




“The Pareto principle is an illustration of a ‘power law’ relationship, which also occurs in phenomena such as brush fires and earthquakes. Because it is self-similar over a wide range of magnitudes, it produces outcomes completely different from Normal or Gaussian distribution phenomena.” (“Pareto Principle” 2022)
1. INTRODUCTION
Modeling insurance frequency, whether in the context of claims per occurrence (accident) or occurrences per policy, is often a critical part of actuarial analysis. Historically, casualty actuaries have relied almost exclusively on either the standard Poisson or Negative Binomial (NB) frequency distribution, or some variant of these, as evidenced by the number of papers in the Casualty Actuarial Society (CAS) database that reference these distributions, and in recognition of the well-known Poisson/Gamma/NB relationship. Recently there has been increasing interest in alternate models, but for the most part actuaries continue to rely on the NB to model insurance frequency, a flexible two-parameter distribution with known properties.
This paper explores the use of a very different type of distribution known as the Zipf-Mandelbrot law (a.k.a. “Pareto-Zipf” law), a discrete power-law distribution named after linguist George Kingsley Zipf (based on his work regarding “Zipf’s Law”) and mathematician Benoit Mandelbrot who subsequently generalized the distribution formula (“Zipf–Mandelbrot Law” 2021). The two-parameter ZM distribution, which has been successfully applied to many types of “ranked” data (primarily word frequencies in a given body of text; also city populations, corporate revenue sizes, and TV show ratings, to name a few (“The Zipf Mystery” 2015)) uses a simple formula to generate relativities for each “rank” from which probabilities are easily determined (dividing each relativity by their sum).
Using various subsets of insurance frequency data from several lines of business, this paper will show that the ZM distribution can often fit frequency data better (often drastically better) than the NB. At a minimum this should make the case that the ZM distribution is worth considering for modeling a given body of insurance frequency data, but perhaps also gives us better insight into the nature of the underlying insurance claim/occurrence process, suggesting that it may often follow a relativity-based behavior (as modeled by the ZM), rather than an absolute probability-based behavior (as modeled by the standard Poisson/NB). The significant potential of using the ZM to model insurance frequency, in light of the paucity of existing publications on the subject, will hopefully lead to further research.
2. BACKGROUND AND METHODS
2.1. Background
The authors of this paper work at Insurance Services Office, Inc. (ISO, part of Verisk Analytics), and are responsible for (among other things) the maintenance of increased limits factors (ILFs) and deductible discount factors (DDFs) for the various ILF/DDF tables published by ISO. While the ZM could potentially be used to model any type of frequency data for whatever insurance context is required, the data used in this analysis underlies ISO increased limits tables. Frequency distributions are often useful in ILF analyses, such as in simulation programs used to determine the combined effect of limits (per claim/occurrence/policy) and deductibles/retentions, once severity distributions are known.
2.2. Source Data
All distributions used in this analysis are based on statistical data from a large number of insurance companies, as reported under the ISO Commercial and Personal statistical plans (with the exception of Cyber insurance data, which was obtained from an external vendor). Data was summarized to the level of detail typically used (in the specific lines of business that will be discussed) to determine the appropriate claim/occurrence/policy counts, then aggregated to produce the summarized distributions for this analysis.
2.3. Occurrences per Policy
The first type of frequency data analyzed was “occurrences per policy” (per year), using data from General Liability (GL), Cyber, and Medical Professional (MedProf) liability. For these lines of business, as ILF severity distributions are determined on a per occurrence basis (and deductibles/retentions applied per occurrence), and as limits are applied per occurrence and/or per policy, it is necessary to work with frequency models on an “occurrences per policy” basis. Given a total number of policies, a model determines how many policies have N = 0, 1, 2, … occurrences. The zero point is of particular interest, both because it is typically by far the largest (the majority of policies having no occurrences) and because obtaining the zero-count requires merging loss-reported and premium-reported statistical data, which can be challenging.
