ending Value as the target variable.
Change Amount Model (small case reserve)
This model covers the cases where there is not a generally increasing relationship between beginning case reserves and ending value in the time-step.
Definition: E(Ending Value | Ending Value ≠ Beginning Case Reserve and Beginning Case Reserve > 0 and Beginning Case Reserve ≤ Small Case Cutoff)
The binned case reserve can be used as a categorical variable in this model (together with the other variables being considered). If there are specific signal reserve values, they can be set as distinct bins. A more sophisticated model would be to build models of changes of state from one claim type to another, within the different types of signal reserves if it is common for claims to transition from one type to another before transitioning to an actual case reserve reflective of the expected loss payment amount.
Change Amount (large case reserve)
This model reflects changes in value for claims with beginning case reserve larger than the cutoff value.
Definition: E(Ending Value | Ending Value ≠ Beginning Case Reserve and Beginning Case Reserve > Small Case Cutoff)
Using the Change Amount Exposure variable discussed above, a multiplicative model can be used by setting the expected ending value of the claim equal to a base factor multiplied by the change amount exposure variable, multiplied by modifiers for each of the other variables being considered. The Change Amount Exposure variable may also be binned and treated as a categorical variable to capture possible imperfections in the simple linear relationship used to create the exposure variable.
5.1.2.7. Payment Probability Model
This model describes the probability that there is a payment on a claim for which one is possible.
Definition: P(Paid Loss > 0 | Ending Value > 0)
Notice that the way we have defined the “Ending Value” variable handles all the possibilities for payment since payment itself is included within the ending value (if paid loss is > 0 then ending value must also be > 0). It may seem circuitous to construct the model in this way, but it is helpful to have a single model (the change value model) that governs both the incremental payments and ending case reserve generally, and then we consider a potential payment that is bounded between 0 and the ending value.
An important variable to include in this model is whether the claim closes in the period. As such, this model will be dependent on the closure probability model when projecting forward.
5.1.2.8. Partial Payment Amount Model
In the case where a payment occurs in the time-step and the claim closes, the payment amount is equal to the ending value variable. In cases where there is a payment made but the claim remains open (i.e., ending case reserve > 0) we need to know how much of the ending value is in the form of a payment and how much remains as case reserves. This partial payment model describes that relationship.
Definition: E(Paid Loss | Ending Case Reserve > 0 and Paid Loss > 0)
The Ending Value variable is important for this model, giving an upper bound for the payment amount.
5.1.2.9. Recovery Probability Model
What is the probability that a claim with previous payments will receive a recovery (i.e., negative payment) of some amount within a given time-step?
5.1.2.10. Recovery Amount Model
Given that there is a recovery in a time-step, what is the amount?
5.1.2.11. Dynamic Variable Model(s)
Variables that change over time (dynamic variables) pose additional challenges, just as they do when used for segmentation of triangles in a traditional analysis. Often such variables are predictive for future claim behavior but in order to be incorporated, their ability to change must itself be modeled.
Consider a “pension indicator” variable that indicates a workers compensation claimant is receiving permanent indemnity payments. That determination may change several development periods after the initial determination is made. If segmentation of reserving triangles uses this indicator, history changes if only the current state of the claim is used in the segmentation.
A similar issue exists in the claim life cycle model approach. Training a model using the current value of a dynamic variable for observations before it took its current value represents a model “cheat” and is not appropriate. The value of that variable that existed as of the observation should be used. This is directly analogous to the triangle segmentation problem described above. If the variable is to be used as a predictor, then it also becomes necessary to model and simulate changes in that variable.
An example of one of these state change models is for a dynamic variable that takes values A, B, C, and D. Four separate predictive models could be created:
-
What is the probability that there is a new value?
-
What is the probability that the value becomes A given that there is a change?
-
What is the probability that the value becomes B given that there is a change, and it doesn’t become A?
-
What is the probability that the value becomes C given that there is a change, and it doesn’t become A or B?
There is no need for an additional model for the probability of becoming D since the other models fully describe this situation. The value of the variable at the beginning of the time-step is typically an important variable. Each of the other predictive variables should be considered as possible predictors.
5.1.3. Claim Development Simulation
Each currently open claim is simulated forward one time-step using each of the Claim Development Predictive Models over a specified number of paths. Those paths still open are simulated forward another time-step. This process is continued until all claim paths are closed.


Additionally, claim re-openings are simulated and projected until they are re-closed, both for currently closed claims, as well as for currently open claims that close.
Before time-step 1:
-
Generate a number of paths for each open claim
-
Simulate reopening from current inventory of closed claims, schedule them for reopening in later time-steps, and assign a path number
-
Simulate Ending Value for each of the reopened claims in the time-step in which reopened
In each time-step, for each claim-path combination:
-
Increment development age
-
Simulate changes in dynamic variables (other than the case reserve)
-
Select which of the claim-paths close
-
Select which of the claim-paths change in value
-
Select which of the claim-paths have a payment
-
Simulate Change Amount Exposure for each claim-path
-
Simulate Ending Value for claim-paths with Beginning Case Reserve > Small Case Cutoff
-
Simulate Ending Value for claim-paths with Beginning Case Reserve <= Small Case Cutoff
-
Set Ending Value = Beginning Case Reserve for claim-paths that do not change in value
-
Simulate Paid Loss on (0, Ending Value] for those claims having a payment
-
Set Ending Case Reserve = Ending Value – Paid Loss
-
Select which closed paths will reopen later, and schedule them
-
Simulate Ending Value for each of the claims to be reopened
-
Repeat the process until Ending Case Reserve is zero for all claim-paths
Notes on Simulation
Random selections for binary models (such as Closure) are based on calculating the probability from the appropriate predictive model (using predictive characteristics) and simulating a Bernoulli.
The simulations for continuous variables (such as Ending Value, Paid Loss, etc.) are more challenging. Distributional forms can be used, but they are likely to be naïve with regard to distributional differences across variables. It is not the exception, but rather the norm, that the variance to mean as well as relationships for higher moments are inconsistent across the data. This problem becomes more problematic for this simulation due to its chained nature across time. The simulated outputs from the first time-step are the inputs into the second time-step, the second into the third, and so on. Simplifying assumptions that may be reasonable in a single time-step may distort into unrealistic projections when compounded. The case reserve itself is typically one of the more important variables predictive of changes, with small reserves able to grow by a large factor, and large reserves unable to grow by large factors. Imposition of limits, actual or practical, can also keep simulations from developing out of control.
One approach to reflecting nuances not necessarily reflected in a single distributional form is to use bootstrapping techniques to simulate. In this way, differences in variability and higher moments across different categories of claims can be reflected. With many variables, it is unlikely that there will be sufficient observations of each combination of variables to represent the potential variability for any given risk, but by dissembling error terms across variables, randomly sorting, and then recombining them, a more nuanced reflection of variability can be achieved. By sampling residuals from the test data instead of training data, model and parameter risk are contemplated. The approach is highlighted in the following steps:
-
Apply the predictive model to the records in the test data
-
Calculate the residual for each test data record
-
Allocate/disaggregate the residuals to each of the various predictive characteristics for each record (we will discuss this step in greater detail below)
-
For a given claim-path-timestep to be simulated, randomly select one disaggregated residual for each predictive characteristic, from among the set of matching characteristics from the test data
-
Combine the residuals for the claim-path-timestep to a single residual
-
Combine the modeled residual and the expected result to give a simulated value
-
Apply limits or other constraints
-
Rescale the mean and variance across paths if necessary
The disaggregation of test data residuals across predictive characteristics is what allows this approach to generate variability patterns that are like what has been observed for similar claims in the past, while still allowing for combinations of characteristics that have not been observed. With skewed, positive distributions, it is helpful to use multiplicative residuals rather than additive residuals.
The example below illustrates the concept of this type of bootstrapping with two predictive characteristics, State and Class. The concept is generalizable for more variables.


