




1. INTRODUCTION
Bootstrapping is a useful and popular method for evaluating the possible distribution of ultimate payments related to Casualty loss reserves.
The nature of insurance is a promise to pay losses that have not yet happened; but even after events have occurred it is not known exactly what the ultimate amounts will be. This means that the reserves set aside to pay claims are only an estimate of the “true” ultimate amount and there is a need to evaluate how much the actual payments could differ from the estimate at any point in time.
Bootstrapping, especially popular after the 1999 paper by England & Verrall, provides a useful tool to evaluate this volatility. It involves simulating a large collection of pseudo triangles – resampled variations of the original data – and then displaying the range of outcomes from those simulations. It is easy to apply and almost as easy to explain to a nontechnical audience.
The difficulty arises in practice that the reserve ranges produced by the bootstrapping method can be unreasonable: sometimes too narrow to contain observed outcomes, and sometimes creating incredibly wide ranges due to distorting outliers. These problems are due, in part, to the “small sample” nature of working with highly aggregated data. But they are also a consequence of the simplifying assumptions of techniques like the chain ladder method.
Our paper will look at a way for modifying the bootstrapping method to help produce more reasonable reserve ranges. A central idea will be relaxing the independence assumption in the resampling. The proposed ideas are illustrated using a publicly available database of reserving data and are shown to improve the resulting reserve ranges.
1.1 Research Context
The discussion about the bootstrap method in quantifying the variability in casualty loss reserve estimates was first mentioned by Ashe (1986) but became popular with the paper “Analytic and bootstrap estimates of prediction errors in claims reserving” by England and Verrall (1999). This paper introduced the bootstrap technique by specifying an appropriate residual definition to provide a method that can obtain reserve prediction errors. As the author mentioned, the over-dispersed Poisson (ODP) bootstrap of the chain-ladder method has become a widely used method to estimate the reserve range. However, the distribution obtained by the ODP bootstrap tends to underestimate reserve risk based on the results of the paper “Back-Testing the ODP Bootstrap of the Paid Chain-Ladder Model with Actual Historical Claims Data” by Leong, Wang, and Chen (2014). The authors back-tested the ODP bootstrap model using paid data with several lines of business and identified that the deviation is likely driven by systematic risks, such as, future trends or market cycle, which cannot be observed from historical data.
Another paper that conducted the back-testing on the bootstrap method is “Back-Testing the ODP Bootstrap & Mack Bootstrap Models” by Shapland (2019). That paper had several objectives. One focus was expanding the database used to back-test models. It provided additional credible evidence to validate previous research. Another idea the author described is combining regression results to derive a benchmark algorithm, which could reflect the independent risks in the data. There is another paper from Shapland: “Monographs No. 04: Using the ODP Bootstrap Model: A Practitioner’s Guide” (2016). The author introduced a parametric model in the bootstrap method. That makes the model flexible enough to capture the statistically relevant level and trend changes in the data without forcing a specific number of parameters.
In this paper, we also performed back-testing using our data to replicate the Leong paper’s results and provided more evidence of the underestimation of the reserve distribution. The England and Verrall approach to bootstrapping (and GLM) had three main assumptions:
-
Ultimate losses are estimated using the all-year dollar-weighted average chain ladder method.
-
Each cell in the incremental development triangle has the same variance-to-mean ratio. The mean (expected incremental loss) is assumed to be strictly positive.
-
Each cell in the incremental triangle is statistically independent from the others.
All of these assumptions can be relaxed in practice. For the present paper, we will look at the third of these assumptions and allow for correlation along the calendar year diagonals of the triangle. Diagonal effects have typically been ignored, as Ashe described:
“No attempt is made to model slight departures from the independence assumption when refitting the residuals in the simulation. An example of such a slight departure is when we observe a set of payments in one calendar year which may all be below the fitted values. We may not wish to model this feature of the data as there may be no convincing explanation of the phenomenon and therefore no way of predicting its possible recurrence.”
1.2 Objective
The goal of this paper will be to propose modifications to the bootstrapping method in loss reserving to produce more reasonable ranges of possible outcomes.
