





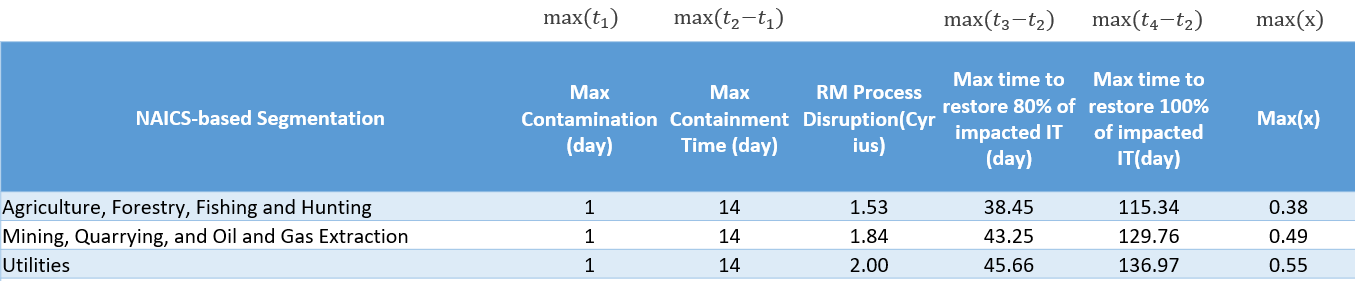
1. Introduction
There is a story about Enrico Fermi that Freeman Dyson, a mathematical physicist who played a crucial role in the development of quantum electrodynamics, recounts during an interview[1] and that we think is the ideal introduction to what the Loss Modelling from First Principles Working Party is attempting to do.
Dyson and his team at Cornell had produced the first draft of a theory that aimed at explaining Fermi’s experimental results on the behaviour of pions, and Dyson went on an expedition to Chicago to share these results with Fermi and seek encouragement to continue the team’s work. After listening to Dyson and having a quick glance at the graph that displayed an amazing fit between the theory and Fermi’s results, Fermi told Dyson “I’m not very impressed with what you’ve been doing.” He continued: “When one does a theoretical calculation, there are two ways of doing it: either you should have a clear physical model in mind, or you sh ould have a rigorous mathematical basis. You have neither.” When Dyson pressed him about the excellent agreement between the model and the data, Fermi asked: “How many free parameters are there in your method?” It turned out to be four. Fermi commented: “My friend von Neumann always used to say: ‘with four parameters I can fit an elephant, and with five I can make him wiggle his trunk.’ So, I don’t find the numerical agreement very impressive either.”[2]
This story illustrates the important point that there are essentially two ways of producing a model.
-
Start from an intuition about how the world works and/or using a rigorous mathematical process to derive the model from first principles, and then test the explanatory power of the model against reality (i.e., experimental data).
-
Start with any model – ignoring how it was derived – and check the significance of the fit using statistical tests, which basically puts von Neumann’s comment about elephant fitting on a quantitative footing.
Both approaches, if done with a proper methodological framework, are viable. Actuarial practitioners have historically – and for the most part – followed the second approach, and not always in the most rigorous way. At one end of the spectrum of rigour, actuaries may just pick a simple distribution such as the lognormal distribution for loss amounts or use the distribution from a distribution-fitting tool that best fits the observed data, without regard to the number of parameters. At the other end of the spectrum, actuaries might use rigorous machine learning methodologies such as using training, selection and validation sets and being mindful of the bias-variance trade-off when doing rating factor selection and calibration (see Parodi 2023 for a discussion of these different approaches). The increased interest in machine learning in recent years has helped actuaries use the proper model selection techniques.
This working party aims to investigate the extent to which it is possible to produce loss models according to the first approach, starting from our intuition and knowledge around the loss generation process and then developing a mathematically consistent model. The idea is that a model that fairly reflects the loss generation process will have a natural advantage and is likely to have fewer parameters. For example, an oscillating function might be helpfully modelled in a certain time interval with a polynomial or a set of splines, but if we have theoretical reasons to believe that an actual sinusoid of the form should be used, this will lead to a superior and more economic model.
The idea that a model should draw inspiration from how the world works is not, of course, a new concept in actuarial practice. Risk theory (Beard, Pentikäinen, and Pesonen 1984), the theory that gave us the individual risk model and the collective risk model, successfully framed the loss-generating process in terms of count (frequency) models and severity models and natural catastrophe modelling, while relying in part on historical loss experience, is heavily informed by a scientific understanding of the modelled perils. The technical actuarial standards for modelling (TAS-M) produced by the UK Institute and Faculty of Actuaries have this to say about models representing the real world:
[A]ctuarial information should be based on models that sufficiently represent those aspects of the real world that are relevant to the decisions for which the actuarial information will be used. This is, deliberately, a fairly general statement.
Despite this, in most cases “representing the relevant aspects of the world” is taken to mean “capturing the correct factors that affect a risk,” but there is a dearth of results in actuarial science that dictate the use of specific statistical models.[3]
1.1. The structure of the report
The structure of this report is summarised in Figure 1.1. Note that while we could have looked at any number of other models related to losses (e.g., payment pattern models) we have focused our attention on frequency and severity models, while noting that this separation is not always possible (Section 2.3.2.3). Section 2 is devoted to loss count (frequency) models, while Sections 3 to 8 are devoted to severity models for various types of business (property, liability, financial loss). These core sections are then followed by general conclusions (Section 8), acknowledgements (Section 9) and the bibliography (Section 10).

2. Modelling Loss Counts
2.1. The traditional approach
The traditional actuarial approach to modelling loss counts is to use one of the binomial, Poisson, and negative binomial distributions depending on how large the variance of the loss count is believed to be relative to the mean. This choice is not typically made for fundamental reasons but because these distributions are familiar and easy to work with. It’s also difficult to argue for more complex distributions when there are such a low number of data points (normally, the loss counts for 5-15 years) for calibration.
It is useful to distinguish between frequency models used in the individual risk model and those used in the collective risk model (Klugman, Panjer, and Willmot 2012), two attempts to produce risk models that reflect the reality of the loss generating process under different circumstances.
2.2. Loss count models for the individual risk model
In the individual risk model (IRM), losses are assumed to come from a finite number of risks each of which can have only one loss. Although we are dealing here with non-life insurance, this is perhaps best understood in terms of insuring lives. In equine insurance, a payout is given if a horse in the establishment dies or needs to be put down – which can only happen once to the same horse. The modelling of defaults in credit risk follows a similar pattern, where one replaces “death” with “bankruptcy.”
If all probabilities of death/default are the same, and the losses are independent of one another, the number of losses can be modelled with a binomial distribution, the sum of independent Bernoulli variables. According to this distribution, the probability of having k losses from n risks in a given period is:
\Pr(N = k) = \begin{pmatrix} n \\ k \end{pmatrix}p^{k}(1 - p)^{n - k}\tag{2.1}
The mean is the variance is and the variance to mean ratio is
When the probabilities are different, this generalises to the Multivariate Bernoulli Distribution, which is (Parodi 2023) an n-dimensional distribution with random variable where each component can take the values 0 (no loss) and 1 (loss). The probability of having k claims from n risks is given by:
\Pr(N = k) = \sum_{y_{1},\ldots y_{n}\ such\ that\ y_{1} + \ldots + y_{n} = k}^{}{\prod_{j = 1}^{n}{p_{j}^{y_{j}}\left( 1 - p_{j} \right)^{y_{j}}\ }} \tag{2.2}
2.2.1. Modelling the dependency between losses
Equations 2.1 and 2.2 are valid when the losses are independent of one another. When that is not the case, the variance/mean ratio will increase and can even exceed 1. Rather than adopting a different distribution in that case, it is generally more productive to model the dependency.
Unless the mechanism by which correlations occur is clear, the easiest way to model dependencies is by assuming the presence of a systemic shock – an increase in the probability of loss that applies simultaneously to all risks. This increase will normally be temporary: an epidemic among horses or an economic recession for defaults.
Using this framework, the underlying model can still be seen as a binomial or a multivariate Bernoulli, but with the probabilities of loss themselves being random variates.
2.3. Loss count models for the collective risk model
In the case of the collective risk model, the underlying portfolio of risks is also finite, but more than one loss is possible for every risk, and the effect of risks being removed from the portfolio by a total loss (think property insurance) is small if the portfolio is large enough. As a consequence, the occurrence of one loss doesn’t significantly affect the likelihood of another loss, and the variance of the loss count is at least that of a Poisson. The Poisson distribution is also justified as the limit of a binomial distribution when the probability of a risk being affected by the loss is very small, the number of risks is very large and the product converges to a finite (and non-zero) number.
Before proceeding further, let us introduce some key concepts. A count process with is a stochastic process where represents the cumulative number of events happening between 0 and (more specifically, in the interval The number of events in the interval is given by and is called an increment. A process is said to have independent increments if the number of events occurring in two non-overlapping intervals are independent. A process is said to be stationary if the probability of a given number of events in a given interval does not depend but only on : assuming we have equality in distribution
2.3.1. The stationary Poisson process as the foundational count process for the collective risk model
The simplest count process used in the context of the collective risk model is arguably the stationary Poisson process (Ross 2003). This is a count process with the following properties:
(a)
(b) The increments are both independent and stationary.
(c)
(d)
Here are some consequences of these assumptions:
-
The number of events in an interval of length follows a Poisson distribution: where is the event rate per unit of time.
-
The expected number of events and the variance of the number of events for an interval of length are the same and are given by
\mathbb{E}\left( N(\tau) \right)\mathbb{= V(}N(\tau) = \lambda\tau.
- The possibility of simultaneous events is excluded.
In practice, we notice that the assumptions that allow for the Poisson distribution to be used in the collective risk model often break down. This happens for example (note that the points below overlap to some extent):
- Where events do not occur independently, whether via direct dependence or common shock:
-
Fire: insurer covers a tight community, and e.g., an explosion in one flat may cause damage in all surrounding flats.
-
Professional lines: higher PI and D&O activity following a recession.
-
Healthcare: a disease is brought to a community and increases risk of everyone else getting it.
-
In riot/terrorism losses following a larger political/social event.
-
In cyber losses following a weakness emerging from an operating system.
- Where the future average rate may be altered by future events/decisions:
- Casualty: a new court award setting a precedent for future similar claims.
- Where multiple events occur in clusters:
-
Catastrophic events (natural catastrophes and human-caused catastrophes such as terrorism) often result in several risks being hit at the same time – e.g., hail events leading to many property/agriculture losses.
-
External factors driving catastrophic event frequency can also result in several events of the same peril happening at the same time because ‘conditions’ are right (e.g., warm seas and a high-frequency hurricane season, tectonic activity leading to increased earthquake frequency).
The following section will focus on the most important reasons for the departure from the simple Poisson frequency model.
2.3.2. Departures from the stationary Poisson process for the collective risk model
This section looks at the main reasons for the practical inadequacy of the stationary Poisson model (constant λ) in the context of the collective risk model, and for the widespread use of overdispersed models. We will see that overdispersion typically arise from the fact that the underlying process is a non-stationary Poisson process (Section 2.3.2.1) or a pure-jump (stationary or not) Lévy process that allows loss clustering (Section 2.3.2.2).
2.3.2.1. Non-stationary (non-homogeneous) Poisson processes
It is well known in actuarial practice that modelling the number of losses in a future policy period using a Poisson distribution will often underestimate the variance of possible outcomes. For this reason, models that exhibit overdispersion, that is, models where the variance exceeds the mean such as in the negative binomial model are used routinely.
Surprisingly, using an overdispersed frequency model might be necessary even if the underlying process for generating losses in a given policy year is a Poisson process (stationary or not).