The square roots in the last two columns of the above table are in recognition of the reshuffling of residuals across characteristics that will occur in the simulation. If columns I and J were used directly without the square root, resulting variability would be too low, because the correlation between the disaggregated residuals at the record that exists with the observed residuals is eliminated when the simulation draws are performed independently across the characteristics.
Note that in the above approach, more of each observed residual is assigned to the variable with the stronger predictive effect. The predictive factors in this example are normalized to 1, so a factor close to 1 is an indicator that the characteristic value does not describe much of the difference in the target of prediction. The embedded assumption in assigning the residuals in this way is that the stronger the factor (further from 1) the more of the residual is assigned to that variable.
The table below shows a couple of simulated results using the approach.

The date of the transaction (calendar period) may be one of the predictive variables in one or more of the component development models used in the simulation. Often this will describe changes in claim handling and the underlying claims environment. The actuary should take care when considering the appropriate factor to use in simulation as the future dates do not have an explicit factor. One logical option is to use the most recent observation. Another may be to use the long-term average. The impact of such a choice can be quantified by comparing alternative simulations varying the assumption.
5.2. Unreported Claims - Component Emergence Models and Simulation

Earlier sections focused on the development of known claims. We must also estimate of the ultimate cost associated with unreported claims.
Not having been reported, the potential for these claims is driven not by claim characteristics (which do not yet exist) but only by exposure (i.e., policy) characteristics. To simulate claims with specific characteristics detailed models to predict the characteristics are necessary. It is easier to simulate the ultimate values of the IBNR claims directly, rendering the claim characteristics unnecessary. Since the ultimate value is being directly simulated, the timing of payments is not simulated. The simplification of the simulation process by concentrating on ultimate payment amount is dramatic, however. Timing of payments on IBNR claims (including their impact on inflation effects) may be modeled separately if this is an important desired output.
5.2.1. Component Emergence Models
Describing the simpler approach, there are three basic component models required to predict the unreported claims – report lag, frequency, and severity. For each of these, we will focus on claims that have a non-zero ultimate value.
5.2.1.1. Premium Model
Premium is a natural starting point for modeling frequency and severity. In traditional triangle reserving approaches, Bornhuetter-Ferguson analyses use premium as an input, but it is important to ask what premium should be used. Collected premium can introduce inconsistencies due to differing levels of rate adequacy. These inconsistencies will distort the results. Premium at a consistent rate level across all policies is ideal. Neutralizing changes in rates charged is useful. (Bodoff 2009). This is also true for detailed reserve modeling.
While companies often have processes to measure changes in rates over time, these measures often are problematic. One approach is to compare historically-rated and re-rated premium by policy. This method breaks down when discretionary pricing factors such as schedule mods are significant. To overcome this challenge, the premium charged for each expiring and renewing policy is compared, which considers impacts like changing schedule mods. New and non-renewing business is ignored. If either of these ignored cohorts were written at a different rate than the renewing book, the impact to the rate level is not captured. Sometimes average rates or average mods over time including new and renewal accounts are considered, but these measures assume that the mix of business has remained constant, which is rarely the case.
A predictive model can be used to simultaneously incorporate all these considerations to measure changes in premium rate level over time. The target of the prediction is the premium itself. The predictive variables are the rating and underwriting characteristics, such as class, geography, deductible, limit, new vs. renewal, etc. The policy effective date is a key predictor indicating rate changes over time, adjusting for changes in mix. Interaction effects should be considered between the policy effective date variable and other variables as it may indicate targeted pricing actions.
Since the parameters for policy effective date provide a rate change across time, adjusting for other variables, the resulting policy effective date curve represents a vector of rate adjustment factors that can be used to restate historical premium to a common level. If interaction effects were found between effective date and other variables these adjustments should be included in the on-leveling.
This on-level premium, which we will call the “Reference Rate” is useful as a starting point for predicting claim frequency and severity. It is a modeled premium that is normalized for changes in rate over time and reflective of statistically significant impact of key rating variables. Note that this premium is not necessarily actuarially sound but is stated at a consistent (or benchmark) level of adequacy for all policies within the book being analyzed and reflective of policy characteristics. As such, this Reference Rate premium is an appropriate base for frequency and severity analyses because it removes distortions arising from differences in rate adequacy over time and across accounts.
In addition to the Reference Rate premium, we can calculate the ratio of Written Premium to Reference Rate premium at the policy level. This can be included as a separate predictive variable in the models. This ratio may be impacted purely by market forces (in which case it is unlikely to be predictive of frequency or severity) or it could be indicative of differences in the perceived risks of the policies not captured by the other fields included in the analysis (in which it could be predictive). Including it as an additional predictive characteristic will help make the determination.
The modeled premium as well as the ratio of written premium to reference rate are being discussed in this section due to their high importance for modeling frequency and severity. These characteristics are also potentially useful for the other models previously discussed. It is beneficial to run the premium model before running these other models so that these two new variables can be included as predictors.
5.2.1.2. Report Lag Model
We define the report lag as the time difference between the incurred date and the date reported.
One problem with modeling the reporting lag across policy characteristics is that we have incomplete data that we would like to incorporate. Average observed lags are conditional on the claim already having been reported. Our true target is the unconditional report lag, i.e., the average lag after all claims have been reported.
One way to approach this is by adjusting the observed lag for each claim to try to remove the bias given that it is conditional on the age of the policy. This adjusted observed lag for each claim can then be used as the target of prediction in our model, allowing us to model differences across predictors. First, we calculate an expected lag L on non-zero lagged claims across the portfolio by starting with the observed average and