1.3 Outline
Section 2 of the paper outlines the data and methods. First, Section 2.1 describes the publicly available Schedule P data used to illustrate the ideas. We describe some of the “fixes” needed to handle outliers such as negative loss payments. Section 2.2 describes the bootstrapping method itself, including a parametric version. Section 2.3 introduces the concept of correlation across the diagonals.
Section 3 shows the results of applying these ideas to the publicly available Schedule P database. Histograms of the how the actual results fell within the estimated ranges are provided, comparable to the format given in Leong, Wang, and Chen (2014). These graphs show that the improved reserve ranges better capture the actual loss payments.
Section 4 gives concluding comments and suggests future research in the many ways that these ideas could be expanded further.
2. BACKGROUND AND METHODS
Before discussing the bootstrapping method and extensions, we give a description of the Schedule P data set. There are some triangles included in this data with some distorting properties – but all characteristics that are encountered in real data sets – so they are worth examining before proceeding with the examples.
Sections 2.2 and 2.3 then describe the methods applied on the data.
2.1 Description of the Data
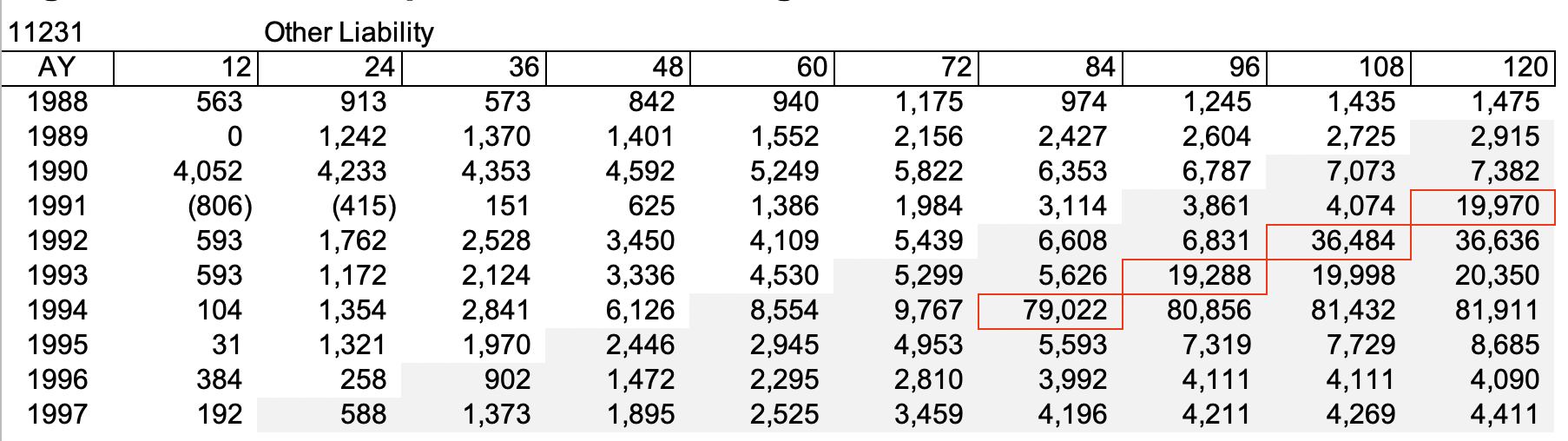
The back-testing is based on the Schedule P net paid loss & LAE triangles by line of business and by company for the accident years 1988-1997, which is published on the Casualty Actuarial Society website.
There are three lines of business, for which the CAS database contain more than 100 companies. These are Commercial Auto Liability (CAL with 158 companies), Other Liability (OL, with 239 companies) and Workers’ Compensation (WC, with 132 companies).
We have cleaned the data by excluding those companies that have fewer than 10 accident years of data or that have shown obvious data abnormality. For example, the triangle for the company (NAIC #38997) on the left in Figure 2.1.1 shows little or no loss development after Age 12 and the company (NAIC #86) on the right shows significant loss development along the financial year 1996, which doesn’t appear to be normal development but is likely the result of a reinsurance/pooling arrangement such as a loss portfolio transfer. They are therefore excluded from our data.