The large size of the zero point (which can be several orders of magnitude larger than the N = 1 point, depending on line of business) raises the question: should the N = 0 point be included in a given model? The arguments for and against doing so are outside the scope of this research, but to at least address the issue we modeled the NB and ZM distributions for four tables - two for GL [Premises/Operations (PremOps) and Products/Completed Operations (Products)] and two for Cyber [Information Security Protection (ISP) and Commercial Cyber Insurance (CCI)] - both including and excluding the zero point, to examine how the models reacted to excluding the zero point and how the NB and ZM relate to each other under both scenarios. Results are discussed below.
2.4. Claims per Occurrence
The other type of frequency data analyzed was “claims per occurrence” (per year), using data from Personal Auto (PAuto) liability and Commercial Auto (CAuto) liability and physical damage. For these lines of business, ILF severities are modeled on a per claim basis (and deductibles applied per claim), and limits established on a per-claim and/or per-occurrence basis, so modeling “claims per occurrence” frequency is required. Given a total number of occurrences, a model determines how many occurrences have N = 1, 2, 3, … claims. There is no zero point (all occurrences have at least one claimant), and as such frequency distributions can be obtained just from loss-reported data.
2.5. NB Distribution
The Negative Binomial distribution in this analysis uses two parameters “p” and “k.” For N = 0, the probability of the zero point noted as Prob(N = 0) is simply pk, while successive probabilities [Prob (N = 1, 2, 3, …)] are easily determined recursively with the formula:
Prob(N=n)=Prob(N=n−1)∗(k+n−1)∗(1−p)n
General constraints are 0 < p < 1 and k > 0 (note: k was allowed to “float” in the fitting process and was not restricted to be an integer in the fitted distributions; some applications of the NB model require an integer k). The formulas here are used as-is for distributions starting at N = 0, but when starting at N = 1 the probability of the zero point is removed and other probabilities are normalized to sum to 1.0, in a variant known as the Zero Truncated Negative Binomial (ZTNB).
2.6. ZM Distribution
The Zipf-Mandelbrot distribution in this analysis uses two parameters “a” and “b.” For N = 0, 1, 2, …, the relativity of each point is determined by the simple formula:
Rel(N)=1(N+a)b
which uses the same formula for each N. This formula is similar to the basic Zipf formula 1/Nb, but including the “a” term allows the model greater flexibility and also allows the inclusion of the zero point which otherwise would not be possible (the original Zipf formula having been established for ranked data, with ranks starting at 1). The probabilities for each N are simply each relativity divided by their sum. As with the NB, when starting at N = 1 the relativity of the zero point is removed so that other probabilities sum to 1.0. General constraints are b > 1 and a + min(N) > 0 (a > 0 for occurrences per policy; a > -1 for claims per occurrence), though note one article (“The Zipf and Zipf-Mandelbrot Distributions” 2011) mentions specific requirements on the exponent term, for the distribution to be well-defined and for the existence of the mean and variance.
3. RESULTS AND DISCUSSION
3.1. Distribution Tail
One of the issues with real-world insurance frequency data that this research addresses is that such data can have a relatively long “tail” (a policy of a given type may realistically have many claims per occurrence or occurrences per policy). Also, there can be isolated points far out in the tail that have unusually high values (and questionable credibility). For this research we chose three cutoff values for the tail length to be modeled for a given data subset, based on what appeared to be a reasonable value for the given data: N = 50 (General Liability), N = 25 (Cyber, some Medical/Personal Auto/Commercial Auto), or N = 10 (other Medical/Personal Auto/Commercial Auto). Fitting longer-tail distributions is, in general, a shortcoming of the NB and a strength of the ZM.
3.2. Fitting Process
All data fits were done in Excel 365 using Solver (and verified using independent SAS programs). Specifically, using a Maximum-Likelihood approach, parameters were determined for each distribution for which Solver maximized the log-likelihood total, separately for the NB and ZM fits. Appendix B1 shows an example of this (where N starts at 0): for both the NB and ZM, the log-likelihood in each row equals NumPols * Log(Prob), and the total log-likelihood is shown at the bottom of the column. Appendix B2 is similar for the cases where N starts at 1, though the NB probabilities must first be normalized to reflect this, so for the NB in this exhibit, loglike = NumPols * Log(Norm).
