




1. Introduction
The explosive growth of large language models (LLMs) has outpaced even the most optimistic predictions. Yet, despite their widespread adoption, much of the public discourse remains fixated on high-profile consumer applications—such as ChatGPT or AI-driven customer service—leaving actuaries to question how these technologies can be practically applied to insurance and risk assessment. While actuaries have long relied on traditional machine learning approaches for pattern recognition and risk modeling, LLMs offer unique capabilities that may be particularly well suited to addressing long-standing challenges in actuarial science.
LLMs offer powerful solutions for unifying disparate data sources by synthesizing information that was previously too fragmented or unstructured for effective analysis. This is particularly valuable in actuarial work, where sparse data present a fundamental challenge. Unlike widely adopted models—like generalized linear models (GLMs), regressions, or decision trees—which rely on structured numerical data, LLMs excel at processing unstructured inputs such as policy documents, claims narratives, or adjuster notes.
By extracting key details from these text-heavy sources, LLMs can enrich traditional risk models in ways that were previously impractical. For example, they might identify nuanced policy terms or locate subtle risk factors hidden within adjuster notes, then convert those findings into features compatible with established techniques such as GLMs or decision trees. This could provide actuaries with a more holistic view of risk drivers, potentially leading to more accurate risk assessments and pricing strategies.
However, since LLMs are inherently stochastic and their inner workings often opaque, incorporating them presents its own set of unique challenges. The “black box” nature of these models contrasts sharply with the transparency traditionally valued in actuarial work. Consequently, effective use of LLMs requires a nuanced understanding of both their capabilities and limitations; additionally, new methodologies are needed to ensure reliability.
1. New solutions for old data challenges?
The enterprise data landscape is characterized by extensive, yet underutilized data warehouses. Organizations continue to invest heavily in collecting proprietary structured data, fueling a thriving industry of machine learning (ML) consultancies that specialize in building custom models atop these isolated data stores. Despite significant investments in both data collection and model development, practical business value often remains elusive.
Historically, the challenges of deriving value from enterprise data were not just organizational—they were also deeply technical. At the heart of the problem lay the fundamental limitations of information retrieval technology. While information retrieval has a long history, the core methodologies remained largely stagnant for decades, relying on traditional term-based approaches until the recent advancements in deep learning (Hambarde and Proença 2021).
These methods, though functional, had clear limitations. Chief among them was an inability to grasp language’s inherent complexity. Search systems operated on literal text matching, blind to the rich web of meanings and relationships humans naturally understand. A query for vehicle would fail to surface relevant content about automobiles or cars, while a search for data analysis might miss crucial documents about statistical modeling. While some enterprises attempted to bridge this semantic gap by developing specialized ML models, these custom solutions proved both costly to develop and brittle in practice, limited to recognizing only the specific patterns they were trained to find.
LLMs open up entirely new territory in enterprise data utilization. Where traditional approaches forced each organization to build their AI capabilities from scratch—limited by their own data, domain expertise, and resources—LLMs offer a dramatically different paradigm. These models, pretrained on the collective knowledge of the internet, arrive with a sophisticated grasp of language, concepts, and relationships that would be impossible to achieve through traditional, organization-specific training. This breakthrough means companies can now focus their efforts on fine-tuning and applying this preexisting intelligence to their specific challenges, rather than spending years building up foundational capabilities.
While regulatory acceptance of these techniques has been a concern, evolving guidance now acknowledges their transformative potential and offers clear paths for responsible deployment. For example, the National Association of Insurance Commissioners’ (NAIC’s) model bulletin on artificial intelligence (NAIC 2023) explicitly endorses AI adoption—provided insurers develop a robust AIS (artificial intelligence systems) program to address data integrity, risk management, and consumer protections. By stipulating these guardrails, regulators signal that innovative solutions can thrive within a balanced framework.
1.2. The impact of LLMs on actuarial work
These advancements are particularly impactful for actuarial work, where the ability to draw insights from disparate data sources is essential but notoriously difficult. LLMs thrive in this domain, enabling organizations to interact with and understand their data more seamlessly than ever before.
Imagine a chief underwriting officer striving for consistency across a geographically distributed team of underwriters. Although everyone follows the same written guidelines, individual interpretations inevitably diverge—especially when complex policies or nuanced risk factors are at play. Consequently, one underwriter might take a stricter view of a particular coverage limit, while another interprets the same clause more leniently, leading to inconsistencies in pricing, terms, and risk acceptance. Over time, these discrepancies can erode the reliability of underwriting decisions and obscure overall risk trends.
The ability to successfully apply LLMs to insurance-specific problems would change the dynamic in three key ways:
-
Unified understanding: These models can seamlessly process unstructured content—from claims narratives to adjuster notes—extracting nuanced insights that traditional systems would miss. They can spot subtle patterns, such as inconsistencies in event descriptions or emerging risk factors, which might be invisible to conventional analysis.