On the other hand, to avoid data overcleaning, we have kept those companies for which some data issues may be observed but do not exhibit the systemic problems observed in Figure 2.1.1. For example, in each of the two triangles in Figure 2.1.2, the business volume seems to have changed significantly over time and in addition, each has some areas where there appears to be abnormal development. Otherwise, the later accident years seem to exhibit normal loss development. So they are included in our analysis.

Take another example, for the company in Figure 2.1.3, the triangle itself is normal but there are significant loss payments during 2000 for accident years 1991-1994, which could be driven by a loss portfolio transfer. This company is included in the analysis so that our dataset for back testing would include reasonably extreme but realistic scenarios as well.

After the data cleaning, there are 89 companies that remain for CAL, 125 companies for OL and 59 companies for WC. The list of firms that are included for the analysis can be found in Appendix A.
2.2 Summary of Bootstrapping Method
The ODP bootstrap of the paid chain-ladder method, as described in England and Verrall (1999) and England (2002), is one of the most popular methods to model reserve distributions. A number of variations to the ODP bootstrap method have also appeared in the insurance literature. Below we discuss the ODP bootstrap model and one of its variations.
2.2.1 Nonparametric in GLM based on England and Verrall
The main definitions given in England and Verrall are:
Ci,jactual incremental loss in year i and development age j
mi,jfitted incremental loss in year i and development age j
The ODP model assumes that the variance for the distribution of incremental losses is a constant multiple of the mean. This multiple is represented by a dispersion parameter
E(Ci,j)=mi,jVar(Ci,j)=ϕ⋅mi,j
An estimate of the dispersion parameter can be made, assuming n=55 for the ten-by-ten triangle and the number of parameters p=19 as in the ODP model.
ϕ≈1n−p⋅n∑i,j(Ci,j−mi,j)2mi,j
Unscaled Pearson residuals are calculated from the original triangle and the expected values. Resampled points for the bootstrap are random draws (with replacement) from these residuals.
ri,j=Ci,j−mi,j√mi,j
One problem with this procedure in practice is that fitted incremental loss can be negative, zero or close to zero. These values can then create unstable residuals.
We can adjust the formulas, so that the results are more stable. We use the absolute value of the fitted increment, and also constrain the amount to be greater than some selected minimum
ri,j = Ci,j−mi,j√MAX(ABS(mi,j),δ)
The incremental losses in the resampled or pseudo triangles are then estimated as follows (the asterisk represents a resampled value).
C∗i,j=mi,j+r∗⋅√MAX(ABS(mi,j),δ)⋅√nn−p
While this adjustment to the formulas allows the bootstrap to proceed, it can still create poor ranges due to the unbalanced nature of the values (i.e. the actual incremental development is often zero or a small value with a large development in only a few cells) (e.g. NAIC #38997, Other Liability and NAIC #23663, Other Liability shown above in Figures 2.1.1 and 2.1.2).
This unbalanced nature is especially a problem when working with small samples. A ten-by-ten triangle with only 55 points to estimate 19 parameters is a small sample. This is where parametric bootstraps can help. Good and Hardin (2003) recommend use of parametric bootstrap when the number of observations is less than 100. Björkwall, Hössjer, and Ohlsson (2009) give more discussion of parametric and non-parametric methods in loss reserving; they show that parametric methods are useful in stabilizing results in small triangles, but they do not have a significant effect on the final ranges.
2.2.2 Parametric Bootstrap
With a parametric bootstrap we begin with the same assumptions as in the nonparametric method outlined by England and Verrall that the variance is a constant multiple of the mean.
For the resampling, we do not draw directly from the actual residuals but rather from a selected distribution centered around the fitted values
For example, we define a lognormal distribution with mean of one and a coefficient of variation based on the fitted model and dispersion parameter.
ϕ ≈ 1n−p⋅n∑i,j(Ci,j−mi,j)2MAX(ABS(mi,j),δ)
The sigma and mu for the lognormal can be selected so that we match the coefficient of variation in each cell of the triangle.