Where Report Lag > 0, iterating until L converges. Claim Age is calculated based on the ‘as of’ date of the analysis.
A value of cdfj is determined for each claim, equal to the observed percentage of claims reported by the same lag or earlier as the claim in question, excluding from the calculation any claims that are older at the valuation date than the claim in question. For example, if a claim were reported 25 days after the incurred date, and the claim is now 190 days after the report date, cdf for that claim would be the percent of those claims that were reported within 25 days within the population of claims that were incurred and reported within 190 days.
lagVariable (the target of prediction) for the claim is then set as:
lagVariable = - L * log(1-cdf where Rj > 0 and the simulated ultimate > 0
lagVariable = 0 where Rj = 0 and the simulated ultimate > 0
lagVariable = NULL where simulated ultimate = 0 (claims with ultimate=0 are excluded from the report lag model)
5.2.1.3. Frequency Model
Observed claim frequency is dependent on the maturity of the policy, due to the lag between incurred date and report date. Therefore, reporting lag should be modeled first, and the measures of claim frequency can be relative to a premium that has been adjusted to reflect the maturity of the policy due to this reporting lag as well as for any unearned portion of the policy.
In addition to adjusting for earning and report maturity, using premium that adjusts for rate level changes such as by using the Reference Rate premium described earlier avoids problems with differing rate adequacy.
The target of prediction is the observed non-zero claims count for each policy. For the closed claims, this is trivial, but for the open claims the author suggests selecting one single path at random from the claim development simulation to determine whether each claim is non-zero for purposes of supplying this target.
In addition to policy fields of interest, the effective date of the policy should be included as a potential predictive variable to measure frequency trend. In the case where premium is not adjusted to a constant rate level, the effective date variable will also reflect differences in rate.
5.2.1.4. Severity Model
For modeling claim severity differences across policy characteristics, we are interested in ultimate claim severity. Case-incurred losses include whatever distortions exist in the case reserves. One solution to this problem is to use closed claims only when building a severity model. Unfortunately, this introduces bias due to differences between open and closed claims. One approach to removing open/closed bias could be to include closed claims only from periods that are essentially fully developed, but this will exclude valuable information about more recent claims. When trend is present or where the underlying claim severity environment is otherwise changing, this loss of recent information is problematic. Instead, by first developing the known claims to an ultimate level, before modeling differences in claim severity, we can include the open claims – eliminating the open/closed bias, but without the distortions caused by case reserves developing differently across different types of claims.
Using the mean projection of non-zero ultimate payments for a claim on those claims that are currently open will tend to underrepresent the variability of the ultimate claim value. This can be problematic when being used in predictive models, particularly when testing alternative models against each other, but also simply for characterization of the variability of severity generally. For this reason, it is useful to select the same simulated path for each open claim that was used in determining non-zero claim count and including only those selected claims that develop to a non-zero value for the severity analysis.
The relationship between report lag and loss severity is typically strong, and generally the difference between the incurred date and the reported date should be included as a potential predictor.
As with claim frequency, the policy effective date is a potential predictor, representing severity trend.
Modeling claim severity is one of the more challenging aspects of predictive modeling owing to severity’s high skewness. For smaller sections of the portfolio of observations the lack or inclusion of a single large observation can make a significant difference in the measurement of severity. Adding a credibility component to the modeling process will help avoid being too sensitive to the observed data. However, when observations cannot be completely relied upon it puts higher importance on the complement of credibility. Even if credibility adjustment is not made other than as a binary choice of whether a parameter is “in” or “out,” the complement of credibility is important. A common assumption is that if a statistically significant difference is not found, none exists. This is a dangerous assumption, particularly for small segments of the data. For example, consider a workers compensation insurer that writes mostly low-hazard accounts. The few high-hazard accounts likely have had few claims given their low-frequency nature. It is likely that there is little or no statistically reliable difference between the severity that has been observed between the high-hazard and low-hazard accounts. It would be a mistake to say that these two groups of accounts have the same severity. The insurance marketplace as well as the rates being used at an insurer (often reflective of broader experience, such as a me-too filing or bureau rating) includes important implicit information about severity potential. Frequency modeling is far more robust than severity, and the ratio of premium to modeled frequency works well as an exposure variable, being an a priori indicator of severity potential. If statistically significant differences are not found relative to this expected severity, the market or rate plan wisdom simply remains unaltered. Said differently expected loss ratio is more likely to be consistent across risks than severity.
To generalize on this concept, we can determine this “expected severity” exposure variable to be equal to the prediction from a linear regression of non-zero ultimate claim amount to the ratio of Reference Rate premium to modeled frequency (at the claim level). In this way the hypothetical relationship between premium, frequency, and severity can be broadly tested rather than assumed. If the slope parameter is not statistically significant the a priori opinion for the covariate model is “no difference in severity.” If the constant parameter is negative or statistically insignificant it can be left out and the a priori opinion is “severity strictly inverse to frequency.” With both parameters present, there is an inverse relationship between frequency and severity, but flatter.
5.3. Unreported Claim Simulation

The simulation process for the unknown claims is as follows:
-
Each policy that still has potential for claims is assigned a policy maturity factor based on its modeled report lag and the portion of the policy period that has been earned. Expected unknown claims are calculated as the premium multiplied by (unity minus the maturity factor), and then applying the frequency model to this amount based on account characteristics.
-
Individual claims occurrences are then simulated for each policy with a mean equal to this number of expected unknown claims. Paths are assigned randomly.
-
Date of Loss and Report lag are simulated for each of the emergence claims according to the report lag model (Date of Loss is necessary to generate incurred period statistics).
-
Ultimate severity is simulated for each of the emergence claims according to the severity model.

After simulating emergence, a view such as the following can be constructed.