Let us assume that the process by which claims are generated is a Poisson process. When the Poisson rate is not stationary, the total number of losses in a given period (say, one year) will follow a Poisson distribution with Poisson rate:
\Lambda = \int_{0}^{1}{\theta(t)dt.}
where represents the Poisson rate density (the number of expected losses per unit of time) (Ross 2003), and time is expressed in years. The Poisson rate density will in general be a stochastic variable itself, whose underlying distribution may or may not be known (analysis of historical loss experience may help in part). As a result, will also be a stochastic variable. Such process is normally referred to as a Cox process.
Therefore, while the underlying process is fully Poisson and the distribution of the number of losses conditional on Λ follows a Poisson distribution (and its variance will be equal to the mean), since is unknown at the time of pricing, the unconditional distribution used to model the future number of losses has a higher variance.[4] The overdispersion comes from ignorance about and not from the loss-generating process itself.
Examples of stochastic processes affecting the frequency of losses to various lines of business are:
-
various physical quantities such as temperature, pressure, wind strength, rainfall, etc. are stochastic processes with deterministic seasonal trends that affect the number of losses in various lines of business such as motor and household/commercial insurance.
-
economic indicators such as GDP growth in a given country may affect the number of professional indemnity claims or of trade credit claims.
In an approach from first principles, when we determine that a non-stationary Poisson process is responsible for the number of claims we should then investigate the cause of the volatility around the Poisson rate and model the rate intensity function accordingly as a stochastic or deterministic variable. From that we can derive the distribution of values of The loss count model corresponding to this case will therefore be a so-called compound Poisson process.
Special cases
-
While in general is a stochastic variable and therefore is also random, there are some special cases where is fully deterministic. E.g., if the underlying rate of car accidents only depended on the number of hours of light, would be seasonal but fully predictable. In this case would not be random and a Poisson model could be used.
-
In some formalisations the Poisson rate is not only non-stationary but the underlying process depends on previous states through a Markov process. Specifically, in Avanzi et al. (2021). the process is formalised as a Markov-modulated non-homogeneous Poisson process. It is assumed that the system can be in one of the states and that the probability of transition between state and is The duration of each state follows an exponential distribution (as in any Poisson process) with probability In a given state, events arrive at rate
\lambda_{M}(t) = \lambda_{M(t)} \times \gamma(t).
where is the intensity corresponding to the state the system is in and is therefore constant for a given state; is a correction factor that takes exposure changes and seasonal effects into account, as in the previous point. The probability of a given number of events occurring in a given time interval (say, one year) is then given by a Poisson distribution with rate
-
A special case of the compound Poisson process is when is stochastic and the behaviour of – which being the integral of a stochastic variable is also in general a stochastic variable – can be approximately described as a gamma distribution. In this case, a well-known result says that the resulting distribution is a negative binomial. This has become the model of choice when there is need for additional volatility. However, the case where comes from a gamma distribution is very special indeed and its use is mainly justified for practical reasons.
-
Actuaries are also quite familiar with a simplified but very useful special case of a compound Poisson model that is used in common shock modelling techniques (Meyers 2007). Common shocks are a way in which the assumption of independence between events breaks – because the shock creates a correlation between the events. The basic idea here is to consider that in most scenarios the Poisson distribution will have a “normal” Poisson rate Occasionally, however, there will be a shock to the system and the Poisson rate will be much higher, (obviously more than two scenarios are in general possible). One therefore needs to model the probability of a shock and its size (that is, of the shock to the Poisson rate according to past empirical evidence or from first principles. Classical examples of shocks are a zoonosis (increasing number of livestock or bloodstock losses) or an economic recession (impacting the number of financial loss claims).
-
An interesting example of a non-stationary Poisson process is the so-called Weibull count process – this is a non-stationary Poisson process where the waiting time between consecutive events is not exponential as in the stationary Poisson process but follows a Weibull distribution, i.e., a distribution whose survival probability is given by:
\overline{F}(t) = \ \exp\left( - \ \left( \frac{t}{\tau} \right)^{\beta} \right).
-
The best-known use of the Weibull distribution is in reliability engineering, to model the failure rate of a manufactured product, and this can be used in insurance for, e.g., an extended warranty loss model. When the failure rate decreases over time; when it increases; when it stays constant, and the Weibull reduces to an exponential distribution. In the typical life cycle of a manufactured product, you have at the beginning (when most production faults show up), for most of the lifetime of the product, and towards the end (when the product shows signs of wear). All this gives rise to the bathtub shape of the failure rate of products.[5]
-
When the waiting time can be modelled as a Weibull distribution, the resulting process will be a non-stationary Poisson process with Poisson rate which depends on time unless
2.3.2.2. Loss clustering and Lévy processes
Another way in which the independence between events breaks down causing an increase in volatility is when events are clustered. The Poisson distribution is often described informally as a distribution of rare events. What does this mean? It is true that the Poisson can be derived as the limit of a binomial distribution (see Equation 2.1) when and tends to a finite non-zero number. However, in a temporal sense, whether events are rare or not depends on the scale at which you look at them. The only sensible, scale-independent definition of rare events is therefore that there should never be more than one event at a given time. Clustering is where this breaks down. Clustering also may involve claims that are not brought together by simultaneity or rather near-simultaneity but for contractual reasons, as is the case for an integrated occurrence under the Bermuda form (a contract type for certain types of liability) – claims may come in clusters of tens, hundreds or even thousands.
Let us consider a compound distribution where we model the number of clusters, and then the number of events in each cluster. If the process by which clusters are generated is a stationary process, then the whole process can be seen as a special case of a Lévy process (Barndorff-Nielsen and Shephard 2012; Kozubowski and Podgorski 2009), and specifically a pure-jump Lévy process.
A Lévy process is a process with stationary and independent increments.[6] Brownian motion and Poisson processes are examples of Lévy process. Brownian motion describes the movement of particles under the assumption that their trajectory is not deterministic but affected by Gaussian noise. The stochastic equation for generic Brownian motion (in integral form) is given by:
X_{t}\ = \mu t + \sigma B_{t,}
where is a Gaussian process with mean 0 and standard deviation 1, and is the drift. A typical application of this is to model stock prices: for that purpose, however, is taken to be the logarithm of the stock price (which is never below zero): and therefore the equation can be rewritten as in differential format). is referred to as geometric Brownian motion.
One problem with Brownian motion as a model of insurance losses is that the sample paths are continuous and sudden jumps are not possible: when goes to zero, also always goes to zero. In reality, whether we speak about particles or stock prices, we see examples of the system undergoing sudden jumps, and any model that doesn’t take that into account underestimates the volatility of the underlying phenomenon. A Lévy process explicitly allows the possibility of having a number of finite jumps over a given time interval. A Lévy process can be described (informally) by the following Lévy-Khintchine decomposition[7] (Kozubowski and Podgorski 2009):
X_{t}\ = \mu t + \sigma B_{t} + \sum_{j}^{}{h_{j}\mathbb{I}_{\left\lbrack \Gamma_{j},\infty \right)}(t),}
where the last term describes a finite sequence of jumps at random times of size (Note that the process can always be put in a form that is right-continuous and has limits from the left.) The symbol stands for the random step function for 0 for where depends on the random sample.
A Lévy process has of three components: a deterministic drift, a Gaussian noise, and a collection of jumps. In the context of modelling loss counts we do not need the whole mathematical machinery of Lévy processes, and we can focus on the case where and only the jump components remain (a “pure jump” Lévy process). The Poisson process can be described as the case where for all
An obvious generalisation of the Poisson process to describe losses can be obtained when is itself a random variable with integer values larger than or equal to 1, or, in other terms, the case where losses are not isolated rare events but can occur in clusters. This is of course an approximation – in the real world, the losses do not actually need to happen at exactly the same time, but around the same time.
An interesting special case occurs when the number of clusters is Poisson-distributed with rate and the number of events occurring within a cluster can be modelled with the logarithmic distribution whose probability for is given by:
f\left( n_{e} \right) = \frac{1}{n_{e}\ln\left( 1 + n_{e} \right)}\left( \frac{p}{1 + p} \right)^{n_{e}}.
This case will produce a negative binomial distribution with parameters p and k (Anscombe 1950).
However, in general the numbers of events (losses) within each cluster need not be logarithmic: see Anscombe (1950) for alternatives[8] such as the Newman Type A distribution (Poisson distribution of events in each cluster) and the Pólya-Aeppli distribution (geometric distribution of events). Also, the number of clusters need also not be Poisson. For example, if the underlying process for the number of clusters is a non-stationary Poisson, then the overall process will not be a Lévy process, but a so-called non-stationary Lévy process.
Modelling from first principles, we should use non-stationary Poisson when there is local independence, and we have some sensible model of the intensity function. However, where clustering of losses occurs, we should use other models such as pure-jump Lévy processes or their generalisation to non-stationary increments (non-stationary pure-jump Lévy processes).
2.3.2.3. Does introducing Lévy processes bring any advantage?
It may appear that formalising loss count processes as Lévy processes is an overkill, as the Brownian component and the drift component are not used. A compound Poisson model would be a sufficient description. However, using the framework of Lévy processes gives us access to general mathematical results that are available off the shelf in this well-studied area of research. One such result is related to infinite divisibility.
A distribution for variable is said to be infinitely divisible if for any positive integer there exist independent and identically distributed random variables such that the distribution of is the same as the distribution of the sum The distribution of each depends on the original distribution.[9]
It can be shown that if is a Lévy process then is infinitely divisible, and conversely if is infinitely divisible then there is a Lévy process such that (Mildenhall 2017; Gardiner 2009).
The interest of this for loss modelling is that “[i]n an idealized world, insurance losses should follow an infinitely divisible distribution because annual losses are the sum of monthly, weekly, daily, or hourly losses. […] The Poisson, normal, lognormal, gamma, Pareto, and Student t distributions are infinitely divisible; the uniform is not infinitely divisible, nor is any distribution with finite support […]” (Mildenhall 2017). The extension to non-stationary Lévy processes, which better reflect the reality of a changing risk landscape, is then straightforward.
Just a few examples of infinitely divisible distributions that are useful for loss modelling purposes are:
-
The Poisson distribution.
-
The negative binomial distribution.
-
The normal distribution.
-
The Pareto distribution.
-
The lognormal distribution.
-
All compound Poisson distributions.
In relation to the last item, it is also important to notice that all infinitely divisible distributions can be constructed as limits of compound Poisson distributions.
Finally, Lévy processes can do much more than modelling loss counts. As shown in Mildenhall (2017), Lévy processes can be used to model aggregate losses. For that purpose, the jumps do not just represent the occurrence an event but also its size. An interesting consequence is that this gives us a first-principle reason for the separation between frequency and severity. It turns out that in general it is not possible to split the aggregate loss process into a count process and a severity process: it is only possible when the number of jumps is finite! In other cases, there may be an infinite number of small jumps and this split is not possible. In that case, however, it is still possible to model the process as a Lévy process, using a loss frequency curve (basically the OEP used in catastrophe modelling), as in Patrik, Bernegger, and Rüegg (1999).
2.3.2.4. Generalising the Poisson process: illustrations
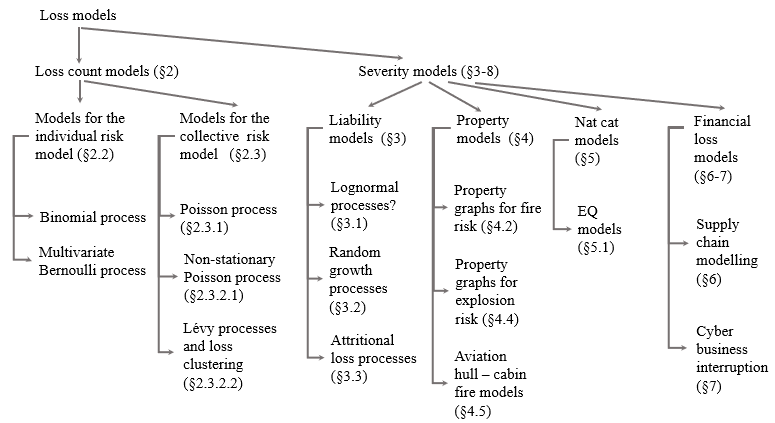
Figure 2.1 shows examples of the main ways of generalising the Poisson process: through non-stationarity (non-stationary Poisson process), clustering (general pure-jump Lévy process), or both (non-stationary Lévy process). All the processes are represented in terms of the cumulative number of unitary jumps as a function of time.