σ2i,j=ln(1+CV2i,j)=ln(1+ϕMAX(ABS(mi,j),δ))
μi,j=−σ2i,j2
βi,j ∼ lognormal(μi,j,σ2i,j)E(βi,j)=1
The resampled incremental losses are calculated as:
C∗i,j=mi,j⋅β∗i,j
The mean and variance of the sampled points approximate the ODP assumptions.
E(mi,j⋅β∗i,j)=mi,jVar(mi,j⋅β∗i,j)=ϕ⋅m2i,jMAX(ABS(mi,j),δ)
The lognormal is chosen here only because it behaves well in practice. Other distributions could be selected if believed to be more appropriate by the analyst. For example, the Shapland Monograph suggests using the Gamma distribution.
2.3 Including Correlation Structure
The assumption of independence between the cells of the development triangles is difficult to measure due to the high variability of the data. However, it is not difficult to impose an assumed correlation structure upon the data in the simulation. This is done via a Gaussian copula simulation of correlated random variable (see Wang 1998).
The idea of a copula is that we can represent a multivariate distribution as a combination of the univariate marginal distributions and a copula function C, which determines the dependence structure. It allows the marginals and the dependence to be treated separately.
F(x1,x2,⋯,xd)= C(F1(x1),F2(x2),⋯,Fd(xd))
For the bootstrap application, this separation of marginal distributions from the dependence means that the correlation structure does not affect the means or variances of individual cells in the triangle.
In order to estimate the correlated random variables, we need to first estimate a correlation matrix representing all the cells in the triangle. We will assume that correlation follows a calendar year structure (other choices could be used), such that cells along the same diagonal are strongly correlated with each other and that the strength of the correlation decreases for more distant diagonals.