We decided that using maximum-likelihood estimates would be our best option to fit distribution parameters as “under certain regularity conditions, the maximum likelihood estimator is the best asymptotic normal (BAN) estimator” (Hogg and Klugman 1984). In some cases, a parameter had to be further restricted beyond what was mentioned above, notably the “k” parameter, for which several fits use a (judgmentally selected) minimum of 1.0E-8. In one instance, Solver could not determine a log-likelihood fit for the ZM, and so parameters were based on minimizing the total absolute error instead. Also, while underlying claim/occurrence counts are exact integers, all other values (fitted parameters, fitted claim/occurrence counts, log-likelihoods, chi-squared values, etc.) are displayed to a fixed precision but retained to their default precision in Excel.
3.3. Fit Quality
In addition to examining the log-likelihood itself, we also checked the absolute error in the number of claims/occurrences for each N, and the total absolute error. One thing that became obvious early on is that what appears to be relatively small differences in the total log-likelihood can be associated with large differences in the total absolute error, which can help determine if there is any meaningful difference in fit qualities. As can be seen in the Comparison Summary (Appendix A), while the percent differences in log-likelihoods for a given table are typically small, the percent differences in total absolute errors are much larger. Almost always, a better log-likelihood corresponds with a better absolute error, with a few counterexamples.
We also determined the chi-squared (χ2) value for each fit, which is simply the sum of the squared absolute error divided by the estimated value, or:
∑(Nfit−Nobs)2Nobs
Chi-squared values are often used to determine if a specified model should be rejected for a given data sample. The higher the chi-squared value, the more likely the model should be rejected. As shown in Appendix A, in almost every case the χ2 value is consistent with other test results (higher for NB than ZM where the ZM looks to be the better model, and vice-versa where the NB looks better). Note that literature on using the χ2 test suggest it may not be appropriate when the expected number of sample observations in any “bucket” is too small (values of 5 or 10 are often cited) and is especially inappropriate if the expected number of observations in any bucket approaches zero, such as for the tails of all distributions included in this research. As such, the chi-squared values calculated here are based upon the first N = 0, 1, 2, … , J claims/occurrences for which there are 5 or more observations. For example, in the Products analysis in Appendix B1, the chi-squared column is based only on data for N = 0 to 20, since the number of observations at N =21 drops to 4.
3.4. Results
One result of our research is that the ZM appears equally suitable to occurrences per policy or claims per occurrence. We observed good results from the ZM in either frequency context, which was encouraging. More specific results for the lines of business used in this research are as follows.
3.4.1. General Liability
PremOps and Products distributions were examined, using multistate incurred occurrence data for 10 loss years (2005 - 2014). GL ILF tables are typically broken down into PremOps 1/2/3 and Products A/B/C based on relative severity of losses (Tables 1 and A contain the lowest average severities while Table 3 and C contain the highest) - this analysis used data for individual PremOps and Products tables and for all tables combined. These were the first distributions examined for this analysis, and the significant improvement in fit quality from the ZM (about 59% reduction in total absolute error for PremOps, and 75% for Products) spurred further research on this project. The particularly long tail for GL (especially for PremOps) well illustrates the ability of the ZM to model such a tail.