_an_example_of_a_poisson_process._the_x-axis_shows_the_timing_of_the_jumps_(lo.png)
3. Modelling the Severity of Liability Losses
Liability losses arise from bodily injury or property damage to a third party. The amount of a liability loss can be determined by the courts in a variety of ways that also depend on the jurisdiction. As a result, a detailed derivation of a ground-up liability loss model from first principles for all cases is probably hopeless. However, it is possible to find constraints on the scaling behaviour of severity distributions and justify them based on reasoning from first principles. Before doing that, it is useful to look at a traditional severity model and improvements that actuaries have made on it over the years using statistical theory.
3.1. Our misplaced fascination with the lognormal model and the evidence of a power-law tail
Since the beginnings of risk theory, the lognormal distribution has been viewed as a sensible attempt at modelling the severity of losses: it produces losses that are always positive and may span over several orders of magnitude. Although it does not have a power-law behaviour, you can’t say that it’s thin-tailed either: its behaviour is genuinely intermediate (Taleb 2020). A well-known paper by Benckert (1962) provides some empirical evidence that the lognormal works well. Unfortunately, upon closer investigation with richer data sets, it becomes clear that the lognormal model is rarely a good model for either the body of the distribution or the tail.
3.1.1. The empirical inadequacy of the lognormal model
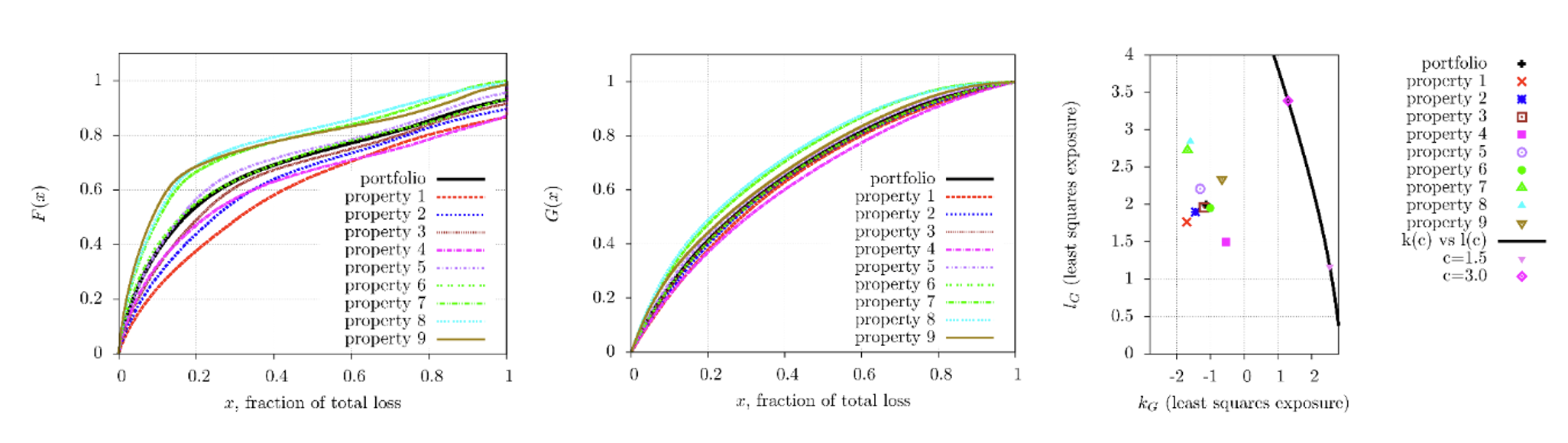
We have looked at several data sets of casualty losses and the fit to a lognormal has always proved to be severely unsatisfactory.[10] Two examples are given in Figure 3.1.
The charts show that the lognormal model is inadequate, and this can be proven even more sharply by using a metric to assess the distance between distributions, such as the KS statistic.
_a_lognormal_fit_to_a_large_number_(around_10_000)_of_employers__liability_claims_.png)
While the empirical inadequacy of the lognormal distribution is clear, we have also found that the tail of a portfolio of liability losses is almost always modelled well by a Generalised Pareto Distribution (GPD) with a power-law tail as predicted by extreme value theory.
3.1.2. Is the lognormal model theoretically adequate to model large losses?
According to extreme value theory, the tail of the distribution can be asymptotically described – apart from pathological circumstances – by a generalised Pareto distribution (GPD), i.e., a (survival) distribution of the form
\overline{F}(x) = \ \left( 1 + \xi\frac{x - \mu}{\nu} \right)^{- \frac{1}{\xi}}.
In turn, this distribution exhibits three possible types of behaviour depending on the value of : a finite-support distribution (Beta distribution) for an exponential distribution for (a limiting case), and a power-law distribution for The case is observed in most practical cases. Note that a GPD with will be asymptotically equivalent to a single-parameter Pareto with
This doesn’t immediately rule out a lognormal behaviour. The lognormal distribution shows an intermediate behaviour between the exponential and the power law, but asymptotically it falls under the exponential case – or in technical terms, the lognormal distribution falls within Gumbel’s domain of attraction (Embrechts, Klüppelberg, and Mikosch 1997). This can be shown analytically using the concept of local Pareto alpha (Ross 2003):
\alpha(x) = \frac{- x\overline{F'}(x)}{\overline{F}(x)} = \frac{xF'(x)}{1 - F(x)}.
It is easy to prove that (assuming F is a lognormal distribution) corresponding to
Therefore, while the lognormal distribution could be theoretically consistent with extreme value theory, in practice it should be discarded because portfolio losses tend to stabilise around a strictly positive value of
3.1.3. Is the lognormal model theoretically adequate to model attritional losses?
Having become cognizant of the fact that the GPD captures the behaviour of the tail better than the lognormal, actuaries now tend to use a GPD (or a simpler Pareto) for tail modelling and reserve the lognormal for modelling attritional (small) losses. This is the approach taken, e.g., in Knecht & Küttel (2003) and in Fackler (2013), where new classes of spliced Lognormal/Pareto and Lognormal/GPD distributions are introduced to formalise this approach. This is a good workaround to ensure that a suitable model is used where it matters most: in the tail.
However, experience shows that the lognormal distribution is not generally a good match for attritional losses either. Indeed, Figure 3.1 shows two examples of a behaviour that we often found in our work as practitioners: empirical distributions often appear as the conjunction of two parts that are broadly linear in a log-log scale, with a concave elbow connecting the two. This behaviour is not one that a lognormal distribution is able to capture and is one reason why the lognormal performs poorly everywhere. This also suggests that the distinction between attritional losses and large losses is probably more than a convenient trick to simplify the analysis. It also points to the potential usefulness of using different types of distributions for the attritional losses – e.g., by using a Type II Pareto/GPD splicing.
3.2. Modelling large losses from first principles: the emergence of the power-law behaviour
The asymptotic behaviour of large losses is mainly dominated by their scaling behaviour: namely, by how the behaves as a function of x. If the severity distribution is an exponential distribution then – it decreases quickly and soon becomes undistinguishable from zero. If the severity distribution is a single-parameter Pareto with parameter , then : the ratio is the same at all or, equivalently, the ratio is the same at all scales and has a so-called fractal nature.If the severity is GDP with the ratio will have a slight dependence on that will asymptotically disappear:
Thanks to extreme value theory (EVT) and specifically to the Pickand-Balkema-de Haan (PBdH) theorem, we know that the exponential and power-law behaviour all possibilities with positive unbounded support, i.e., in most practical cases. Observation also tells us that the most common behaviour is a power law. While the PBdH theorem constrains the asymptotic behaviour of the severity distribution, it does not say what drives a particular behaviour and specifically why the power-law behaviour is so ubiquitous. Where does this power law behaviour come from?
3.2.1. Random growth processes in economics
A power law is often observed in statistical physics, especially in the context of phase transitions. It occurs in the presence of system-wide coherence. In economics, power laws have been observed for the distribution of incomes, wealth, the size of cities, the size of firms, and many other examples (Figure 3.2). In all these cases, the power law behaviour (and specifically the Pareto law) has been explained as the steady-state distribution resulting from a random growth process (Gabaix et al. 2016) where the growth rate is uniform across all sizes.
Let us expand on this. In all cases shown in Figure 3.2, the phenomenon can be described by a stochastic differential equation whose solution is a Pareto distribution. According to Gabaix (Gabaix 1999; Gabaix et al. 2016), the basic insight is that these other power laws are the steady state distribution arising from the scale invariance of the physical process of growth. Growth is homogeneous at all scales: therefore, the final distribution process should also be invariant, which means that it has fractal nature and must follow a power law.
In the most modern (and simplest) incarnation, this means that the process can be described by stochastic differential equations of this type (we follow Gabaix et al. 2016):
dX_{t} = \mu\left( X_{t},\ t \right)dt + \sigma\left( X_{t},\ t \right)dZ_{t}.
where is a stochastic variable (such as income, wealth, city size, firm size), is the growth at time t, is the spread at time t, and is a Brownian motion. This equation can be interpreted as follows: the variable increases in time because of a deterministic drift and random effects that can be described as a Brownian motion. The case in which we are most interested is the one where both the growth rate and the spread rate are constant at all sizes and are time-independent, i.e., and This gives[11]:
dX_{t} = \mu X_{t}dt + \sigma X_{t}dZ_{t}.
The distribution of variable at time t is[12] We want to describe the evolution of the distribution given the distribution at time The tool to do so is the so-called Forward Kolmogorov equation, which for our case can be written as:
\frac{\partial f}{\partial t} = - \frac{\partial\left( \mu xf(x,t) \right)}{\partial x} + \frac{1}{2}\frac{\partial^{2}\left( \sigma^{2}x^{2}f(x,t) \right)}{\partial x^{2}}.
We are specifically interested in the steady state of distribution – if it exists – because that will tell us what we need to know, the distribution of income, wealth etc in equilibrium. We are therefore interested to solve the FKE for the case We are basically seeking the solution for what is now an ordinary differential equation:
- \mu\frac{d\left( xf(x) \right)}{dx} + \frac{1}{2}\sigma^{2}\frac{d^{2}\left( x^{2}f(x) \right)}{dx^{2}} = 0.
Once rewritten (after a few calculations) as:
\frac{\sigma^{2}}{2}x^{2}\frac{d^{2}f(x)}{dx^{2}} + \left( 2\sigma^{2} - \mu \right)x\frac{df(x)}{dx} + \left( \sigma^{2} - \mu \right)f(x) = 0.\tag{3.1}
it becomes clear that one possible solution is a function of the form which turns Equation 3.1 into a second-degree equation in This has two roots: and The first root is not “physical,” as it leads to a divergent equation. As for the other, it leads to a Pareto distribution with
Assuming that the solution must make economic sense, which translates into a smoothness constraint, it can also be proved that this is the only solution (Gabaix et al. 2016).
We have however done a sleight of hand: we have assumed that such an equilibrium distribution is possible, which is not the case unless we make other extra assumptions. As we mentioned previously, if these extra assumptions are not included the solution to the FKE is a lognormal distribution with indefinitely increasing mean and variance, which never reaches a steady state (Gabaix et al. 2016). Researchers have resolved this issue in the past in two ways:
(a) By assuming that the random variable has a minimum value (any value will do!) that acts as a reflective barrier (e.g. a minimum salary, or a minimum city size).