To illustrate this idea, consider a triangle with only four diagonals. We will assume that the correlation coefficient (rho or between cells on the same diagonal is 0.5, and that this correlation coefficient reduces multiplicatively etc.). This assumption could be described as “block autoregressive” and only requires a single number as input from the user.
For example, as figure 2.3.1 shows, for the calendar year 1991, the correlation between the latest diagonal cells is 0.5. (CY 1991 Age 12, CY 1990 Age 24, CY 1989 Age 36 and CY 1988 Age 48). The correlation between the diagonal cells at CY 1991 and CY 1990 is 0.25. The correlation between the diagonal cells at CY 1991 and CY 1989 is 0.125. To help better understanding, figure 2.3.2 shows the same correlation matrix when is 0.1.
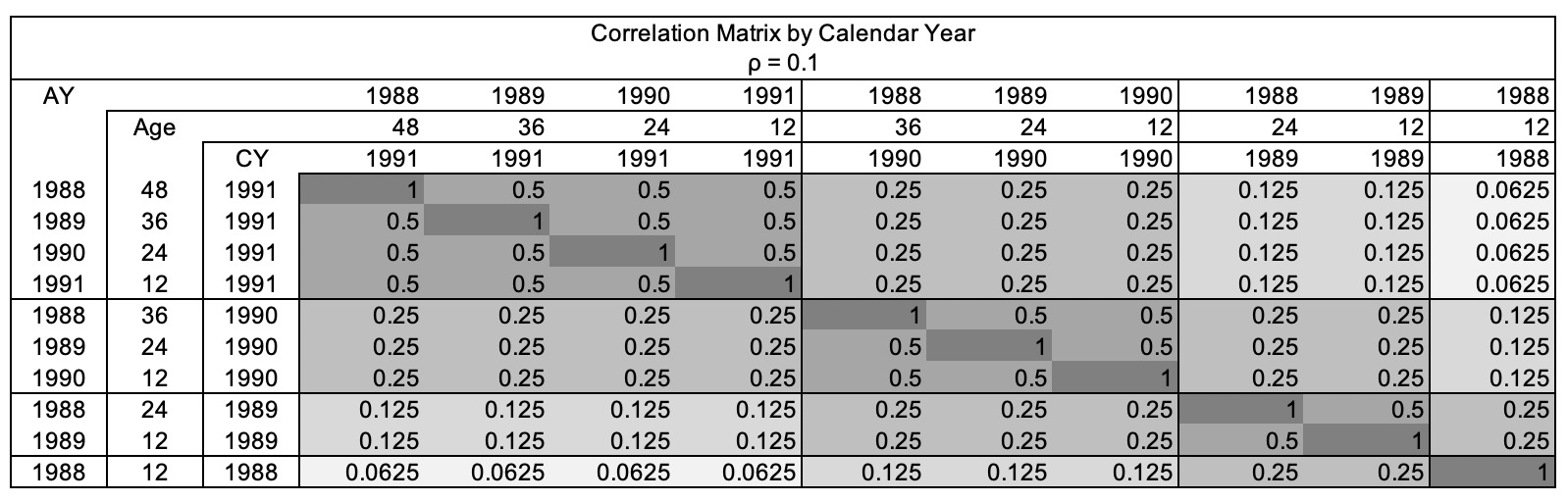
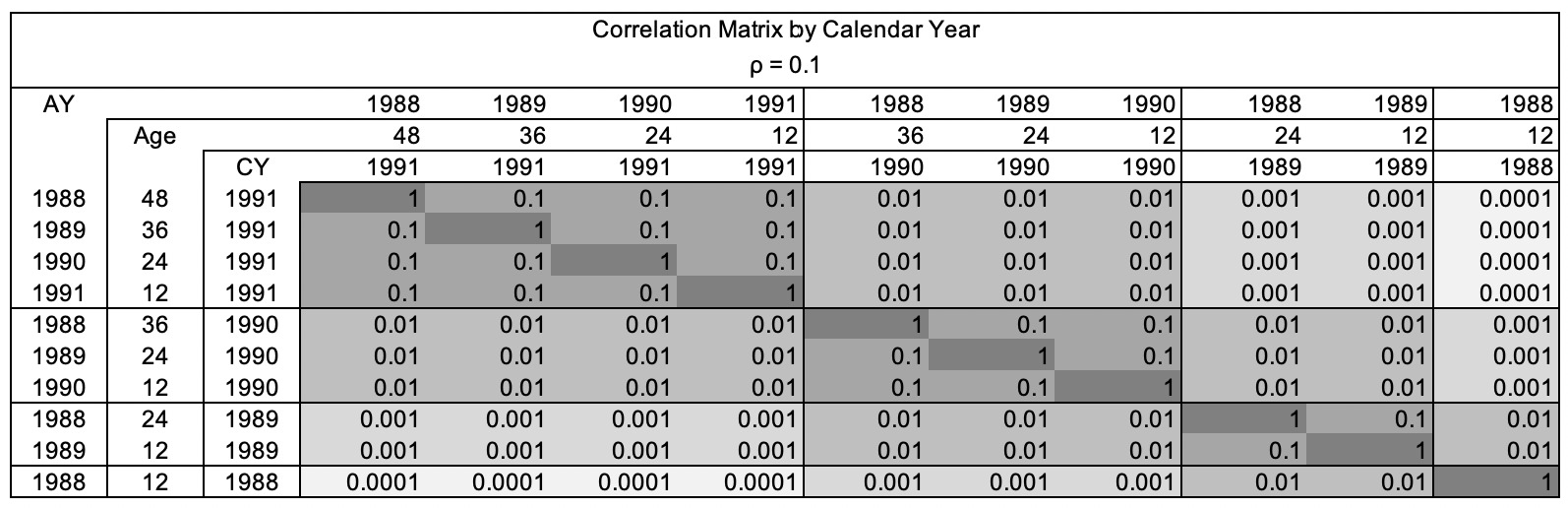
A four-year triangle will have ten cells, and will therefore require a ten-by-ten correlation matrix. The accident year effects move down the rows and the calendar year effects move along the diagonals.
The correlation structure is suggested by economic time series analysis of inflation. Inflation can be modeled as a mean-reverting random walk, or AR(1) autoregressive process, which is a discrete-time analogue of the Ornstein-Uhlenbeck process in continuous time (see Ahlgrim, D’Arcy, and Gorvett (2005) for details).
The block autoregressive structure used here is similar to an assumption that calendar year effects are due to inflation following an AR(1) process. Gluck and Venter (2009) give a more extensive survey of models reflecting inflation risk and note: “unrecognized time series behavior in casualty payment trends can significantly contribute to reserve risk.”