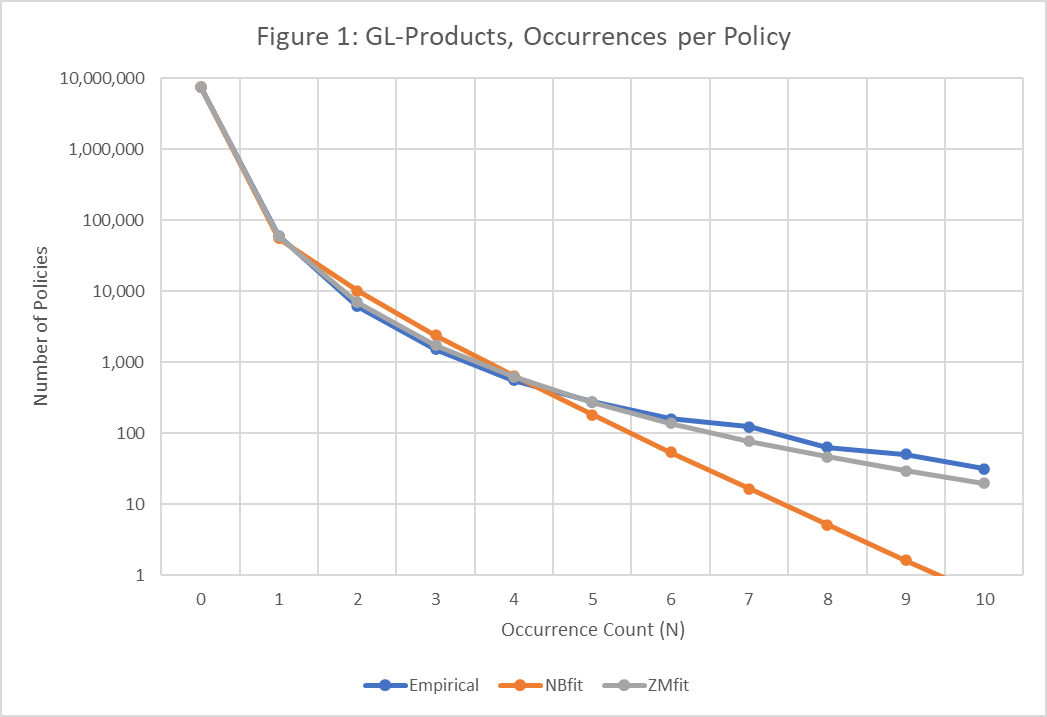
Appendix B1 shows for example the empirical frequency (occurrences per policy) for Products (all tables combined), and the results of the NB and ZM fits, to illustrate the structure of our analysis for each distribution and give a basis for comparisons. For this long-tail distribution (typical of GL), the ZM gives a 0.84% improvement in the total log-likelihood (-436,508 versus -440,205) and a large 75.3% reduction in the total absolute error (2,482 versus 10,058). The bulk of the improvement appears in the “low” range of counts (up to about N = 3), where though the ZM fit at the N = 0 point is marginally worse than the NB fit, the ZM drastically improves upon the NB at the N = 1, 2, 3 points. The improvement of the ZM continues into the “midrange” (from about N = 4 to 10), where the natural drop-off in the NB tail becomes evident while the more gradual reduction in the ZM tail better follows the empirical data. For the “high” range (N = 11 and up), the NB gives a (rounded) count of zero occurrences for all points while the ZM does not become zero until N = 26. Results for PremOps were generally similar: while an isolated fit point may be somewhat worse using the ZM instead of the NB (at some low N value; 2 or so), fits at the majority of N values for GL are notably better for the ZM than for the NB, for all GL tables individually and combined.
Figure 1 illustrates a closer fit using ZM distribution compared to the NB fit, for Products. Using points N = 0 to 10 (occurrences per policy), the figure highlights the over-projection of the NB fits at the N = 2, 3, 4 points, and starting at N = 5 the drop-off in the NB fits as being progressively too low. The ZM fits seem to follow the empirical behavior much better, indicative of a more appropriate model. Policy counts are shown on a log scale to accommodate the range of counts. The linear behavior of the NB (on a log-scale) also seems very inappropriate for this body of data, whereas the shape of the ZM data seems to better correspond with the natural shape of the empirical data.

The fits for General Liability (both PremOps and Products), with and without the zero point, highlight an interesting difference between the NB and ZM models here. When removing the very large zero point from the fit, one might expect that the model would take advantage of that to better fit the remaining points. The ZM model did just that as shown in Appendix A1, with large reductions in the total absolute error (all-tables-combined PremOps went from 23,330 to 13,884 when excluding the zero point; Products from 2,482 to 601). The NB model barely reacted to excluding the zero point, with a small reduction in absolute error (56,836 to 53,649 for PremOps; 10,058 to 9,751 for Products). This difference in how the models react to excluding the zero point is also evident in the Cyber results, though to a lesser extent. It is not clear what this implies about the relative merits of the models used and/or the related issue of whether the zero point should be modeled or not - a few aspects of this research that make this ripe for future analysis.