-
Dramatically lower barriers: Where building intelligent data tools once required PhD-level ML expertise and months of development time, LLMs have fundamentally simplified this process. Today, actuarial teams can leverage powerful pretrained models through simple APIs, enabling even those with basic programming skills to build sophisticated analysis tools in days or weeks rather than months or years.
-
Adaptability: These models come preloaded with broad knowledge of actuarial concepts and insurance principles yet can be rapidly fine-tuned to your specific business context. With minimal effort, they can learn your company’s unique terminology, products, and risk assessment approaches.
While building these systems still requires significant effort today, we are moving toward a future where AI will automate much of this complexity. This transformation—from static, siloed analysis to dynamic, integrated understanding—represents perhaps the most profound impact of AI on enterprise operations. It allows us to shift to a real-time view of our business and helps us answer questions that were previously unanswerable.
2. Case study
The following case study illustrates the practical application of AI in actuarial workflows.
2.1. Background: US Environmental Protection Agency (EPA) environmental site assessment (ESA)
The EPA outlines procedures for conducting ESAs, which are critical in identifying environmental risks on a property. An ESA typically has two phases:
-
Phase I ESA: Focuses on identifying potential environmental liabilities by reviewing historical records, site inspections, and interviews. No physical testing is done at this stage.
-
Phase II ESA: Conducted if Phase I identifies potential contamination. This phase involves sampling soil, groundwater, and air to measure the extent of contamination and to evaluate risks posed by hazardous substances, such as asbestos, lead, polychlorinated biphenyls (PCBs), or volatile organic compounds.
2.1. Challenges in ESA analysis
ESA analysis challenges include the following:
-
Identifying contaminants such as lead, asbestos, or PCBs
-
Understanding how contamination levels compare with legal and safety standards
-
Evaluating contamination spread and migration risks (e.g., into groundwater or neighboring properties)
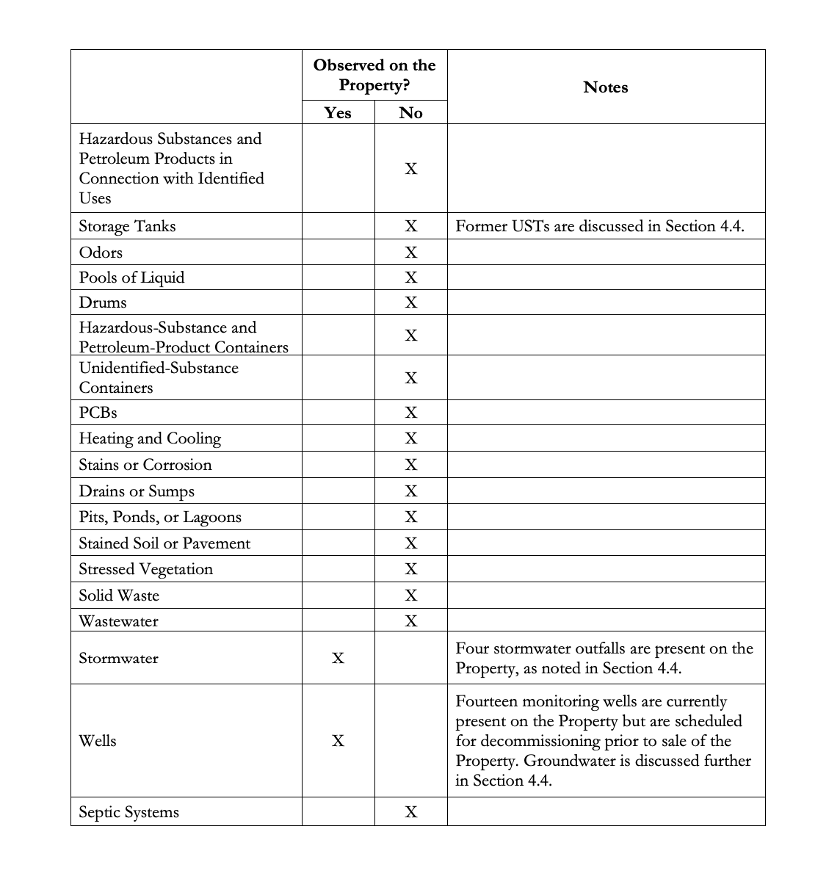
Table 1 is an excerpt from a sample Phase I ESA. It illustrates how findings—such as the presence or absence of hazardous substances—are documented, highlighting challenges such as interpreting incomplete data, correlating multiple contaminants, and ensuring compliance with applicable regulatory thresholds.