(b) By assuming that the system has some type of attrition so that new elements enter and exit the system, e.g., in the case of the income distribution, new people join the labour market and others retire/die.
Both assumptions are reasonable in the real world. The theory then shows that in these cases a steady state solution is possible and therefore that solution is a Pareto law, at least asymptotically. This is consistent with the results of EVT, as a GPD with positive shape parameter asymptotically becomes a Single-Parameter Pareto law.
3.2.2. The random growth process and loss distributions
We have now seen several examples of circumstances – mostly related to economic quantities – in which the Pareto law emerges as a result of an underlying random growth process. On the other hand, we have significant empirical evidence for the Pareto law applying – at least approximately – to the realm of large insurance losses. What can we say about whether such an empirical fact can be reasonably explained by a random growth process?
3.2.2.1. Mechanisms for the emergence of power laws
There appear to be two possible ways in which we can show that a Pareto law will eventually emerge for a (liability) loss distribution in most cases: an indirect mechanism and a direct one. The indirect mechanism is quite straightforward: liability losses comprise different components. Limiting ourselves to bodily injury claims, these components are:
-
loss of earning (or dependant’s loss of earning in the case of death).
-
cost of care including medical costs.
-
pain and suffering.
-
other (e.g., punitive damages).
If at least one of these components follows a power law, the overall resulting distribution will be (asymptotically) a power law. The “loss of earnings” component of a loss is proportional to income (in a non-trivial way, as it is also affected by other factors such as age) and if we accept Champernowne’s analysis (Champernowne 1953) – which has indeed been tested successfully for many territories – this follows a Pareto in the tail of the distribution. If more than one power law is in play, the one with the thickest tail will eventually dominate the tail and will fully characterise the asymptotic behaviour.
Another example is given by D&O losses. These are proportional to the size of firms, which also follows a Pareto law according to Simon and Bonini’s analysis (Simon and Bonini 1958).
The direct mechanism is derived by looking at the growth rate of losses themselves. While a full-blown theory for this is not available yet, there are clear indications that one or more of such mechanisms exist. As an example, consider court inflation: compensations from previous cases are used as benchmarks for current cases and increases tend to be a percentage of the benchmark, leading to an exponential increase.
For the existence of a steady state distribution and the emergence of a Pareto law, we also need to find one limiting mechanism: either a minimum loss or a factor of attrition. While the existence of an attrition factor for losses cannot be excluded (e.g. certain types of losses disappearing from the list of potential losses), the existence of a minimum loss seems to be the most straightforward way of demonstrating the existence of a steady-state solution: whether because of the existence of deductibles or because below a certain monetary amount a claim simply doesn’t make sense, we can safely assume that a minimum loss exists.
3.2.2.2. Attritional vs large losses
Champernowne’s article also points to an interesting distinction between low incomes and high incomes, which appear to follow different laws. The existence of these two different “regimes” is explained by the fact that lower incomes tend to grow less rapidly than higher incomes. The same distinction appears to be valid for losses. Traditionally, actuaries subdivide losses into attritional and large losses. The main reason behind this distinction is often one of convenience: small losses are treated as an aggregate allowing actuaries to pay more attention to individual large losses. However, there may be more to the distinction than simply size. Attritional losses tend to go through a more streamlined claims settlement process with little or no court involvement, and therefore their increase in time is linked more to standard inflationary factors such as CPI and wage inflation and less to court-driven social inflation. Also, if this is the case, we should see a radically distinct behaviour in the log-log CDF graph between attritional and large losses. This is indeed what we observe in practice (see Figure 3.1): both attritional losses and large losses appear to be distributed on a straight line in log-log scale, although this is only a very rough approximation for attritional losses. This points to two different types of behaviour for the two different types of losses. These empirical observations and results from other economic examples both point to an intrinsic rather than convenience-driven difference between attritional and large losses.
An alternative explanation for the difference in regimes is that the growth for the low part of the distribution is not invariant and that attritional losses have not (yet?) achieved a steady-state distribution, in which case we could attempt to represent the lower part of the distribution as an intermediate stage in the transition between a lognormal distribution and a Pareto distribution, as it occurs in the simulation in Figure 3.3. That would be an interesting comeback for the lognormal distribution!
3.2.2.3. Empirical demonstration of the emergence of a power law
We can demonstrate the emergence of a power law, i.e., the steady state solution to the FKE, for a system where the random variable has a minimum value empirically using a numerical simulation. Consider two types of stochastic random walk for the random variable The first is a standard Geometric Brownian motion (GBM), which can be written as The second is the reflected Geometric Brownian Motion (rGBM), which can be written as:
X(t + dt) = \left\{ \begin{array}{r} X(t) + \epsilon X(t),\ X(t) \geq x_{\min} \\ X(t) + \max(0,\epsilon)X(t),\ X(t) < x_{\min}. \end{array} \right.
The stochastic simulation is based on random increments drawn from a normal distribution with mean and variance :
\epsilon = \mu\ dt + \sigma\sqrt{dt}Z, \ Z\sim N(0,1).
The parameters are: and throughout.
In both walks, the starting point is and we take We generate a sample of paths over a total time-period where each path is a set and study the distribution of the endpoints for different values of
The assertion is that for large values of the reflected geometric Brownian motion will result in a power-law distribution for the endpoints, with a survival function:
S_{X(T)}(x)\sim ax^{b}, \quad b = - 1 + \frac{2\mu}{\sigma^{2}}.
This distribution arises as the steady-state solution to the dispersion relation for the geometric Brownian motion. In the continuum limit the coefficient appearing in could be determined via the relationship
E\left\lbrack X(T) \right\rbrack = \int_{x_{\min}}^{}{dx\ S_{X(T)}(x)}.
However, for numerical simulation, it is not possible to arbitrarily decrease to zero, since for a relatively long total time-period, the number of steps required to form the path becomes prohibitively large. This means that the normalisation coefficient in the above cannot be determined from the simulation.
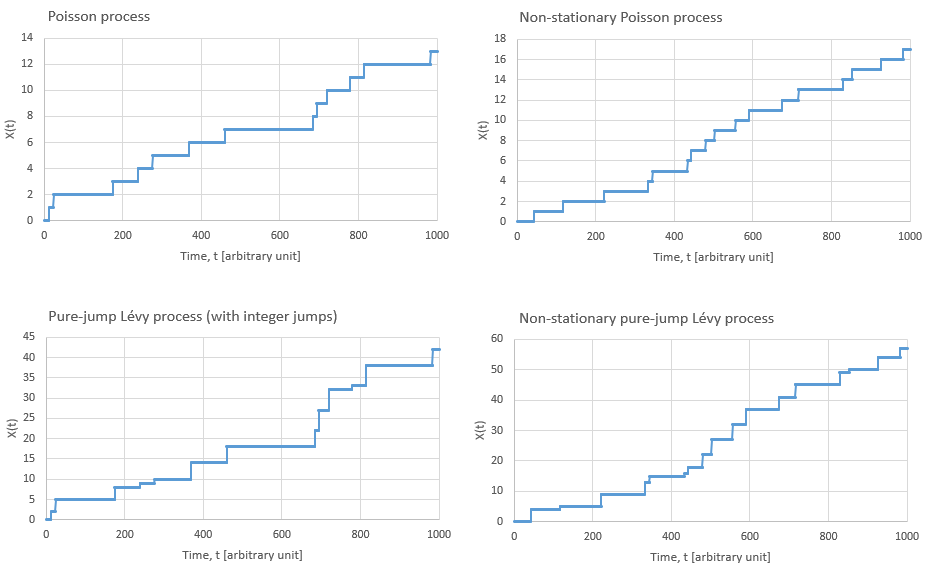
The empirical distribution of the endpoints is represented via the survival function (exceedance probability) for various time periods in Figure 3.3.

For the geometric Brownian motion and reflected geometric Brownian motion result in lognormally distributed endpoints (the simulated curves both coincide with the dashed ‘lognorm’ analytic curve), as expected. For the reflected geometric Brownian motion endpoint distribution starts to deviate and straighten out. This continues up to (the straight line), where the simulated curve lies on top of the power-law fit (the dashed straight line, using the power and determining the coefficient from the 95th percentile of the simulated curve).
3.3. Is an approach from first principles to attritional losses even needed?
Attritional losses are messy, and we do not expect to capture them with a neat distribution derived from first principles, although when the empirical distribution displays a clear two-phase behaviour and it appears smooth for both attritional and large losses, it might be worth trying a Type II Pareto/GPD fit. On the positive side, that may not be necessary as we can avoid modelling the attritional losses altogether: attritional losses are almost by definition small and plentiful and therefore we can simply resample from the available data. One can also use interpolation, but this doesn’t add much value in most circumstances.
The theoretical underpinning for the resampling approach to attritional losses is Glivenko-Cantelli’s theorem, which states that the empirical distribution converges uniformly to the real distribution The connection with the Kolmogorov Smirnoff (KS) test is obvious and it is possible to put limits around the KS statistic with a certain probability. For example, we know that with probability of 95% for large enough values of n.
This theoretical result says almost everything we need to know but there are still interesting practical considerations and questions. For one thing, resampling has obvious limitations: for example, if the loss data set is resampling can never produce losses above also, losses tend to rarefy when they become large and therefore the distortions arising from interpolation become more significant. We can expect that resampling works better for attritional losses than for the general population of losses. Another practical consideration is, how much do we lose in practice by using resampling? To be more specific, if we know that the correct distribution is, say, a lognormal we want to compare (a) resampling from the data available with (b) using a lognormal model calibrated based on the available data. We can calculate the KS distance between the true underlying model and (a) vs (b). Repeating many times gives an estimate of the average KS distance for the two approaches. Note that the KS distance must be evaluated for losses below some threshold, since simple resampling is not interesting for large losses except in special cases.
We have tested data coming from a lognormal distribution with mean equal to 25 and standard deviation equal to 5, for different sample sizes (10, 20, 30, 50, 100, 200, 300, 500, 1000, 2000, 3000, 5000, 10000). The main message is that for small samples the model tends to perform better than resampling, but the difference rapidly shrinks as the sample increases in size, and eventually resampling performs undistinguishably from modelling.
_model__test_set_vs_training_set__test_set_.png)
We have shown that even in the case where we know the true distribution and we generate losses from it, using resampling is almost as good as using a model calibrated based on existing data, apart from the case of very small samples (say, 100 if the threshold for attritional is at the 90th percentile of the distribution, in case of a lognormal). We have also argued, however, that the lognormal model is normally not a good model. Indeed, given the messy character of attritional losses, it is unlikely that any standard continuous distribution is a very good model. Therefore, in practice, for data sets of sufficient size resampling the empirical distribution will outperform any attritional loss model. Using software such as R or Python make resampling as easy as working with a parametric model, essentially removing the only reason to use a parametric model.
4. Modelling the Severity of Property Losses
4.1. The traditional approach to property modelling
The standard method for producing a severity model for liability losses – i.e., fitting a curve to historical loss data – is not straightforward to apply to property business because future losses depend critically on the maximum possible loss (MPL) profile of the portfolio, which is not necessarily the same as the MPL profile of past years. For this reason, it is more natural to model losses as percentages of the MPL for each building and construct standardised curves (CDFs and exposure curves), under the assumption that their shape does not depend on the MPL but only on the type of construction.
In Europe and other territories, Bernegger’s curves (also called MBBEFD curves) are widely used for this purpose.
4.1.1. Bernegger’s curves and their connection to statistical mechanics
Bernegger’s curves are curves borrowed from statistical mechanics. However, as Bernegger emphasised from the beginning, their use is purely practical and there is no suggestion of any deeper connection with statistical mechanics.