3.4.2. Commercial Auto Liability
There are 18 tables shown here using the usual ILF breakdown: 8 state groups, and all state groups combined, for Trucks/Tractors/Trailers (TTT) and for Private Passenger Types (PPTypes). For Commercial Auto liability, the current state group structure was determined through analysis of the empirical severity distributions for each increased limits table and jurisdiction, with the jurisdictions organized into distinct clusters based on the magnitude of their empirical increased limit factors. Paid claim data used for this frequency research is for 4 loss years (2015 - 2018). For all these tables, the ZM models the underlying claims per occurrence data much better than the NB with large reductions in total absolute error. For every table, the k parameter is very low (usually using the low bound of 1.0E-8), suggesting that this data is pushing the limits of what the NB can model and may not be appropriate. Absolute errors for the ZM are often very low across all N values.
For example, Appendix B2 shows the Commercial Auto liability data for state group 2. This exhibit and the illustration in Figure 2 (for N = 1 to 10) again show the tendency of the NB fit to over-project at low values (for N = 2, 3) and to under-project at medium to high values (for N > 3 in this case). This is like what was seen in the GL illustration, and again shows the ZM fit to better follow the empirical data, with a much better overall fit quality and a strong indication as a more appropriate model.
__claims_per_occurrence.png)
As shown in Figures 1 and 2 (with frequencies displayed on a log-scale), it is interesting to note that while the NB graph appears highly linear (with the resulting under-projection of frequencies for higher N values), the empirical data and the fitted ZM frequency show more of a curved (Pareto-ish) behavior, which could further serve as the basis for a simple test of what distribution type might be applicable for a given body of data.
3.4.3. Cyber
For Cyber we also have two multistate distributions but separated by policy type: ISP for medium to large size risks (based on revenue), and CCI for small to medium size risks (data for medium size risks is included in both distributions). This paid occurrence data was obtained from an outside vendor, in sufficient detail to enable determining occurrences per policy. Capping N at 25, the ZM fits are again significantly better than the NB fits, with reductions in absolute error of almost 80% for both ISP and CCI. The ZM fits for Cyber look particularly good across all N counts. As noted above, Cyber data was fit with and without the zero point, to examine fit quality for both cases and to examine model reaction to excluding the zero point.
3.4.4. Medical Professional Liability
We examined distributions for each medical ILF table (Hospitals, Physicians, Surgeons, Dentists, Nursing Homes, and Allied Health). In addition to occurrence distributions based just on paid indemnity data (that may or may not have ALAE associated with them), we also examined Medical distributions reflecting indemnity and ALAE-only incidents combined (adding in ALAE-only paid “occurrences” for which no indemnity was reported). As such there are 12 distributions for Medical, using multistate data for 10 policy years (2009 - 2018). The general pattern is that the ZM has a better log-likelihood and a notably lower absolute error than the NB, with a few counterexamples (Surgeons with ALAE is interesting, as the ZM has a better log-likelihood but the NB has a 10% lower absolute error).
3.4.5. Personal Auto Liability
There are 14 distributions here, 6 for the Tort ILF state groups (1 to 5, and combined) and 8 for the No Fault ILF groups (1 to 7, and combined). For Personal Auto liability, the current state group structure was determined through analysis of the empirical severity distributions for each increased limits table and jurisdiction, with the jurisdictions organized into distinct clusters based on the magnitude of their empirical increased limit factors. Note some groups shown in this research are not typically included in ILF material published for Personal Auto. Paid claim data is based on 8 loss years (2009 - 2016). The pattern here is quite interesting and was unexpected: the NB distribution generally does a better job modeling the Tort state group data, while the ZM is generally better on the No Fault data. This is not an absolute rule, as Tort-1 shows better results using the ZM and No Fault-3 looks better using the NB. The results suggest the possibility of claim patterns being inherently different between Tort and No-Fault states, as one might expect. Why ZM seems to outperform NB for No-fault but not for Tort is an interesting topic for further investigation.
3.4.6. Commercial Auto Physical Damage
For Commercial Auto we have four multistate tables for physical damage, broken down by Collision (Coll) and Other Than Collision (OTC), for TTT and PPTypes. Paid claim data is for the same 4 loss years as liability. The interesting pattern here is that the shorter-tail Collision coverage is better modeled by the NB while the longer tail OTC is better modeled by the ZM, often with large differences in total absolute error. This appears similar to what was seen in Personal Auto, where the different distributions may be better suited to claim patterns that are inherently different (by coverage type in this case, rather than state/group). Note that negative “a” values were required to obtain good ZM fits for OTC data (a > -1 when N starts at 1). Also, for PPTypes-Collision, a maximum log-likelihood could not be determined for the ZM distribution, and so a minimum absolute error criterion was used instead.