The calendar year diagonal correlation could be due to factors other than changing inflation: effects from pandemics, changes in claims-handling, case reserve adequacy, or settlement strategies, etc.
Given a matrix of correlation coefficients, the Gaussian copula will create random numbers between 0 and 1 for each cell, from which we can simulate “pseudo” incremental losses that are approximately correlated. This additional step is inserted in each bootstrap simulation. If a correlation of zero is selected, the model will reproduce the standard bootstrap model with independence assumptions.
3. RESULTS AND DISCUSSION
The back-testing analysis follows work in Leong, Wang, and Chen (2014) and Shapland (2019). For each company in the Schedule P database, we first estimate the bootstrap range of possible outcomes and then determine the quantile in which the actual subsequent losses fell.
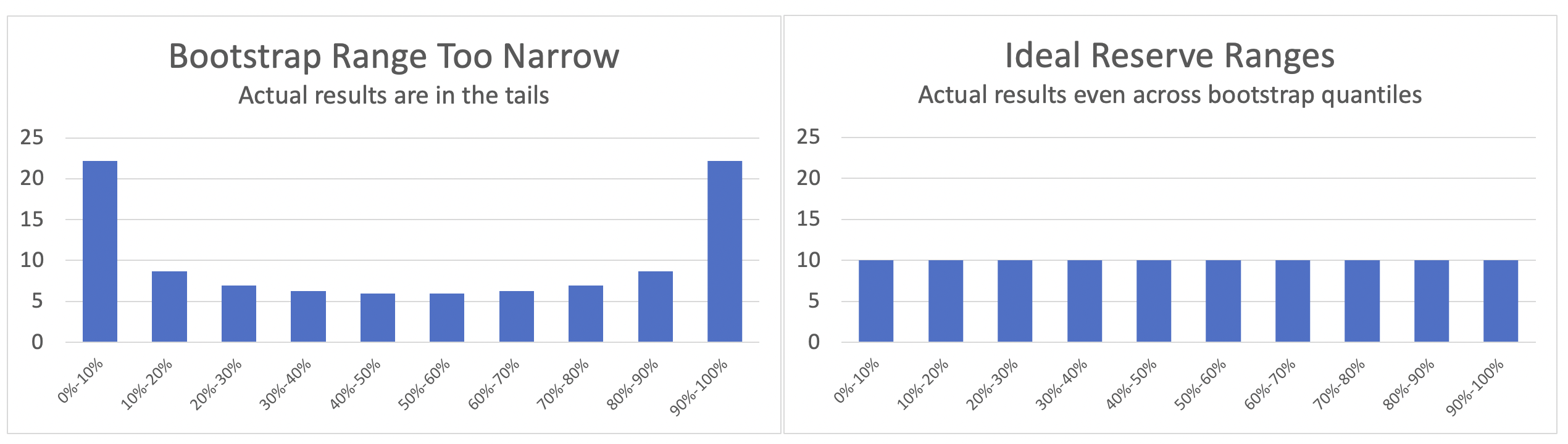
Ideally, about 10% of the companies should have actual losses that fall in the first decile (0%-10%) of their bootstrap range. The histogram of actual results should look flat or uniform. When the actual results fall into the tails of the bootstrap range, the histogram displays a “bathtub” shape; this indicates that the bootstrap range was too narrow.