It is useful to state the formal connection between Bernegger curves and statistical mechanics, because it was not done in the original paper, and because we will need to refer back to it later when exploring the use of graph theory in the context of property pricing.
The probability density for the different curves from statistical physics are given by:
\small{ f(x)=\left\{\begin{array}{ll} \frac{1}{Z} e^{-\frac{x}{k T}} & x \geq 0, \text { Maxwell-Boltzmann } \\ \frac{a}{c e^{\frac{x}{k T}}-1} & x \geq 0, \text { Bose-Einstein } \\ \frac{a}{c e^{\frac{x}{k T}}+1} & x \geq 0, \text { Fermi-Dirac } \end{array} .\right. }
In the most general format, the survival probability corresponding to Bernegger’s curves is given by:
\begin{align}\overline{F}(x) &= \left\{ \begin{matrix} \frac{1 - b}{(g - 1)b^{1 - x} + (1 - bg)} & x < 1,\ b > 0,\ b \neq 1,bg \neq 1,g > 1 \\ b^{x} & x < 1,\ bg = 1,\ g > 1 \\ \frac{1}{1 + (g - 1)x} & x < 1,b = 1,\ g > 1 \\ 1 & x < 1,\ g = 1\ or\ b = 0 \\ 0 & x = 1 \end{matrix} \right.\ \\ &= \left\{ \begin{matrix} \frac{1 - b}{\frac{(g - 1)b}{gb - 1}e^{- (\ln{b)}x} - 1} & x < 1,\ b > 0,\ b \neq 1,bg \neq 1,g > 1 \\ e^{(\ln{b)}x} & x < 1,\ bg = 1,\ g > 1 \\ \frac{1}{1 + (g - 1)x} & x < 1,b = 1,\ g > 1 \\ 1 & x < 1,\ g = 1\ or\ b = 0 \\ 0 & x \geq 1 \end{matrix}, \right. \end{align}
where the curly bracket on the left shows the standard way of writing Bernegger’s curves, while the curly bracket on the right shows a rewriting that makes the connection with statistical physics more obvious.
The three different cases can therefore be obtained by changing the value of : corresponds to the Maxwell-Boltzmann distribution, to the Bose-Einstein distribution, to the Fermi-Dirac distribution. The case is not physical. Setting the survival probability to zero at is also a mathematical trick to produce a finite probability for a total loss and does not correspond to a physical situation.
It should also be mentioned that there is a special (“Swiss Re”) parameterisation dependent on a single parameter c formed from a particular configuration: Based on empirical studies, Bernegger suggests that residential property fire damage corresponds to whereas industrial properties may be described by values up to
The probability of a total loss is given by for any value of b, and for
It should be noted that all Swiss Re c curves are solidly within the Bose-Einstein region of Bernegger’s curves.
As already mentioned, Bernegger was careful not to suggest a deeper relationship with statistical physics. Interestingly, however, if one considers certain possible mechanisms for producing severity curves for fire one finds the three different regimes (MB, BE and FD) correspond to three different ways in which fire propagates. To see why that is the case, we need to see how property losses can be modelled from first principles using graph theory.
4.2. Property losses using graph (network) theory
4.2.1. The basic theory
Parodi & Watson (2019) presented an approach to modelling property losses from first principles based on graph theory, a branch of discrete mathematics.
A graph, also be a network, is an abstract mathematical object that can be thought of as a collection of nodes some of which are connected via edges.
The paper presented two ways in which fire losses can be understood. In both cases, the approach relies on a representation of a property as a graph whose nodes represent rooms/units, with edges between two nodes if there is a passageway – i.e., if direct fire propagation between the two corresponding rooms is possible.
In the simplest version, the value of each room/unit is the same, say 1, and each node reached by the fire is considered fully lost so that the loss for each node is either 0 or 1. In either approach, the fire is assumed to start at a randomly selected node, that node plus those nodes connected to it are assumed to have been reached by the fire and the loss is then simply equal to the number of nodes in that subset.
In this framework, the total insured value (TIV) is the number of nodes in the graph, while the maximum possible loss (MPL) is taken to be the size of the largest connected component of the graph since a fire starting in one connected component cannot propagate to a separate connected component for lack of passageways. This simple framework can of course be refined at will: the value of different nodes may vary, and partial losses at nodes allowed.
4.2.1.1. Static approach
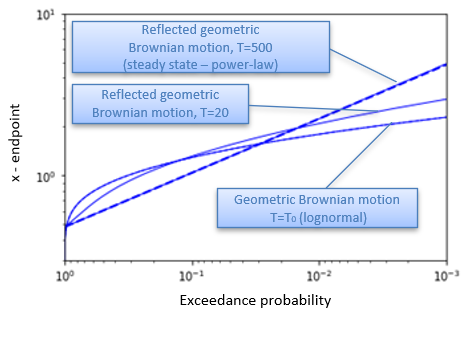
The static approach starts from a weighted graph[13] being the (set of) nodes (or vertices), the edges, and the edges’ weights. Losses are simulated by picking a node at random as the origin of the fire, and then delete each edge in the graph with a given probability The loss amount is given by the size of the connected component containing the node in what remains of the graph dividing by the MPL (the largest connected component of the graph before edge deletion) gives the damage ratio. The process is repeated for many simulations until the distribution of the damage ratios emerge. The algorithm is described in more detail in Parodi & Watson (2019) and a visual representation of it is shown in Figure 4.1. The simulation can be run for both a single property or for a portfolio of properties, in which case one must also pick properties at random.

4.2.1.2. Dynamic approach
An alternative approach is to view the fire as propagating through a building deterministically with the route defined by the graph connectivity but for a random time.
In this approach, edge weights are related to the time it takes for fire to spread through a given passageway and their status (e.g., open vs closed doors).
The fire will spread and burn for a time (“delay”), until it is finally extinguished. In Parodi & Watson (2019), the delay distribution was assumed to be a simple exponential distribution being the inverse of the expected time before the fire is put out) for lack of sufficient data to produce a data-driven or principle-based distribution.
As for the static approach, the simulation to produce a normalised severity curve starts by choosing a node where the fire starts. However, a random time for the fire propagation is also selected. From the moment the fire starts, it starts traversing the graph deterministically. The time to traverse an edge depends on the nature of the separation between two rooms: , , represent the number of time steps it takes to traverse an edge representing an open door, a closed door and a wall/floor respectively. For a particular simulation, a door is assumed to be open with a certain probability The traversing progresses until the time is reached. See Parodi & Watson (2019) for details.
As for the static case, the simulation can be performed for a single property or for a portfolio. The results of the simulation with a given set of parameters are shown in Figure 4.2.

The Bernegger model gives a good approximation of the various curves produced by the simulation for both the individual properties and the portfolio, but the values of the parameters differ greatly from the Swiss Re curves. This finding remains true for a wide range of different choices of the parameters.
Having summarised Parodi & Watson (2019), we next investigate the relationship between the MBBEFD parameters that approximate the severity curve of given graphs, and the type of temporal law for the spread of fire.
4.2.2. Bernegger (MBBEFD) curves and an interpretation of MB vs BE vs FD
Let us concentrate on fire damage and treat it as a physical process, using the random time approach of Section 4.2.1.2. Namely, a fire starts, spreads and is then put out (or at least brought under control so that no further damage occurs) after some time. If the fire spread is not stopped within a certain period, there is a total loss. The spread of fire is not modelled as a random physical process here, but as a deterministic process. What is considered random is the cause of the fire, and how long it takes for the emergency services to react and stop the fire from doing further damage.[14]
Assume that the fractional loss is a deterministic function of a random time and further assume that the random time is drawn from the exponential distribution with parameter We can write:
X = f(T),\ T \sim Exp(\lambda),\ {\overline{F}}_{T}(t) = e^{- \lambda t},\ E\lbrack T\rbrack = \frac{1}{\lambda}.
The as-yet unknown function is called the evolution function and represents the fractional amount of damage done. It should be non-decreasing and has the boundary conditions
f(0) = 0,\ f\left( t > t_{\max} \right) = 1
for some maximum time Given that the probability of a total loss we can write
\Pr\left\lbrack T > t_{\max} \right\rbrack = e^{- \frac{t_{\max}}{E\lbrack T\rbrack}} = \frac{1}{g},
such that
g = \exp{\left( \frac{t_{\max}}{E\lbrack T\rbrack} \right) = e^{\lambda t_{\max}}}.
In other words, the MBBEFD parameter can be described in terms of the time it would take a fire to spread and destroy the building completely and the mean time taken to respond and stop the fire from spreading further. This is a simple, intuitive, and natural interpretation.[15] Further, the parameter for the exponential distribution has been set (without loss of generality) to 1.
Now let us derive the evolution function that corresponds to the CDF for the MBBEFD distribution that obeys the boundary conditions. This can be done by considering the probabilities (restricting to for now):
\overline{F}(x) = P\left\lbrack f(T) > x \right\rbrack = P\left\lbrack T > f^{- 1}(x) \right\rbrack = e^{- \lambda f^{- 1}(x)}
or
t = f^{- 1}(x) = - \frac{\ln\left( \overline{F}(x) \right)}{\lambda}.
Using the definition of we can invert the expression above to yield Before doing that, however, we introduce new variables to have an expression that covers all cases.[16]
x = f(t) = - \frac{\ln\left( \frac{\beta e^{\lambda t} + \alpha}{\beta + \alpha} \right)}{\ln(1 - \beta)}.
We can calculate using and expanding the definitions of and :
f\left( t_{\max} \right) = - \frac{\ln\left( \frac{(\beta g + \alpha)}{(\beta + \alpha)} \right)}{\ln(1 - \beta)} = - \frac{\ln\left( \frac{1}{b} \right)}{\ln(b)} = 1.
Having considered what happens for we can now apply our boundary conditions and write down the expression for rewritten in terms of the deterministic evolution of a process over a random time drawn from an exponential distribution:
X = f(T),\ T \sim Exp(\lambda),\ f(t) = \min\left( 1, - \frac{\ln\left( \frac{\left( \beta e^{\lambda t} + \alpha \right)}{(\beta + \alpha)} \right)}{\ln(1 - \beta)} \right).
It should be emphasised that the above is formally identical to the MBBEFD distribution, the difference being in how it is written. The physical picture of a fire spreading over a random time is simply our motivation for choosing the form of the expression and how to interpret it.
4.2.2.1. Separating the MB, BE, and FD regimes
Using the above definitions, the three regimes correspond precisely to the sign of : the MB regime corresponds to the BE regime to and the FD regime to We will show that the evolution function exhibits three distinct behaviours in the three regimes.
By differentiating the evolution function with respect to time (for we can derive a differential equation form:
\frac{\ln(b)}{\lambda}f^{'}(t) = \frac{\alpha}{\alpha + \beta}e^{\ln(b)f(t)} - 1,
where we recall that is an increasing function and that So, the three regimes are:
-
MB Here we have already seen that and the evolution function is linear in time.
-
FD Here we use that such that and Then (keeping only the signs and ignoring constants) and we see that decreases with time and that the evolution function is decelerating.
-
BE Now we must consider the values of b (since b=1 is a special case):
-
Case For this case, and is increasing with time such that the evolution function is accelerating.
-
Case Now and the evolution function is exponentially increasing. This can also be written as and again the evolution function is accelerating.
-
Case For this case, and so again, the evolution function is accelerating.
-
In summary, the three different regimes correspond to whether the evolution function is decelerating (FD), linear (MB), or accelerating (BE).
4.2.2.2. Some examples
Figure 4.3 shows a few scenarios for the time evolution of fire, corresponding to Bernegger curves in different regions of the space. The parameter for the exponential distribution is set to in all cases, without loss of generality because is simply a scaling factor.