This report can be directly compared to what is produced using a traditional triangle analysis, with greater detail owing to the specifics observed during simulation.
6.0. Alternative Data Elements and Triangle Specification
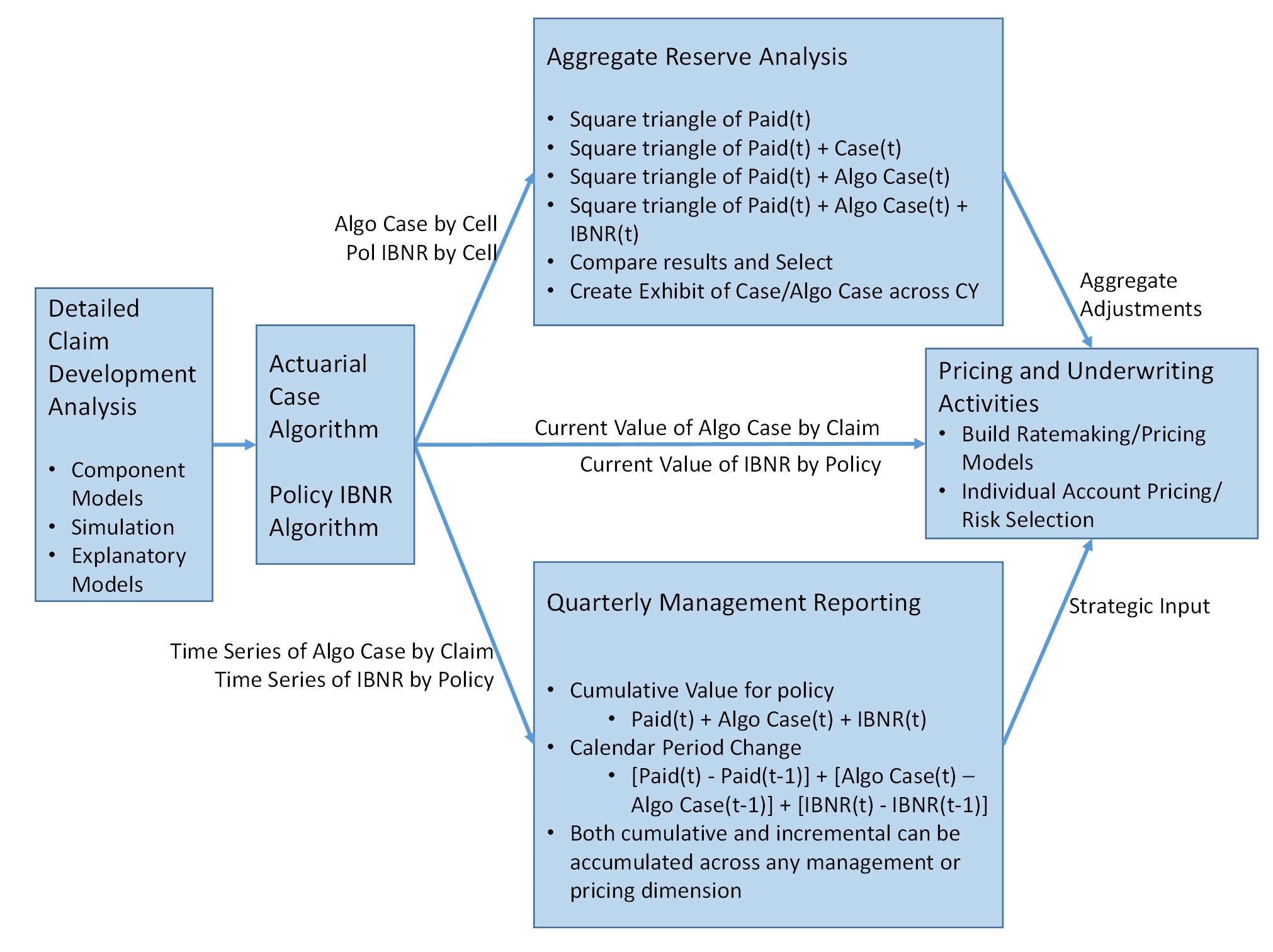
This section will discuss the creation of Actuarial Case Reserves (for reported claims) and Actuarial Policy Reserves (for unreported claims) based on the observed history of closed claims, supplemented with the simulated projections. The benefits of creating these new data elements are significant across actuarial practice and insurance company management.
6.1. Building and using an Actuarial Case Reserve Algorithm
One benefit of using the time-step component models and simulating individual claims to ultimate is that additional insight into the claim life cycle is gained. Differences in settlement rates of claims across predictive variables, volatility differences, etc. are revealed. Changes in claim management practices over time are more easily characterized and identified by the actuary. On the negative side, the simulation process to bring all the component models together and project over multiple time-steps can be challenging to audit due to its inherent complexity and can be time-consuming. One approach to summarizing the combined result of the component development models and the resulting simulation to ultimate is to create an Actuarial Case Reserve Algorithm.

The motivation for the creation of Actuarial Case Reserves goes beyond that of summarizing and validating the results of a Claim Life Cycle Model. It has the potential to solve many of the actuarial problems with the use of case reserves themselves. Case reserves can provide useful information to the actuary about a large portion of the total reserve need. However, changes in how case reserves are established and revised cause significant problems for traditional triangle analysis. This leads actuaries to often put pressure on claims departments to set case reserves consistently. Since the amount of the case reserve can be an important consideration in the handling of the claim, this pressure can lead to sub-optimal decision making and results at the claim level. Because case reserves are rarely established on a true expected value basis, changes in claim settlement rates are also problematic for triangle analysis. This also leads to pressure from actuarial departments to the claim department to maintain the status quo, potentially leading to sub-optimal economic results as well.
Changes in case adequacy and claim settlement rates are commonly dealt with by actuaries by using Berquist-Sherman techniques to adjust for these changes (Friedland 2010, ch13). Unfortunately, these adjustments may be inappropriate when applied injudiciously. Consider the hypothetical scenario of a company that with struggling financial results, begins to write higher severity classes of business. Lacking experience in those classes, and desperate for premium, the company underprices the new policies. When loss ratios begin to develop upward, the actuaries, under pressure to reduce reserve estimates, note that the average case reserve amount is higher than in the past. Adjusting historical case reserves to the current level using a Berquist-Sherman adjustment, historical development is reduced, as are the reserve estimate and apparent loss ratios. The company continues to write the policies at an unprofitable level and a large reserve deficiency continues to grow. The problem is not with the Berquist-Sherman technique itself, but rather that it was inappropriate to use it in this situation because the increase in case reserves was not due to an increase in case adequacy, but to a changing mix of business. Detection of such changes is difficult when only aggregated triangle data is considered, particularly given the wide range of variables that could be shifting (industry classification, geography, deductible, limit, etc.)
The unreliability of subjectively determined case reserves has led some to conclude that case-incurred loss development should be relied on less than paid loss development when estimating total reserves (Zehnwirth 1994). Taken to an extreme, an actuary may conclude that the case-incurred triangle is completely inappropriate to use. However, information is lost by excluding the case reserves. Ignoring the information contained in case reserves by the actuary is usually imprudent. Consider a small insurer that has seen an abnormally large number of full limits losses. Estimating a total reserve need that is based only on paid losses observed to date and ignoring the case reserves would be inappropriate. Even for a large insurer that may be able to rely on paid information only to establish a reserve estimate, the need for information at more granular levels for internal and external reporting purposes suggests that case reserves are not easily ignored. Also, changes in closure rates over time such as those observed during and after the Covid-19 pandemic are particularly distortive to paid loss triangles.
Rather than ignoring or discounting the information contained in booked case reserves due to their subjective unreliability, an approach that uses the objective information about open claims in a reserve analysis avoids many of the problems with traditional adjuster case reserves, while providing information to the actuary about the payment potential of the currently open claims.
The approach involves the following steps:
-
Determine, for every point in time that every claim was open, what the hindsight case reserve should have been (based on observed results for closed claims and simulated results for open claims).
-
Build a predictive model targeting this hindsight value, using objective, consistent claim characteristics as predictors.
-
Apply this Actuarial Case Algorithm retrospectively to every open claim for each triangle cell that the claim was open. (This can be done prospectively to new data as well)
-
Replace the adjuster case reserves in the case-incurred triangle with the actuarial case reserve.
-
Develop the triangle as usual.
6.1.1. Organization of the Model
Each claim that was open at any of the triangle evaluation points (observation dates) has records included in the table for each such date. Fields that were included as predictive in the various component development models are good candidates to include in the case reserve algorithm as predictors, excluding the claim department case reserve (which will be discussed below).
Even though this model is summarizing and simplifying an existing process, it still is appropriate to aim for a parsimonious model and to separate the data into training and test, etc. One benefit of holding out data is that when it comes time to demonstrate the effectiveness of the model to others (section 6.1.4), illustrating the development on test data triangles is very powerful for demonstrating its veracity.
The target variable for this model is the sum of payments after the observation date. This includes payments that have already been made as of the date of the analysis as well as simulated payments following that date (B+C in the timeline below). To maintain consistency between the history and the projections (i.e., same variability), use the results from a single simulated path for each claim rather than the mean for determining the ultimate value. All training claims that are open as of each observation point should be included, even those that ultimately close without payment since this information is not yet known when the claim is open.
A Specific Simulated Path (payments) for a Selected Claim:

Some of the fields that are likely to be of predictive value are:
-
The age of development
-
Prior paid amounts (often useful to separate these into recent payments and older payments as well as indemnity, expense, etc.)
-
The claim limit remaining
-
Cause of loss
-
Injury type
-
Geographical area
-
Business/Industry classification
-
Information about the claimant
-
Claim Severity Classification
-
The accident period (trend)
Note that it is acceptable to use dynamic variables (those that change over time) in a case algorithm model (e.g., severity classification, litigation status, etc.) Care should be taken to ensure that the values of these dynamic variables are the values as of the time of the prediction, not as of the most recent valuation. Otherwise, significant distortions can result, as in any predictive model when future-valued predictive variables are inadvertently used.
One goal of the actuarial case reserves is to avoid the impact of changing case reserve adequacy over time. Adjuster reserves that are subjectively determined may include valuable information that is not available in coded fields, but they introduce the potential for adequacy changes. By constructing an algorithm that does not depend on adjuster reserves, we avoid this problem. While the adjuster case reserves provide important information about future payments in the modeling-simulation part of the claim life cycle model, we seek to use that information, and then condense and assign that knowledge back to objective, consistent, predictive fields. That means eliminating the claim department case reserves from the actuarial case reserve algorithm.
The observation date is a possible predictive variable, but care needs to be taken when using it. It can be a powerful way to measure and incorporate the impacts of loss cost trend, but its use can be counter to the goal of consistency over time, if not used carefully. There is predictive value in the date because of loss trend. This can be thought of as a generalization of the Berquist-Sherman technique in that the actuarial case reserves are systematically adjusted to reflect systematic differences over time. If the date is used as a predictive variable with no constraints put upon it, though, it is quite likely that the parameter will fluctuate from period to period. We seek to isolate the impact of the date after adjusting for mix shifts in the other variables being used, but additional non-included variables may be proxied. Also, development age and observation date are related, and although a multivariate model attempts to isolate their relative importance, it is easy for development age impacts to bleed into the date variable if it is unconstrained (date becoming a proxy for development age). If care is not taken to constrain the date parameter, and then it is applied to generate the algorithmic case reserves, the effect would be to reintroduce some of the biases that the model is working to eliminate.
To keep the observation date from having this effect, simple constraints can be put on the calculation of the date parameter. For instance, it might be reasonable to assume that trend will impact claim severity in a linear fashion or an exponential fashion (or according to some other rule). There is judgement required by the actuary in deciding what rule will best describe the impact of trend without allowing the actuarial case reserves developed from it to fluctuate haphazardly, contrary to the goal of consistency of the algorithm over time.
6.1.2. Applying the Actuarial Case Algorithm
Once the Actuarial Case Algorithm has been constructed, it is straightforward to apply it to all of the open claims at each point in the loss history, and then to proceed as normal with triangle analysis.

While it is tempting to build the triangle directly from the detailed development data, there are often individual discrepancies in the data due to mismatches between the loss and exposure data or claims that do not lend themselves, for whatever reason, to the process (coded through an alternative system, etc.). Rather than deal with such discrepancies, it is more straightforward from an audit perspective to simply provide the adjustments to the claims that can be modified, summarize the modifications by accident period and development age, and modify the triangle accordingly. This will ensure that all claim payments are still captured and that if an alternative case reserve was not possible for some claims, they will at least be included in unadjusted form.
Once developed, an actuarial case reserving algorithm can be easily applied for future analyses provided the predictive variables are available. Triangles can be quickly updated as a new step in the regular reserve analysis process, without re-determination of parameters. Re-parameterization of the parameters can therefore be done less frequently, for example annually instead of quarterly.
After constructing the alternative triangles, actuarial analysis can be completed as usual (LDFs, etc.).
6.1.3. Validation of Results
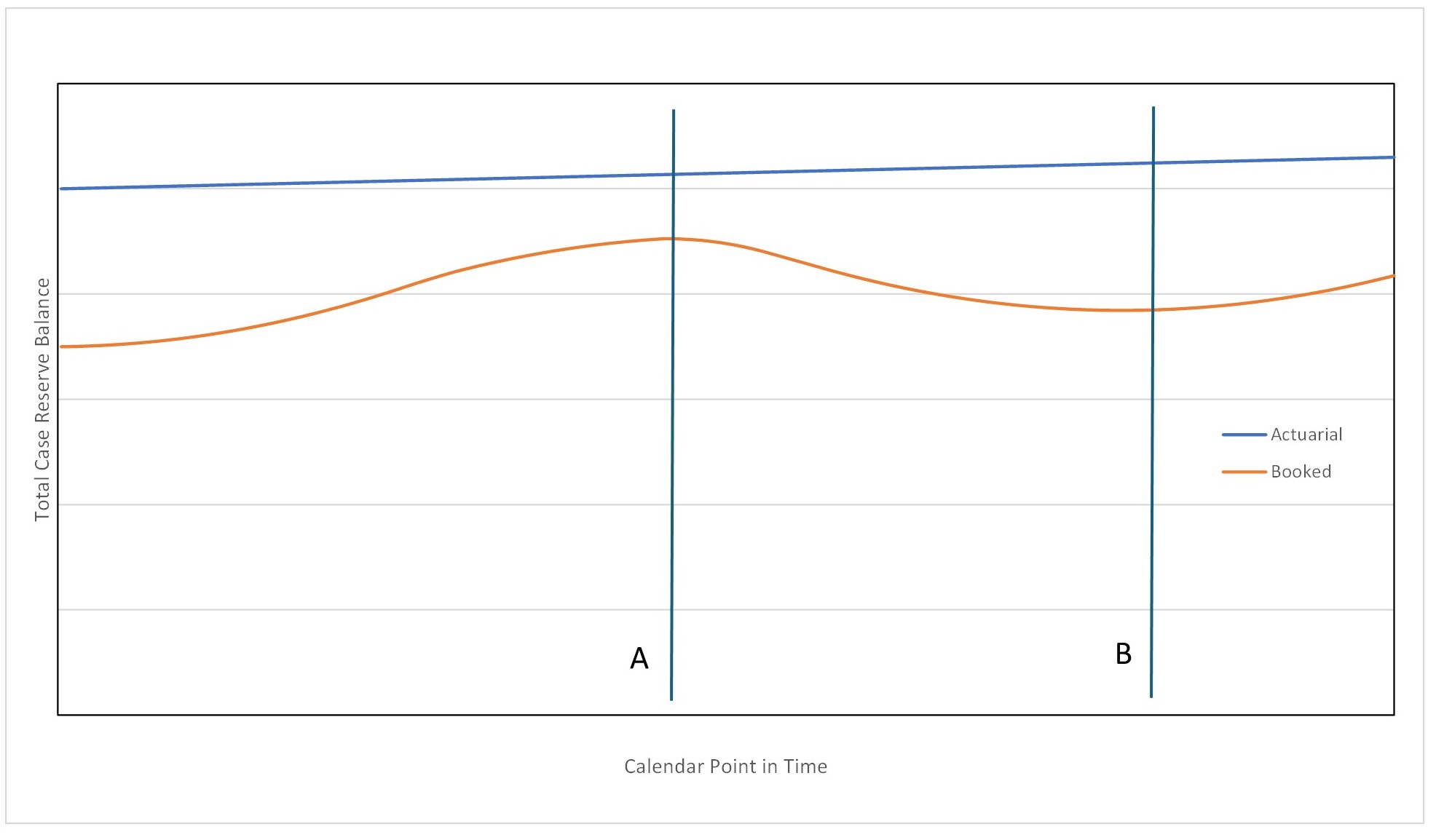
With a case reserving algorithm that is openly and objectively applied to historical points in time in a triangle, and then calculating development factors in the usual way, the efficacy of the case algorithm itself can be justified. Regardless of how the case algorithm was determined, its ability to generate consistent, unbiased aggregate development of reported losses as claims transition from early stages of reporting, through interim payments and into the final settlement of the claims is evidence of the algorithm’s veracity and strength as an actuarial tool. From an audit perspective, the calculation of a case reserve generated from objective claim and policy characteristic is more transparent than a subjective case reserve selected by a claims adjuster. If a report period triangle shows development factors, centered around 1.0, across multiple cuts of the data, evidence of its appropriateness is provided (particularly when using hold-out data, not used to build the algorithm).
6.1.4. Illustrating Changes in Case Reserve Adequacy
With the case algorithm established, it is illustrative to look at the relationship between the actuarial and traditional case reserves. It is likely that there will be a significant difference between the two because 1) the adjuster case reserves are subjective and 2) it is not necessarily the intention of the claim department for the case reserve to be at actuarial expected value. In fact, from a claim management perspective, an actuarially appropriate estimate may very well be less than ideal, because it would incorporate relatively rare extreme events, (e.g., the mean may be at the 70th or 80th percentile of potential outcomes). Setting the case reserve at that level may encourage higher settlements. In many actuarial reserving contexts (e.g., Berquist and Sherman 1977) it is stated that inadequacy or redundancy in booked case reserves is not necessarily problematic in a triangle as long as it remains consistent. Comparing the booked case reserves to the objectively determined actuarial case reserves is a useful approach to identifying and illustrating changes in case adequacy and therefore potential distortion to aggregated triangle data using traditional case reserves. If the relationship between the actuarial and traditional case reserves is consistent across development age, industry class, geographic area, cause of loss, injury type, etc. (unlikely), and if the mix of business across all of these dimensions is constant (also unlikely), then there is little chance that aggregate triangles would be distorted. However, if these conditions don’t exist, such distortions might exist. The comparison helps identify the extent to which this distortion may be important.
Consider the graph below:

The blue line at the top represents the total actuarial case reserves while the orange line represents the total traditional booked case reserves for a book of business over time, displaying a changing level of average case adequacy over time.
A chart of this type helps in discussion with management regarding differences between estimates that are aided by the detailed analysis and estimates derived from unadjusted triangles. Since the actuarial case reserves reflect the mix of claims, it is a more reliable benchmark than simply comparing to a long-term average. Because the actuarial case reserves and booked case reserves both exist at the claim level, similar graphs can also be generated for any subset of the data, revealing additional information.
6.1.5. Case Reserves - Actuarial vs. Claim Department
As the actuaries develop alternative case reserving models, it is tempting to suggest that such models should replace existing case reserves in other contexts, such as by use in the claim department. This temptation should be avoided.
The case reserves that would be ideal for the actuarial department are likely different from the case reserves that would be ideal for the claim department. The actuaries are best served in reserving and pricing by case reserves that are unbiased (i.e., represent expected value) for cohorts of claims and policies along significant characteristics. Referring to mean-valued expectation when settling claims is likely not optimal as described above. The median outcome, with its easily understood evaluation of “just as likely to develop up or down” may be a more appropriate value for claim department use than the mean. At the claim level, the median and mean outcome can be significantly different.
The claim department also has information about the claims that is likely not coded, including significant subjective information. This information is valuable at the individual claim level regarding settlement, but problematic for the actuary due to its potential to change subtly or dramatically over time. Therefore, this information should be included in the claim department’s case reserve estimate but generally not in the actuary’s case reserve estimate.
This bifurcation into two separate estimates allows the claim department to operate more freely to make appropriate claim reserving and settlement decisions without concern that the actuary’s triangles will be impacted in unexpected ways. A common request from the actuary to the claim department is to make no changes. This is unrealistic and suboptimal, as there are often good practical and economic reasons for making changes. Freeing up the claim department to make changes to case reserving that leads to better decision-making is a distinct economic benefit. This also extends to the speed of claim settlement, which also historically has had the potential to distort the actuary’s triangles. If the actuary instead uses an algorithmic case reserve, under her/his control and developed with the goal of being unbiased, a change in the rate of settlement will impact case-incurred development only if it translates into a change in the amount of ultimate payment for the claim. If it does not, payments are exactly offset by a drop in the algorithmic case reserve and development is the same as it would have been if the change in settlement had not occurred.
6.2. Unreported Claim Value Algorithm
Like the use of an actuarially generated case reserving algorithm, actuarial triangle analysis can be further refined by the creation of an unreported claim value algorithm. This algorithm provides the expected value of claims which have not yet been reported for a particular policy as of a particular date.
The Bornhuetter-Ferguson technique (Bornhuetter and Ferguson 1972) can be thought of as a simple case of an unreported claim value algorithm where the loss ratio and development is the same across all exposures of a particular age.
Like the Bornhuetter-Ferguson simple case, we start with premium (collected, or adjusted to be at constant rate level) but allow loss ratio and reporting lag to vary across policies. Also, we use policy written premium rather than earned premium as a starting point. As long as we are concerning ourselves with claims that have not yet been reported, and since we are looking at a policy level, there are advantages to also being able to estimate not only the IBNR claims (Incurred But Not Reported), but also the claims that would normally be associated with the unearned portion. For convenience we will term these WBNI claims (Written But Not Incurred).
Unlike the actuarial case reserve algorithm, it is unnecessary to simulate the emergence claims and model the result of simulation. Instead, the result can be calculated more directly using the emergence component models using the following steps:
-
Apply Premium Model to each policy to arrive at Reference Rate premium
-
Apply Report Lag Model to Policies to get a modeled report lag for each policy
-
Apply Frequency Model to each policy to get a modeled (non-zero) claim count. Exposure is full premium not matured premium
-
Apply Severity Model to each policy
-
Allocate premium, modeled ultimate (modeled frequency * modeled severity), and modeled frequency to accident period for each policy
-
Calculate unreported for each policy, accident period, valuation date combination in the triangle
Each of these steps will be discussed in greater detail.
Applying the Premium Model
If you are starting with an existing Claim Life Cycle Model, this step is already completed, but if you are applying the approach to subsequent points in time without rebuilding the CLCM, the models will have to be applied to refreshed underlying data. The point of this step is to generate the reference rate premium, which will be used as the exposure variable for the frequency model.
Applying the Report Lag Model
The goal of this step is to generate an expected report lag for each policy based on its characteristics. This model will be critical to determining the unreported portion of the ultimate loss at each point in time of interest for each policy.
Applying the Frequency Model
The frequency model that was determined earlier used matured reference rate premium as its exposure, but here it is applied to the full reference rate premium to arrive at an estimated claim count for the policy. The ratio of written premium to reference rate premium may be included if found to be predictive. Policy Effective Date may also be a predictive characteristic. If so, the actuary should take care to consider the treatment of dates that extend beyond the history period.
Applying the Severity Model
The first step is to apply the determined linear relationship between claim severity and reference rate premium divided by claim count at the policy level to provide the a priori expected severity (discussed in section 5.2.1.4) prior to applying the severity model.
Report Lag is likely an important predictive variable in the severity model. If it is, the modeled severity impact from report lag for the policy must be integrated over the distribution of report lag. An exponential assumption for report lag at the policy level simplifies this integration. For example, if the severity model includes report lag as a binned characteristic, each section of the report lag distribution is assigned its respective factor from the corresponding bin, such that an average report lag factor is determined for the policy.
sum [exp(lower bound / modeledLag - exp(upper bound / modeled lag * factor
Where ‘i’ denotes the bin and ‘j’ denotes the policy.
Allocating to Incurred Period
To include this element in an incurred period triangle, we need to allocate the ultimate policy results (expected claim count and expected ultimate – equal to expected claim count multiplied by expected severity) to each period. Using a constant hazard rate over the policy term this is straightforward, but alternatives assumptions could also be made. Allocating the written premium is useful to arrive at an independent earned premium that can be compared to control totals and that exists at the policy level and therefore can be summed to any level of interest. It is also instructive to allocate the reference rate premium so that comparisons of written premium to reference rate premium can be made for the different periods.
Calculating the Unreported Estimate
Each valuation date of interest (for example, quarter-end evaluations) must be determined, and then for every [policy - incurred period - valuation date] combination, an unreported estimate can be determined by integrating the remaining portion of the report lag curve for the policy, incorporating severity differences to the extent that report lag was used as a severity model characteristic. Including the policy effective date as a variable makes it easy to switch from policy period triangles to incurred period triangles.