3.5. Holdout Data/Overfitting
For each table analyzed, all available data was used to determine empirical frequencies and resulting fits. As such, we did not set aside any “holdout” data to possibly address questions of how well the models would fit the holdout data, to investigate potential overfitting. However, as we did use a Maximum Likelihood procedure to fit all models (for which the ZM had a better log-likelihood the majority of the time), and as both the NB and ZM use two parameters, it follows that the various “information criteria” in common use (AIC, BIC and the like) would all suggest that the ZM model is the better fit most of the time, and is not overfitting. Such information criteria are based on the maximum likelihood value from the fit in question, and add a penalty based on the number of parameters used for the model (a moot point when comparing models that have the same number of parameters).
4. CONCLUSIONS
4.1. Why ZM
As noted in the Abstract and as discussed in several references, the ZM model is a simple “power law” formula (a.k.a. discrete Pareto distribution) that seems to underlie the behavior of many natural and manufactured phenomena, which (as this paper establishes) includes insurance claim/occurrence frequency. A key question is - why? What is it about the claim/occurrence process that in many/most cases may cause it to follow a ZM relativity behavior? We cannot definitively answer this, but we do offer some thoughts. One has to do with the concept of “preferential attachment” (known by several names: the “Yule process,” more commonly “the rich get richer,” etc.), an idea by which (in an insurance context) those policies that have already had claims/occurrences are more likely to have successive ones, which may “generate a long-tail distribution following a Pareto distribution or power law in its tail” (“Preferential Attachment” 2022). It would seem this is closely related to the Pareto Principle, commonly known as the “80/20” rule (“Pareto Principle” 2022).
A separate but related idea may be “the principle of least effort,” which is “the theory that the ‘one single primary principle’ in any human action, including verbal communication, is the expenditure of the least amount of effort to accomplish a task” (“The Principle of Least Effort: Definition and Examples of Zipf’s Law” 2019). Initially used to analyze the development of language, the principle has been extended to examine human use of other resources such as electronic devices/services, and human behavior following this principle could naturally lend itself to a ZM model. In this context, it is interesting to perhaps think of an insurance policy as another potential resource, use of which might follow a ZM model.
4.2. ZM Advantages
We note a few apparent advantages of using the ZM distribution compared to (or perhaps when used in conjunction with) the NB:
-
It may, in theory, be the more correct model in many situations (or closer to it than other models), based on concepts regarding underlying human behavior.
-
It often does a better job (typically a much better job) fitting the underlying data.
-
It has an inherently longer tail than the NB, which can better reflect actual claim/occurrence data.
-
It has a simple function form across all values, which makes it easier to work with than the NB.
-
Using it in combination with NB may help identify inherent claim/occurrence pattern differences, and may help better understand the “true” nature of claim/occurrence process, or help identify data that warrants further analysis (such as atypical claim/occurrence patterns or fraud investigation).
4.3. ZM Disadvantages
A few apparent disadvantages of using the ZM distribution compared to the NB:
-
It gives relativities, not probabilities. One cannot easily determine various statistics (mean, variance) of ZM given its parameters, as can be done with the NB.
-
Modeled parameters may be more sensitive to (judgmentally selected) tail cutoffs than standard models.
-
ZM may not have understood theoretical relationships to other distributions as NB does, such as the well-known Poisson/Gamma/NB relationship).
-
Big issue: No existing research on the ZM model in an insurance claim/occurrence frequency context. We could find nothing in the CAS database or from Internet searches.
This paper focused on comparing two (dual parameter) frequency distributions: the traditional NB distribution against the seemingly unknown ZM distribution, which often performs better. It is the hope of the authors that this paper raises awareness of the ZM distribution and the potential benefits of its usage in an insurance context.
.png)
.png)
.png)
__4_loss_years_2015_-_2018.png)