_example_of_the_be_regime__time_evolution_for_a_swiss_re_curve_with__c___1.5__(res.png)
4.2.2.3. Connection between the property graph topology and the parameters of the Bernegger distribution
We have rewritten the Bernegger distribution in terms of a system undergoing a deterministic evolution over an exponentially distributed random time. There are two parameters and and three types of behaviour. The parameter dictates how long it takes relative to the mean time taken to stop the process for there to be complete destruction. The parameter governs how the process evolves: a larger value of is associated with a system where the evolution is accelerating.[17] This provides an intuitive and appealing physical picture for the interpretation of Bernegger curves.
What is still missing is to make explicit the connection between a property’s graph (its topology) and the type of statistic that best describes the evolution of the fire. Interestingly, all examples based on real-world topologies for household properties in Parodi & Watson (2019) led to parameters solidly belonging to the decelerating FD region. However, it is not difficult to imagine graphs that lead to an accelerating BE distribution. One such example is a graph where one hallway node is connected to a very large percentage of other nodes, and each node is separated from the hallway node by at most two degrees. In this case, if the fire originates in a node separated from another node by two degrees, after one step it will have affected a small number of other nodes, but one step later it will touch the hallway node and from there it will spread almost immediately almost everywhere, an obvious case of spread acceleration.
Another way of producing the BE behaviour is by considering a constructive total loss whenever the number of nodes exceeds a certain percentage of the whole graph. This will remove the effect of obstinate nodes that only burn after a very long time and provide an alternative mechanism for acceleration. It is like considering that alongside fire there are other related phenomena such as smoke that cause damage, so once a good percentage of the property is out of order the likelihood of salvaging the rest is reduced.
Similar considerations can be made for the static approach. The removal of certain edges with a given probability is unlikely to disconnect the hallway node from the rest of the graph, and therefore a total loss (or near-total loss) is more likely.
At the other end of the spectrum, we have graphs with poor connectivity. An example of this is a Cayley tree[18] of degree m. If the depth of this graph is k, the total number of nodes is If a fire originates at a random point, it is more likely to originate close to the boundary, where most nodes are, and therefore to propagate slowly (of course if it originates at the root, it will expand quickly).
4.3. Percolation theory and the spread of fires
The spread of fire is akin to an epidemic and can be formalised in terms of percolation theory. Percolation theory describes how the addition of nodes or edges to a graph changes the behaviour of the graph. Historically, the motivation for this type of theory is explaining percolation, the movement of fluids through a porous material, but it has now developed into something much more general tha.t sheds light on phase transition and critical phenomena.
Percolation theory has been applied to model the spread of forest fires (Rath and Toth 2009; van den Berg and Brouwer 2006). Those results don’t apply immediately to the types of graphs considered in Parodi & Watson (2019) and in this paper, because we mainly use small graphs while most of the interesting results appear when considering the asymptotic behaviour of networks.
Interestingly, the Bose-Einstein statistic and the Fermi-Dirac statistic emerge quite naturally in the study of percolation (Bianconi 2001, 2015), suggesting that the Bernegger curves may provide more than a purely formal connection to the losses caused by the spread of fires.
To summarise, there appear to be two types of networks: power-law networks which give rise to a BE statistic and Cayley trees which give rise to an FD statistic. According to Bianconi and Barabási (2001), growing networks self-organise into a complex network in which some nodes have an outsized number of connections to the rest of the network. These networks can be mapped into an equilibrium Bose-Einstein gas, with energy levels corresponding to nodes and particles corresponding to edges. This gas exhibits condensation as well – i.e., a single node captures a macroscopic fraction of edges. How can this be related to a fire? One way is for the nodes to represent property units already reached by the fire, and new nodes being added out of an existing network of inactive nodes representing the existing property units with their connections. However, currently this is only a research suggestion.
Bianconi (2015) showed that if the structure of the graph is a growing Cayley tree, the distribution of the energies at the interface (i.e. at the leaf nodes) converges to an FD distribution.
In both Bianconi & Barabási (2001) and Bianconi (2015) the key idea is to create a mapping between the graph model and a condensed state with various energy levels. Each node corresponds to an energy level, while an edge corresponds to two non-interacting particles at different energy levels.
4.4. Explosion risk
So far, we have only looked at fire risk. However, property policies traditionally cover insurance against the so-called FLExA perils of fire, lightning, explosion, aircraft collision, and All Risks policies also cover natural catastrophes. Explosion risk was dealt with in Parodi & Watson (2019) using weighted directed graphs and we refer the interested reader to that paper.
4.5. Aviation Hull losses arising from cabin fires
As an alternative example of how it is possible to model fire losses from first principles, we have considered Aviation Hull and specifically losses arising from post-crash cabin fires, which result from ground collisions or high-speed landings. A study by NASA[19] in 1982 on a B737 aircraft on how cabin fires develop showed a slow initial temperature rise, followed by a rapid increase, reaching flashover (a near-simultaneous ignition of most combustible material in an enclosed area). Subsequent studies by United States’ Federal Aviation Administration (FAA)[20] and the National Institute of Standards and Technology (NIST)[21] using modern aircraft material suggested the flashover point would occur on average at 325 seconds after ignition. Once flashover is reached, the hull experiences a total loss.
An independent analysis of the damage ratio for fire losses using a third-party database, analysing over 60 fire/explosion losses of wide-body aircraft between 1974 and 2020 reveals a 30-37% probability of total hull loss in the event of the cabin fire.
Combining these two types of analysis, we can assume that (a) the hull damage is a function of time from ignition, analogously to the approach we outlined in Section 4.2.1.2; (b) the distribution of time before the fire is extinguished is exponential: where λ = 1/325s, putting the probability of reaching flashover at ~37%; (c) the distribution of the damage ratio follows a Bernegger distribution (for example, a Swiss Re c curve) with a probability of total loss of 37%.
This analysis is of course very preliminary, as it is based on a number of conjectures on the relationship between hull damage and physical parameters and is affected by both model and parameter uncertainty, and more research is needed.
5. Modelling the Severity of Natural Catastrophe Losses
Natural catastrophe (cat) modelling relies on geophysical and engineering models rather than historical loss fitting, although historical losses obviously play a role. It is a clear example of where modelling from first principles already exists. We will therefore not dwell on this topic for long as it would mean mostly repeating results already well known in the literature, but will use a single example, earthquake modelling, for illustration purposes.
5.1. Modelling losses arising from earthquakes
An example is provided by earthquake modelling. Loss data suggest that the severity of losses broadly follow a Pareto law with exponent of around 1 (Mitchell-Wallace, Wilson, and Peacock 2012). This can be related to the Gutenberg-Richter law, which is an empirical relationship between the magnitude of an earthquake and the total number of earthquakes in any given region/time period of at least that magnitude: The parameter is typically between 0.8 and 1.5 in seismically active regions. This relationship needs to be paired up with that which gives the energy E released during the earthquake: The combination of the equations for N and E leads to the following power law for the number of earthquakes releasing an energy larger than E:
N(E)\ \propto \ E^{- \frac{d}{b}}.
Hence, the probability that an earthquake releases an energy larger than E is:
\overline{F}(E)\ \propto \ E^{- \frac{d}{b}},
which is a Pareto distribution with The insured loss will then depend on the energy released and the vulnerability of the structures exposed to the earthquake.
There is no unique explanation from first principles as to why this empirically observed law holds, but various possible mechanisms have been put forward. The most interesting explanation (Bak and Tang 1988) is perhaps the one based on the concept of self-organized criticality,[22] which suggests that the Earth’s crust can be modelled as a dynamical system that is both dissipative (i.e. it releases energy) and is spatially extended with a number of degrees of freedom that is approximately infinite. The interactions between various physical, chemical, and mechanical processes in the Earth’s crust lead to a critical state where earthquakes can occur spontaneously, analogously to what is often cited as an example of self-organised criticality, the grain of sand that leads to an avalanche of the heap of sand it falls on. The Gutenberg-Richter relationship reflects the scaling properties of these interactions and the distribution of energy stored in the Earth’s crust and leads to a power-law distribution of earthquake sizes and ultimately payouts.
5.2. Modelling other natural catastrophes
Note that, as mentioned in Bak and Tang (1988), dynamical phenomena with power law correlation function appear to be widespread in nature and are seen in weather, landscapes and other areas, so the pattern described here is likely to be found for other types of natural catastrophes (Mandelbrot 1982); similarly with Helmstetter’s approach of fractal scaling (Helmstetter 2003).
5.3. Non-geophysical explanations
Apart from these geophysical explanations, it should be noted that another plausible mechanism to explain the distribution of loss amounts in earthquakes and catastrophes in general could be related to the distribution of city sizes, see Zipf’s law which we discussed in Section 3.2.1. It makes sense that earthquakes of the same magnitude will have different impacts depending on the size of the population affected, and therefore an earthquake in a large city will cause much more damage than a similar earthquake in a small city.
6. Modelling contingent business interruption (supply-chain) losses
The insurance industry has traditionally dealt with business interruption/loss of revenue impacts in a rather arbitrary manner. The Business Interruption premium rate is often set as a simple multiple of the Property Damage rate. The loss data available is often expressed in terms of financial amounts as opposed to physical delay times (numbers of days lost) and so often combines information on:
-
the interruption period.
-
the financial impact per day (which will differ for partial losses and total losses.[23])
-
the basis of recovery (fixed costs only; full loss of profit etc.).
The risk can become even more complex where third-party revenues are impacted, as in contingent business interruption (CBI). Underwriters will often try to identify a “network” of potential loss scenarios where coverage is scheduled and offer a lower limit for any “unscheduled” losses that fall outside of these scenarios.