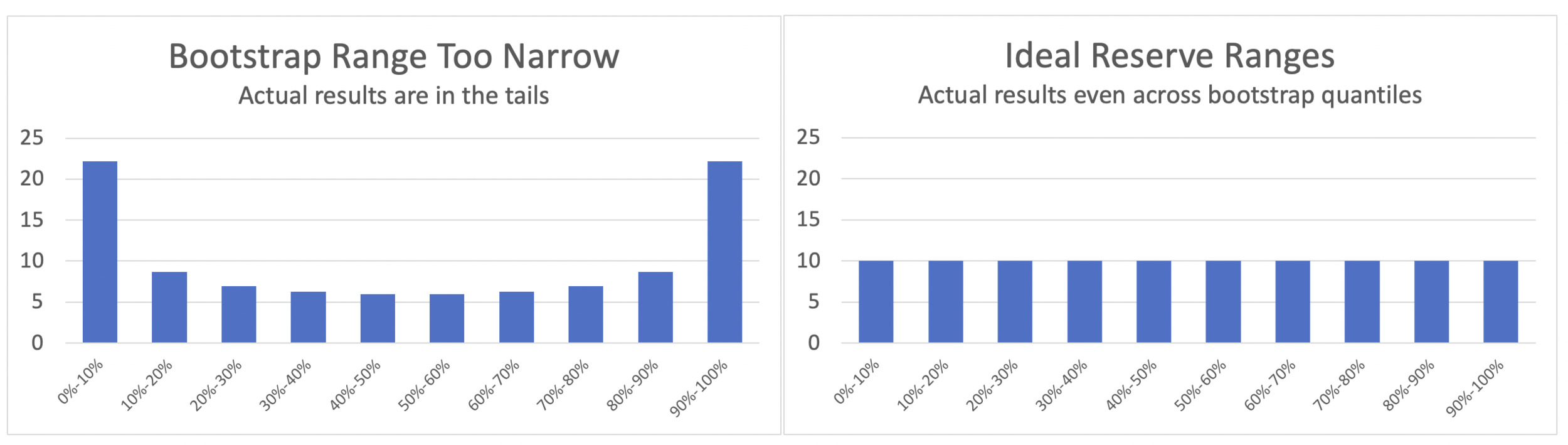
The Schedule P database confirmed the prior back-testing result that the bootstrap range using an independence assumption was more likely to produce the “bathtub” shape, indicating a range that was too narrow to reflect the actual outcomes.
The histograms below show the results from the bootstrap ranges using the independence assumption on the left. The results on the right show how the actual results fell when the bootstrap range included the correlation structure.
For all three lines of business that we tested, the deciles of actual unpaid losses become more evenly distributed after the correlation structure is introduced into the bootstrap process. Taking Other Liability as an example, before introducing the correlation structure, 18% of the companies fell into the lowest 10%-tile and 21% of the companies fell into the upper 10%-tile. After including the 0.5 correlation, it can be seen that some of the companies that had been in the tails of the independence bootstrap were better distributed in other deciles. In the bootstrap range that included correlation, 11% of the companies fell into the lowest 10%-tile and 15% into the upper 10%-tile.
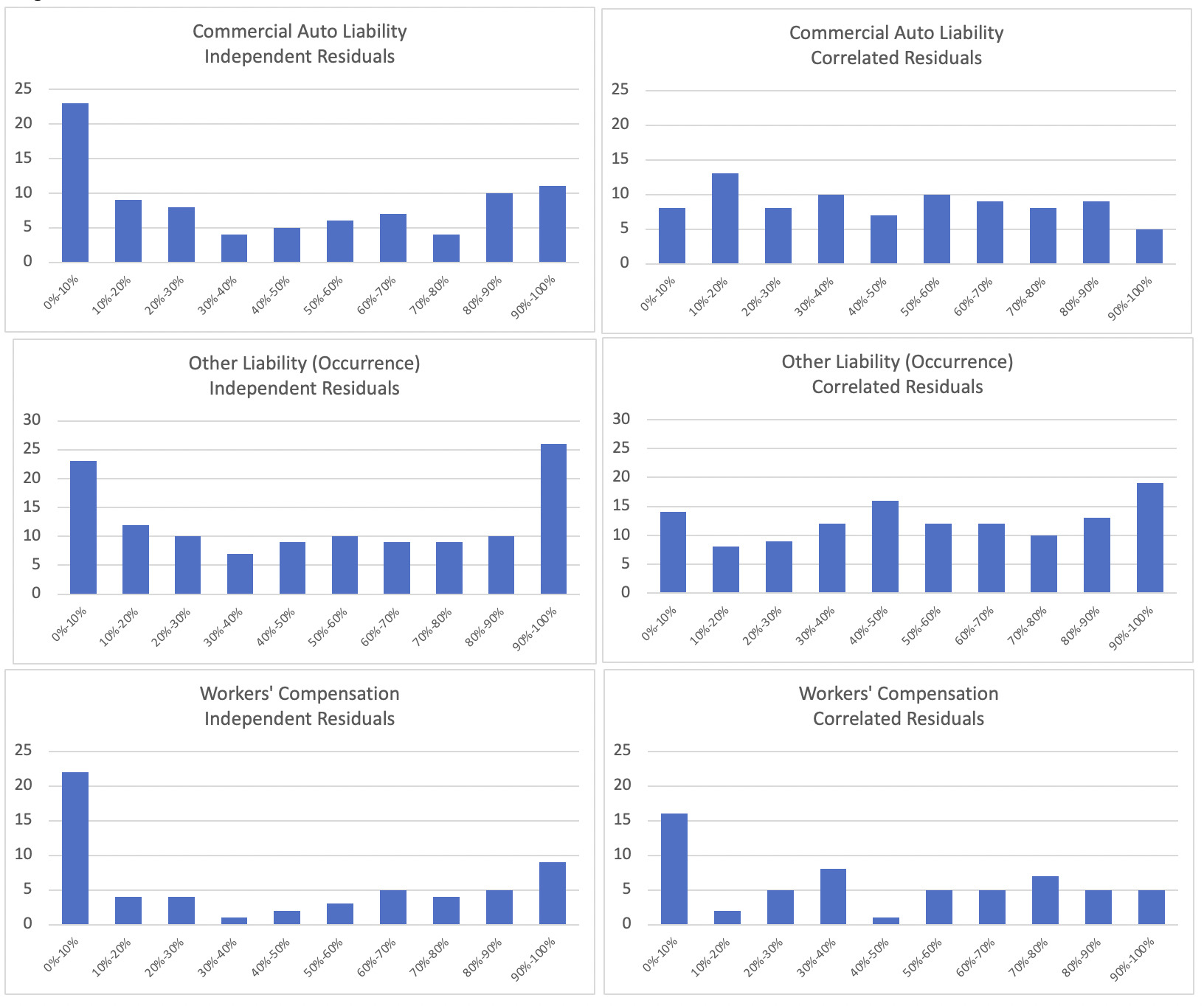
Including correlation in the bootstrap produced more reasonable ranges for the Schedule P data set. The block-autoregressive structure with 0.5 correlation worked well.
There is much more that can be done with this concept but the improvement in this “back-testing” encourages more research in this direction.
4. CONCLUSIONS
4.1 General Conclusion
Our review of the publicly available data from Schedule P showed that a naïve application of bootstrapping can lead to unrealistic ranges; this is consistent with prior studies by Leong, Wang, and Chen (2014) and Shapland (2019). We applied some adjustments to the data to overcome the small sample problems. The introduction of a correlation structure improved the final ranges.