Since we are focused on only unreported losses in this algorithm, we take steps to avoid a potential problem with the Bornhuetter-Ferguson method which can miss a changing mix of exposures that impacts the reporting pattern or expected loss ratio. Such mix changes are explicitly reflected in these algorithmic policy-level reserves.
Separate from mix changes, the Bornhuetter-Ferguson technique can lead to odd results when significant case savings are reflected in the development pattern by determining future savings by premium volume rather than by case balances themselves. For example, assume that for a given line, case-incurred losses are typically at 120% of ultimate at 24 months and that the a priori loss ratio is 60%. In this example. the Bornhuetter-Ferguson technique projects case savings of 12% of earned premium [0.6*(1.0-1.2)] at 24 months regardless of the case reserves. Even if there are no case reserves from which to have savings, 12% of premium is the projected savings amount. By using an actuarial case algorithm to project future payments on known claims and a separate policy-level IBNR algorithm to project as yet unreported claims, we avoid this problem.
While it is not common for actuaries to think about estimating emergence at a policy level, this procedure, combined with the actuarial case algorithm discussed earlier, can be very powerful to help one examine a book of business. Since estimates of ultimate now exist at a very granular level (policy or even sub-policy), the profitability of any number of slices of the business can be evaluated. With actuarial reserving techniques that are currently in common use, triangles would have to be developed and factors selected along these slices of the business. With indications of profitability at a finer level of detail, the company is able to be much more proactive (defensive or opportunistic) in their underwriting and marketing decisions.
The algorithmic policy level IBNR reserves at specific points in time can be added to the case algorithm adjusted accident period triangle to create a new triangle. The policy level IBNR and WBNI could be added to a policy year triangle that includes case algorithm amounts as well. Both of these triangles, accident year and policy year, can be used to test and illustrate the combination of the case reserve algorithm and the unreported claim value algorithm. Remaining development in both of these triangles should be minimal, illustrating the algorithm’s effectiveness.
6.3. Comparing Reserve Estimates