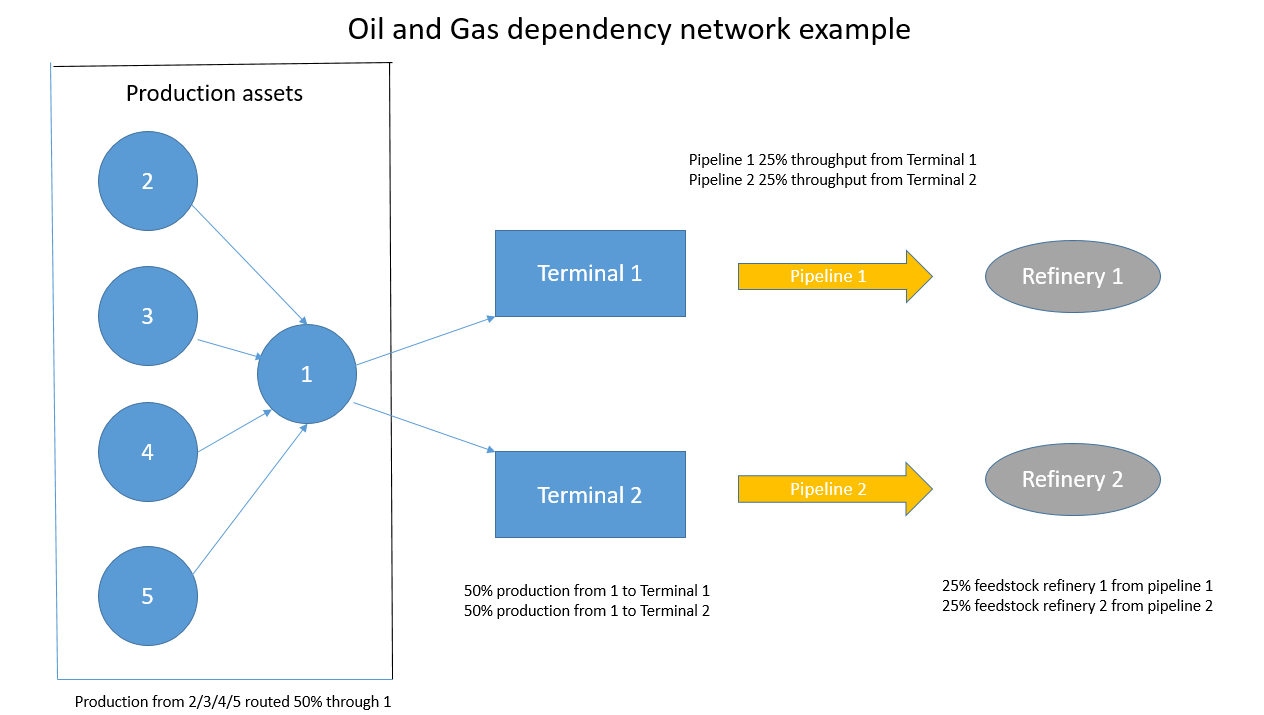
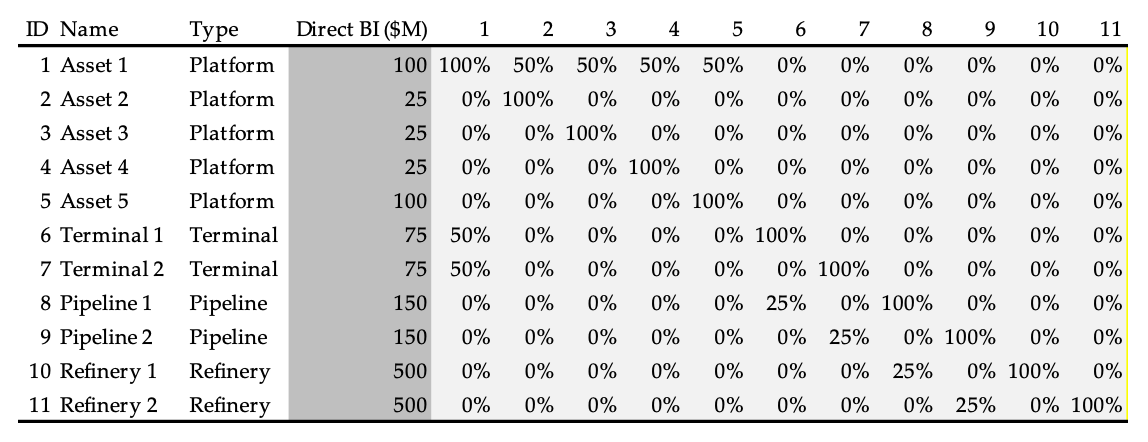
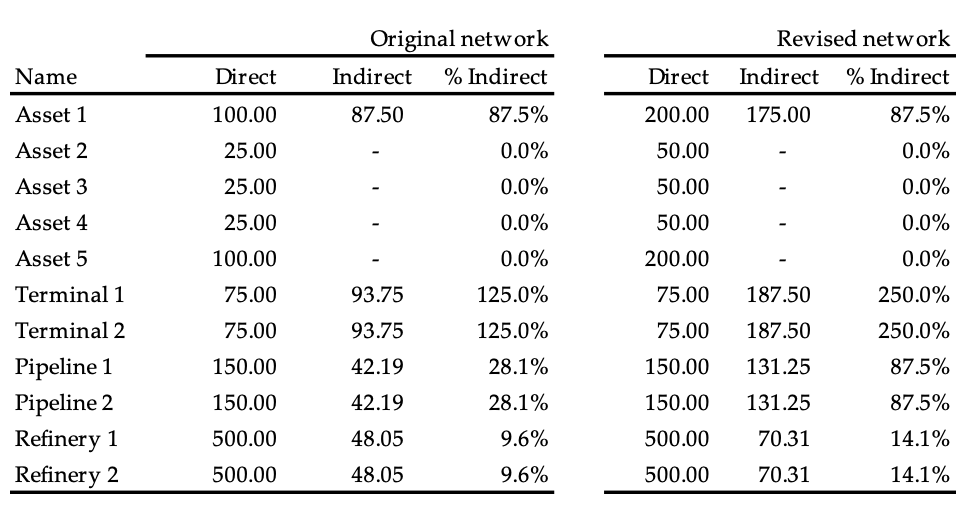
With the recent advances in mapping technology and real-time estimates of values at risk it is possible for underwriters to set up all their exposures and create a dynamic dashboard reflecting any peak concentrations, such as a terminal through which a significant amount of oil and gas production may flow or a critical pipeline to transport oil or gas from a producing field to a terminal or a processing facility/refinery. To truly estimate an expected maximum loss (EML) for such a network, probability distributions would be required to reflect:
-
the chance of a significant loss event (property damage, terrorism/war, cyber, pandemic…).
-
the likely downtime period.
-
the recovery period (considering that production may return on a partial basis before full production is restored).
-
any mitigation that may be available, e.g., the ability to re-route production (at a cost) via an alternative pipeline or through use of an alternative processing facility.
The loss of revenue impact from a key distribution centre can be many times the direct value of the site/building. This revenue impact could also be triggered by other risks such as cyber attack; terrorist activity either directly at the location or in the immediate vicinity; or the impact of a pandemic impact on the workforce.
6.1. Modelling supply chain risks using networks
Most academic research tends to focus on Property Damage modelling and the interpretation of risk engineering surveys to evaluate the physical risk of loss (Estimated Maximum Loss studies). There is far less research available on Business Interruption exposures.
Perhaps even more than in the case of property risk, supply chain risk lends itself naturally to being analysed through a directed graph[24] representation. The nodes of the supply chain represent suppliers/assets and there is a directed edge connecting A to B if A provides materials or services to B needed (or useful) for the overall functioning of the supply chain. The direction of the edge is of course essential as the role of supplier/receiver cannot be reversed.[25] The edge from A to B will in general have a weight, reflecting the proportion (or absolute amount) of product that B receives from A. Nodes might belong to different classes: for example, one class of nodes might represent production sites and another class of nodes might represent warehouses. Edges might also be of different natures: for example, road routes vs sea routes or even internet routes. All this suggests that an appropriate representation of complex supply chains may require a graph with a very rich structure. We will typically refer to such a complex graph as a “network” as it is a term more commonly used in the context of supply chains.
A more sophisticated analysis would also consider the time element, e.g., to adjust the exposure for insuring conditions such as waiting periods, indemnity periods and maximum daily recovery rates etc.
As a simple example consider a typical oil and gas exposure where the network can be described as in Figure 6.1. The Direct Business Interruption values at risk and the relative dependency is summarised in Table 6.1.

._as_mentioned_in_section_4.2.1__such_matri.png)
The critical dependencies can be summarised as follows:
-
Assets 2 to 5 are routing production via Asset 1 (a gathering platform for the whole field) so are 50% dependent: e.g., if Asset 1 is closed/lost then some routing/mitigation may be possible but Assets 2 to 5 would have to reduce production by 50%.
-
Terminals 1 and 2 are each taking 50% of the production from Asset 1.
-
Pipeline 1 gets 25% of its throughput from Terminal 1. Pipeline 2 gets 25% of its throughput from Terminal 2.
-
Refinery 1 gets 25% of its feedstock from Pipeline 1. Refinery 2 gets 25% of its feedstock from Pipeline 2.
We can then calculate Business Interruption effects as a loss propagates through the network. For, example a loss of Asset 1 (a platform) would impact the direct BI value ($100M) but also 50% of the value at platforms 2/3/4/5, i.e., 50% of $175M = $87.5M. The total exposure from platform one could be considered as $187.5M.
When considering insurance some attention may need to be paid to any sub-limits being applied for contingent business interruption.: If, for example, the BI is being declared as $100M at Asset 1 with a blanket $50M available for contingent BI then the overall recovery may then be limited to $150M, etc.
As we move through the supply chain there are also lower order effects to consider (third order, fourth order etc.). Consider, for example, Refinery 1. The direct BI exposure is declared as $500M. The loss of Refinery 1 would, however, also trigger:
-
a 25% loss at Pipeline 1 ($37.5M – second order effect).
-
a loss capacity at pipeline 1 would then trigger a loss at terminal 1 ($75M x 25% x 25% = $4.69M – third order effect).
-
a loss of capacity at Terminal 1 would trigger a loss at Asset 1 (100M x 50% x 25% x 25% = $3.13M – fourth order effect).
-
a loss of capacity at Asset 1 would trigger a loss at assets 2/3/4/5 – total $2.73M
-
Asset 2 $25M x 50% x 50% x 25% x 25% = 0.391M
-
Asset 3 $25M x 50% x 50% x 25% x 25% = 0.391M
-
Asset 4 $25M x 50% x 50% x 25% x 25% = 0.391M
-
Asset 5 $100M x 50% x 50% x 25% x 25% = 1.563M
The full lower order effects were calculated as in Table 6.2.
-
As a sensitivity check let’s consider the impact if the direct values at risk at the five production assets were to double (e.g., because of higher oil and gas prices) and due to supply constraints, we assume Pipelines 1 and 2 are now receiving 50% of their throughput from Terminals 1 and 2, respectively. The business interruption lower order effects are now calculated as shown in Table 6.3.

This can be summarised by considering the relationship between direct, first-order BI and indirect lower-order BI effects as in Table 6.4.

When considering an overall business interruption limit, however, it would be unusual for the buyer (or the broker) to analyse the risk at this level of detail. Using the example above, it may be more common to declare a simple catch-all additional $100M for contingent business interruption based on Table 6.4 (the original network), even though the knock-on impact of the factors described in Scenario 2 suggests this could lead to significant underinsurance.
It is possible to build a simple pricing tool that accounts for these factors and tests the impact of varying the coverage such as increased waiting periods or sub-limits on indirect losses.
7. Modelling the severity of Cyber Business Interruption losses
Cyber Business Interruption (Cyber BI) is difficult to model via experience rating because of the paucity of data. For this reason, a risk engineering approach that focuses on the underlying risk mechanism and disruption pattern of Cyber BI incidents is both interesting from a theoretical point of view and practically helpful.
Cyber BI differs from conventional property-damage related BI in some important ways:
-
The disruption period (which doesn’t involve restoration of physical assets) is much shorter, translating into shorter contractual indemnity periods.
-
Cyber BI is not location-specific: a cyber attack can trigger business interruption losses in different territories.
To derive Cyber BI curves, we will adopt a risk engineering approach focusing on the underlying risk mechanisms. Several loss scenarios are considered such as an IT service provider (cloud) outage, a local IT service outage, and a supplier’s outage due to Cyber risks.
7.1. Disruption Pattern for a Cyber BI Event
The extent of Cyber BI depends on the disruption pattern: the duration of the outage, the availability and effectiveness of loss mitigation measures, the repair/replacement of information technology (IT)/operational technology (OT) services, and eventually the time required to fully restore operations of the insured.
To model the disruption pattern, we assume the pattern is composed of three phases:
-
Contamination. Cyber threats are starting to emerge and impacting the operation of the insured by up to depending on the insured’s cybersecurity posture[26] and business structure/organisation.
-
Containment. Once the threat is discovered, the insured will contain the impact and reduce the adverse impact. The duration of this phase depends on several factors, e.g., the insured’s business continuity plan, their crisis management process and third-party assistance, and the resources available for incident response.
-
Cure. In this phase, the insured’s IT-related business is restored up to a certain level. The time required for this will depend on the identification of critical cyber assets, disaster recovery plan, the Recovery Time Objective (RTO), and the availability of the IT team. The full recovery of the business would further depend on some non-IT factors and may take considerably longer time.

Figure 7.1 shows a simplified and linearised representation of the cyber disruption pattern. Some terminology is needed to explain the graph:
-
x is the (estimated) maximum percentage of interruption that can be caused by a cyber-related issue. This number depends on the type of occupancy, network segmentation, patch management, and is normally below 100%: e.g., if the reservation system is down, a hotel can still work to some extent without the system.