4.2 Future Research
This paper examined ranges of future payments using the all-year dollar-weighted average chain ladder estimator, which assumes all accident years have the same development pattern and that each cell of the incremental triangle is independent. A correlation structure allows us to relax these assumptions.
In practice, reserving actuaries recognize that development patterns do change over time, and they therefore give more weight to the latest diagonals. That is, they assume that future points will be more similar to the latest calendar year diagonals than to older calendar years.
The choice of the estimator (e.g., more weight given to latest diagonals), and the correlation structure should be related. An auto-regressive correlation structure is a mean-reverting random walk; meaning that the forecast is an average of the latest data and the long-term average. For our example, we have used a simple guess for the correlation structure that can easily be changed to test sensitivity.
While difficult to estimate, every model does make an assumption about correlation: even if we set up a model that “ignores” correlation we are implicitly making an independence assumption.
The inclusion of correlation can also be done analytically, rather than with simulation. Generalized Estimating Equation (GEE) (Hardin and Hilbe 2013) methods are a natural way to expand a GLM to include a correlation matrix in the weighting function.
Acknowledgment
The authors acknowledge the helpful reviews provided by Diana Rangelova, Ulrich Riegel and James Sandor.
Supplementary Material
The data from Schedule P has been published on the Casualty Actuarial Society website.
Abbreviations and notations
CL, chain ladder method
GEE, generalized estimating equations
GLM, generalized linear models
ODP, over-dispersed Poisson