The reserve estimates generated from simulation and those derived from analysis of alternative triangles (paid + actuarial case reserve, paid + actuarial case reserve + unreported reserve) are likely to differ from those generated from the traditional triangles. The actuary will likely be asked to explain why. Often the answers can be found by considering the problems that the method is trying to solve. For example, case reserve adequacy could be shifting (which can be measured by comparing against actuarial case reserves). There could be a mix shift or a change in settlement. The additional insight into the differences in development obtained by building the component development models (and the explanatory model to be discussed in section 7.2) will help point the way to highlighting these differences. For example, in the case of a mix shift, often by segmenting the traditional triangles along lines indicated by the CLCM approach (with high development segments growing or shrinking) a reserve similar to the one generated by CLCM can be illustrated. Often confirmation bias for existing estimates and methods is high and results will be viewed with skepticism. Providing evidence of the consistency of algorithmic case reserves by showing a report year triangle with test data or a policy year triangle of all data elements on test data can help to gain comfort with the approach. As data continues to emerge methods can be compared to each other regarding their relative strengths, overcoming confirmation bias.
7.0. Other Topics
7.1. Other Modeling Considerations
In actuarial reserve analysis it is common to isolate specific types of payments into separate analysis, such as indemnity payments from expense payments and/or medical payments. In addition to reporting requirements that may require separate estimates, the types of payments typically develop differently, and it often is beneficial to analyze them separately to provide additional insight (Friedland 2010, Ch3).
When building an analysis based on detailed data, this is still the case. In addition to illustrating different loss development patterns, the application of limits can be reflected with greater sophistication if simulation of the future payments is being performed. One of the strategies for using the payment type is to identify the payments with a distinct claim ID (i.e., treat the expense or medical as being a separate claim from the indemnity) with the payment type as just another variable. Scanning for possible interaction effects may indicate whether a separate analysis is warranted. For example, in a workers compensation analysis that treats indemnity payments as separate from medical, it is likely that several of the variables are likely to have interaction effects with the payment type. The more of these interaction effects there are, the more straightforward it is to model the payments with separate, distinct analyses, rather than deal with multiple interaction variables.
One of the additional benefits of considering these detailed payment types is in their ability to be included as predictive variables themselves. As mentioned earlier, payments to date and recent payments can both be very predictive of future payments for an open claim. Staying with the workers’ compensation example, it is common that the indemnity payments to-date on a claim is predictive of future medical payments and vice versa. In fact, drilling down even further to provide additional details about recent claim payments can add significant information for predicting the future behavior of open claims. Contrast this with the common technique of performing separate triangle analyses for Medical Only claims and Medical with Indemnity Payment claims. Instead, a single Medical claims model may emerge with the amount of indemnity payment to date as a variable of interest. Zero indemnity payment is an important value, but it may be that it is not very different from indemnity payment of less than $1000. Also, while the status of “no indemnity payment” is fairly stable for a claim, it does have the potential to change, and that can create issues for a triangle. Reflecting that changing status as a paid indemnity variable in a medical claim actuarial case reserving algorithm avoids that problem.
When adding such payment-type fields to a component development model it is incumbent to include the future simulated payments of various types as inputs into the simulation of the other payment types, adding complexity to the simulation process. Including such cross payment-type relationships into the case algorithm is more straightforward since it only requires payment types to be captured at each point in time.
Loss cost trend was discussed at various previous points in this paper. Inflation is an important topic and highlighted in importance in recent years. While individual claim modeling gives additional insight and measurement of its history, the question of where it is headed is unlikely to be answered, being more a function of macro-economic and other systemic questions. If inflation is expected to be significantly different from what has been observed in the past and is embedded into the various models built, one approach is to detrend the simulated projections with inflation/trend consistent with the assumptions from the past and retrend them the forecasted inflation/trend. From an ERM perspective this technique can be useful as well. Since simulation is being used to generate projections a variety of outcomes is projected. However, no attempt was made to insert correlation between claims into the simulation process and therefore an important (and for larger organizations, dominant) source of variability is unaccounted for. Detrending at a common historical trend and retrending by path for every claim payment projection using a variety of inflation/trend paths will insert an important source of variability.
7.2. Explanatory Algorithm/Use in Claims Management
While simulation is useful to project reserve development from a complex combination of predictive models across time periods, it can also make it difficult to attribute the specific differences in development across claims and exposures to specific characteristics. For example, suppose the claim closure rate is significantly slower for a particular geographic area. How much impact did the difference in closure rate make for the total estimated change from the current case reserve to ultimate for a claim in that area, given that there are more opportunities for changes in development the longer a claim remains open? For this reason, it is helpful to create explanatory predictive models at the end of the simulation process. Using the mean result of the simulation process for each claim as the target of prediction, the current case reserve as exposure, and all the variables that were found to be of importance in any of the component predictive models, a simplified explanation of which variables are the most important is provided, as is the nature of the impact of those variables.
In addition to being a simplified explanation of which variables drove the simulation results, it also can be used at future evaluations to mimic what the simulation process would generate for claims open at those points in time. It may not be necessary to go through the complete simulation process each time there is a refresh to the open claim list, if the explanatory model can do a good job of mimicking the simulation results. This can be useful for ongoing review of the open claim inventory for purposes of claim management, triage, etc. In addition, a model can be built targeting the standard deviation of outcomes from simulation. The predicting of claim outcome variability can be useful in defense cost budgeting/benchmarking. Simulated results or curve parameterization from the development/SD models can be used to provide predicted quantiles existing open claims. This can prove useful for scoring outcomes and measuring groups of claims (such as by adjuster) to identify anomalies and trends.
This post-simulation explanatory model (development prediction) is different from the actuarial case algorithm discussed in previous sections. Like the actuarial case algorithm, the prediction is of future payments for an open claim, as of a particular point in time, but there are several differences:
The actuarial case algorithm is designed for use in actuarial work of reserving and pricing. Individual claim results are less important in this context than aggregated results and changing practices regarding case reserve levels are problematic.
The explanatory analysis (development prediction) concentrates on individual claim level predictions and is focused on the differing potential of currently open claims to develop. There is less concern about shifts in general case reserve adequacy at this level.
While including the claim department case reserve as a predictor defeats the purpose of an actuarial case reserve due to its subjectivity, that same subjective information is useful when projecting the future development of an individual claim. Therefore, including the claim department case reserve in the explanatory analysis as a predictor is appropriate.
Because the explanatory model is focused on the current portfolio of open claims and how the simulation process is projecting them forward, only those claims that are being simulated are included in the parameterization. For the actuarial case reserve algorithm, all claims are considered valuable for parameterization, with cradle-to-grave information included in the portfolio of closed claims, and a combination of historical information and simulation included in the open claims.
7.3. Use in Pricing and Internal Management Reporting
In building a detailed model of reserving that includes IBNR, a pricing model is a natural by-product. The Frequency and Severity models described in Section 5.2.1 together form a model of pricing. The Unreported Reserve of Section 6.2 at the time of policy effective date is an expected loss cost for the policy.
It is important in actuarial pricing to consider the extent to which observed losses used for the pricing analysis need to be developed to an ultimate level, and how to develop them. Often very broad-brush approaches are used to address this question. Examples include:
-
Using reserves that have been allocated to the level of detail being priced
-
Applying development factors or premium development to policy level loss or premium
-
Comparing differentials in case-incurred loss across different types of policies as an estimate of differentials in ultimate loss
Each of these approaches is fine if and only if differences in loss development across each of the pricing variables are being properly reflected. Too often they are not. While most actuaries will recognize that loss development differences exist between different deductibles and that loss experience should be adjusted accordingly when using observed results to price deductible credits, they may not always consider that different industry classes, or geography, or policy form, or any other variable of interest may have differing loss development exhibited across its values. These differences are significant and indicated profitability and pricing indications can be very different between making blanket assumptions and properly reflecting difference in potential for additional loss development. Every pricing variable should be checked for potential distortions from loss development whenever immature data is being used to develop indications.
Sophisticated analytics techniques are being used now by actuaries to price insurance, but when the true variable of interest is ultimate loss and the item measured is case-incurred loss, there are likely to be significant distortions.
Possible choices for incorporating loss development differences in pricing include:
-
Use Frequency and Severity models from a claim life cycle model directly.
-
Use IBNR(0) directly from an Unreported Claim Algorithm
-
Use the results of case algorithm and IBNR algorithm as a starting point for building predictive models, in conjunction with payments to date.
In addition to providing more appropriate input for actuarial pricing calculations, using reserve estimates calculated at the claim and exposure level are valuable for internal management reporting. Rather than relying on crude allocations of reserve estimates to the various levels that may be reported (office, region, business unit, agency, etc.), the sum of claim and policy level reserves can be easily provided. If there is a final adjustment needed to be allocated to be in line with a reserve total that differs from the summed detail reserves, using the detailed reserves as the allocation basis will provide a much more thoughtful result. This has great potential for providing much more timely and reliable information about the results of underwriting efforts than that provided by crude allocation.
The graphic below illustrates the way in which the detailed claim development analysis can impact actuarial, underwriting, and strategic decision-making.

Much of the material in this paper is taken from a previous monograph “Individual Claim Development Models and Detailed Actuarial Reserves in Property-Casualty Insurance” by Chris Gross in 2021, available at cognalysis.com/resources/publications.
The author would like to thank Michael Larsen for his thoughtful review of a draft version of this paper and his useful suggestions, and also thank Tim Davis and Kevin Madigan for their valuable contributions, comments, and suggestions to the 2021 monograph, many of which are incorporated here.
See Friedland, J.F., “Estimating Unpaid Claims Using Basic Techniques,” Casualty Actuarial Society, Third Version, July 2010.
Berquist, James R., and Richard E. Sherman, “Loss Reserve Adequacy Testing: A Comprehensive, Systematic Approach,” Proceedings of the Casualty Actuarial Society 64, pp. 123–184, 1977
See Minimum Bias, Generalized Linear Models, and Credibility in the Context of Predictive Modeling by Chris Gross and Jon Evans, 2021, Variance Vol 12 Issue 1
This assumption is not always valid for aggregated data either and can cause problems for triangle analysis, but the assumption is not nearly as problematic as it is when considering claim-level development.
This process is similar in nature to a Markov Chain, in that each step in the chain is probabilistic, but a Markov Chain has the property that the future is independent of the past. The fact that paid losses to date are often one of the key predictors for the next timestep suggests it would be inappropriate to call this a Markov Process.
More sophisticated model specifications can use some of these payment types as predictors of others (increasing the number of models to be created). Barring this, it may be appropriate at times to consider individual payment types separately and in others to consider the sum across payment types.