-
describes the estimated interruption pattern: hence, represents the percentage of interruption at time which will typically decline with time as the IT system is brought back to full functionality. The times can be considered realisations of random variates describing the inset of the three different phases.
7.2. Calibration of parameters
More detailed calibration work has been done on how to assess the maximum possible durations of each period, and the maximum level of interruption of IT-related revenue disruption. Below is an illustration of such an assessment for a company of a certain size in a given country, for 3 NACIS codes.

7.3. Simulation of loss scenarios
The computation of insured BI losses is sometimes complex and differs significantly depending on the wording of each policy and local practices, notably loss of gross margin, loss mitigation cost and increased costs of working. However, our intention is to identify and quantify the main components and then build a model.
Let denote the average daily loss if the IT-related activity of the insured is completely interrupted We could then calculate the insured BI loss with the following formula:
L_{BI}\left( x,f(t) \right) = \int_{0}^{t_{4}}{i(t)\ {\overline{L}}_{d}dt} = \ {\overline{L}}_{d}x\int_{0}^{t_{4}}{\ f(t)dt}.
Monte Carlo simulations can then be performed to generate one million Cyber BI scenarios for each sector. A few random scenarios generated for “Finance and Insurance sector” are shown in Figure 7.3.

Using this simulation, we can produce a distribution of the possible losses for a particular sector and derive from that the corresponding exposure curve. Figure 7.4 shows both for Finance and Insurance.
One advantage of this approach is that the maximum possible loss (MPL) is approximately equal to the maximum simulated loss if the number of simulations is sufficient. For Finance and Insurance, this appears to be close to 48.5 This can, however, also be calculated analytically assuming the estimated maximum time for each interval; the estimated maximum time will depend on the industry sector.
The empirically derived CDF for the damage ratio 𝑌 (loss as a percentage of MPL) can be denoted as The damage ratio is
Y = \frac{L_{BI}(x,f(t))}{MPL_{BI}} = \frac{\overline{L_{d}}\int_{0}^{t_{4}}{\ xf(t)dt}}{M\ \overline{L_{d}}\ x} = \frac{\int_{0}^{t_{4}}{\ f(t)dt}}{M\ },
where M is 48.47 according to the calculations above for Finance and Insurance sector.
The exposure curve can then be derived from the corresponding (empirical) severity curve by the standard relationship , where is the normalised deductible and
_and_exposure_curve_(right)_.png)
8. Conclusions
Given the wide remit of our working party, and the fact that different covers will be modelled differently in terms of first principles, a variety of techniques and approaches was only to be expected. Despite this, a few significant common threads have emerged.
Graph (network) theory appears to be a natural choice to model losses of properties that can be broken down in different units/components that are connected to one another. It also finds a natural use in modelling financial losses arising from failures in actual networks such as a supply chain, and in contingent business interruption.
Another broad strand is that of stochastic processes, which will be no surprise to actuaries since the loss generating process is itself a stochastic process. To be more specific, loss count processes are best viewed as examples of pure-jump processes, stationary or not. As for the severity of losses, especially in the context of casualty (liability) insurance, the ubiquitous presence of the Pareto behaviour for large losses can be explained by the presence of underlying random growth processes.
8.1. Limitations and future research
Each of the topics addressed in this report is wide enough to deserve a separate paper. In each case, more research is needed to flesh out the theoretical arguments fully and bring further empirical support.
In Section 2, more research is needed on modelling the causes of non-stationarity, whether natural or man-made, and the size of the clusters where such clusters are observed.
In Section 3, conjectured mechanisms leading to a Pareto behaviour need to be confirmed and articulated further.
In Section 4, more research is needed on the relationship between graph structure and exposure curve and why most curves used in practice appear to be in the Bose-Einstein region while most curves originating from graphs produce exposure curves that are in the Fermi-Dirac region. The connection with percolation theory needs to be investigated further. Research on other types of cover such as extended warranty, machinery breakdown, and satellite insurance can also be carried out through the lenses of risk engineering and network theory.
Further work would be needed to calibrate the dependency matrix approach in Section 6 by reviewing actual historical loss events and to consider (from engineering and supply chain data) a suitable probability distribution for downtime and the time to reinstate facilities.
Since cyber is a relatively new risk and is continually evolving, the details of the approach in Section 7 may quickly become obsolete and models will need to be updated accordingly to keep abreast of these changes.
Acknowledgments
A previous version of this paper was presented at the International Conference of Actuaries 2023 in Sydney and was awarded the Best General Insurance/ASTIN paper prize. Our thanks to Frank Cuypers, Yuriy Krvavych and the ASTIN section for encouraging us to create the working party from which this paper originated; and to Christian Levac, Walter Neuhaus and Eric del Moro for their help through the process. We also thank our companies: SCOR, Gallagher Specialty, WTW, QBE, Hiscox, Acasta, and Marsh for their support in this research initiative. We are indebted to several people for advice on the actual content of this report. Pierre-Louis Lions crucially pointed us in the fruitful direction of random growth models when exploring the severity of liability losses. Balázs Ráth and Ginestra Bianconi helped us with discussions around percolation. Stephen Mildenhall provided helpful feedback and material on Lévy processes and reviewed the rest of the paper. Jean-Stéphane Bodo pointed us to the emergence of power laws in the context of natural catastrophes. Massimo Vascotto pointed us to helpful information around the process for establishing liability payouts in Italy and other countries. Bernard Wong pointed us to useful material around non-stationary Poisson processes. Finally, we would like to thank Shane Lenney for reviewing this paper and providing us with helpful advice.
A large language model (ChatGPT) was used to put the references in ascending order and ensure that they were all formatted using the same standard. It was also used to check a number of standard definitions, e.g., for graph-theoretic concepts.
Dyson wasn’t bitter about this conversation, which marked the end of the project. Rather, he was grateful because it prevented his team from wasting further time working on this theory – which, as Fermi had predicted, turned out to be incorrect. The experimental results were later explained by Murray Gell-Mann’s theory, according to which the physics of pions could be explained by assuming that pions are made of a quark and an anti-quark.
One notable exception is the use of the Generalised Pareto Distribution (GPD) for modelling the tail distribution of severities, which is demanded (asymptotically) by extreme value theory.
The unconditional variance of the number of losses for a doubly stochastic Poisson process, can be written as Since the conditional process is Poisson, When is constant and In general,
It is also relevant, even more intuitively, to human mortality, that tends to be higher among infants and among the elderly, while being roughly stationary in the middle: for this reason the regime is also called “infantile phase”, and the regime is referred as the “aging phase”.
Formally, a process defined on a probability space is said to be a Lévy process if it possesses the following properties: (a) The probability that is 1. (b) For is equal in distribution to (stationary increments). (c) For is independent of (independent increments). (d) for all values of t: i.e. the probability of a finite jump at an arbitrarily chosen time is zero (probability continuity). Notably, Condition (d) implicitly allows for jumps of random sizes at random times, as we will see later when we introduce the Lévy-Khintchine decomposition.
More formally, the Lévy-Khintchine decomposition states (Appelbaum, 2009) that a stochastic process can be written as where is the drift, is a Brownian motion, and is a pure-jump process, which can be further decomposed into a compound Poisson process with a finite number of jumps larger or equal to 1, and a compensated generalised Poisson process a process with countably many jumps smaller than 1, but such that the integral of these jumps converges in distribution. In the case most relevant to us in this paper, that of count processes, the only relevant component is and specifically as all jumps have positive integer size.
Some of these alternatives display a multi-model behaviour which might be appropriate in certain circumstances.
Infinitely divisible distributions of the variable can also be characterised in terms of their characteristic function If where the s are iid variables, the characteristic function can be written for any as where is the characteristic function of each of the s.
Note that it is difficult to evaluate goodness of fit visually if one uses a linear representation of the empirical CDF against the corresponding model: all fits look similar and they tend to look better than they are; also, the tail behaviour – which is the one that we are keenest to represent faithfully – is shrunk in the top right corner of the chart and it’s very difficult to distinguish one tail behaviour from the other. For this reason, a representation which is now more commonly used adopts a log-log scale, which has the useful property that a Pareto distribution appears as a straight line in the chart.
Equivalently, we can write which has perhaps a more familiar format.
In the absence of other constraints, the solution of this equation is a standard lognormal distribution with indefinitely increasing mean and variance. As we will see shortly, however, under certain conditions an altogether different behaviour emerges.
A graph (Trudeau 2003) is a mathematical structure comprised of a collection of nodes and a set of edges that link pairs of nodes. When every edge has a specific weight, the graph is known as a weighted graph. Unweighted graphs can be thought of as weighted graphs with all weights = 1. If there exists a path from node to node through a sequence of connected edges, the two nodes are said to be connected. A connected component of a graph is a subset of the graph where every pair of nodes are connected. A directed graph, or di-graph, is a graph where the edges have a direction, meaning the order of the nodes the edge connects is crucial. The edges are represented by arrows. Directed graphs can also be weighted. One popular (if uneconomical) representation of graphs and di-graphs is as matrices where the entry at row and column is non-zero if and only if there is an edge connecting to and the entry value is equal to the weight. The matrix will be symmetric for undirected graphs. Matrices will be used in Section 6 to represent supply chain networks.
Here, we are considering a single building in isolation. If we were to consider a portfolio of properties, one might also treat which property is burning as a random variable.
Moreover, recall that the Swiss Re curves are based on the parameter g being an exponential of parameter c – the typical scales in the two descriptions are similar.
The case is equivalent to and the case corresponds to the limit The denominator is always well-defined since Also,
Note that all Swiss Re curves are in the Bose-Einstein region as long as the parameter c is between -0.48 and 21.48.
Some definitions may be helpful here. The degree of a node is the number of edges connected to the node. A tree is a graph with no loops. A rooted tree is a tree where one of the nodes has been designated as the root. The designation of a root establishes a hierarchical structure within the tree: every other node in the tree has exactly one path to the root node, and a parent-child relationship in the tree is created: every node except the root has parent nodes, and nodes may have child nodes (in which case they are called intermediate nodes) or not (in which case they are called leaf nodes or interface nodes). The depth of a rooted tree is the number of nodes in the longest path between the root node and any leaf node. A Cayley tree of degree m is a rooted tree that has a highly regular and symmetric structure: a root node of degree leaf nodes of degree 1 and intermediate nodes of degree A tree structure is an idealised topology for a property where the removal of an edge (a fire route between two units) fully disconnects the property into two, then drastically limiting the spread of the fire. A Cayley tree has been chosen as an example because it is especially simple to describe mathematically.
Full-scale flammability test data for validation of aircraft fire mathematical models https://ntrs.nasa.gov/citations/19820013292
Background : FAA Fire Safety - https://www.fire.tc.faa.gov/Research/Background
Fire Dynamics – NIST - https://www.nist.gov/el/fire-research-division-73300/firegov-fire-service/fire-dynamics
Self-organized criticality (SOC) is a concept in the field of complex systems that refers to the idea that some systems, without external tuning, can evolve towards a critical state, where small perturbations can cause large-scale effects. The classical example is that of a heap of sand, to which you slowly add one grain at a time. Eventually it will reach a state where a small nudge will cause an avalanche, sending many grains tumbling down. This is an example of a system that is self-organized into a critical state. In this state, the size of the avalanches follows a power law distribution, meaning that small avalanches are much more frequent than large ones, but large ones are not impossible.
See LMA bulletins 5607/5608 that intend to create a standard basic wording for calculation of business interruption losses and the application of daily (monthly) indemnity caps.
A directed graph is a graph where the edges have specified directions and they are called directed edges.
Naturally, it might be the case that A supplies products/materials to B and B supplies other products/materials to A, in which case you’ll have two separate edges, one from A to B and another from B to A.
Cybersecurity posture refers to the cyber defence measures of the insured, e.g., authentication, employee training, deployed security system/solutions and the collective effectiveness of the combination of individual measures.