The information collected from these assessments helps insurers understand environmental risks, potential liabilities, and regulatory requirements. We will focus on the Phase I assessments, which are labor-intensive and require significant human expertise to interpret.
While we illustrate one property for simplicity, the same process easily scales to many properties, forming the foundation for robust actuarial ratemaking. By automating the extraction of key indicators (e.g., contaminant levels or risk profiles) across multiple Phase I reports, underwriters and actuaries can build a richer, more consistent dataset for pricing decisions. Rather than manually combing through hundreds of PDF reports, teams can rapidly aggregate these extracted insights into structured fields, yielding a dataset that can feed rating algorithms and refine both underwriting and pricing at an enterprise level.
The accompanying Jupyter notebook demonstrates these concepts using an OpenAI-based implementation for simplicity, but the approaches we explore here—from embedding strategies to retrieval techniques—form the foundation for any LLM system, regardless of the platform used (e.g., OpenAI, other commercial AI models, or open-source models).
2.3. Grounding LLMs in real-world data with RAG
LLMs can streamline the analysis of complex documents, but if the text you need—like Phase I ESA reports—was not part of their original training data, the model will fill knowledge gaps with inaccurate details if prompted directly. To understand why these gaps occur, it helps to look at how LLMs work.
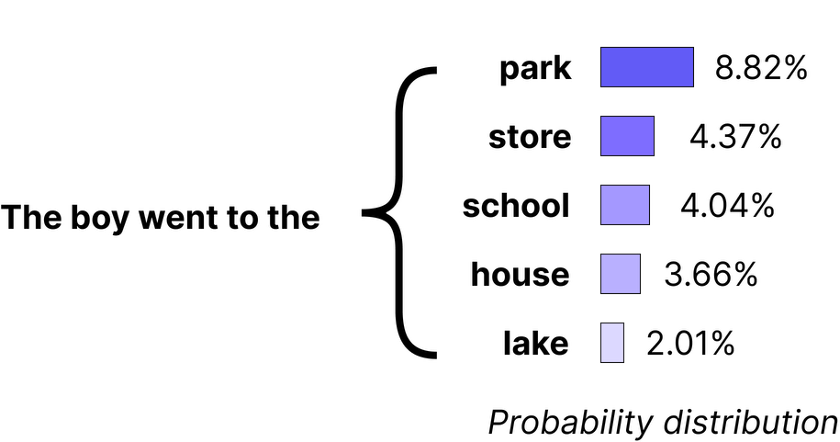
A core limitation of LLMs is that they are fundamentally designed to predict the most likely next word in a sequence based on patterns found in vast amounts of general text data. Unlike a search engine or a database, which retrieves exact information, LLMs do not “know” facts in a traditional sense. They generate responses by statistically inferring likely sequences of words.
The sample prediction distribution shown in Figure 1 illustrates how the model infers likely next words based on context.

This LLM design leads to a phenomenon known as “hallucination”: when asked questions that require specific or recent knowledge—like “Who is our company’s largest customer?”—the LLM produces an answer that sounds plausible but may be entirely incorrect. This happens because the model lacks direct access to current, factual knowledge and relies instead on general patterns and associations. If a specific answer was not part of its training data, the model may confidently generate a response that is, in reality a misinformed guess. Perhaps most challenging of all, LLMs often do not recognize when they are hallucinating (Huang, Yu, Ma, et al. 2023).
One solution to this challenge is in-context learning, where specific facts and information are provided directly in the prompt. This gives LLMs a form of “short-term memory” to work with. They can reference and reason about any information included in the current conversation, even if it was not part of their training data. By providing explicit information in the prompt, we constrain the LLM to work with verified facts rather than relying on its training data. This process is called grounding.
However, in-context learning has its limitations. While modern language models can process a significant volume of input—many reaching upward of 100,000 tokens, or roughly 75 pages of text—this capacity is rarely enough to include every piece of potentially relevant information. Loading massive amounts of data into a single prompt also raises costs, slows responses, and risks burying the most pertinent details.
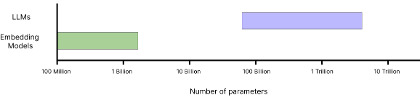
In many real-world scenarios, a more practical and efficient strategy is to first filter and identify relevant information using simpler, faster methods—such as embedding models—then leverage the language model’s full power for reasoning and synthesis. This two-stage approach strikes an effective balance, preserving computational efficiency while maintaining high-quality outputs.
As shown in Figure 2, embedding models are typically 100 to 1,000 times smaller than LLMs. This size difference has significant implications for information retrieval and processing efficiency.
This insight forms the foundation of retrieval-augmented generation (RAG), a framework that efficiently pairs LLMs with specialized retrieval systems. RAG searches through external knowledge bases—such as insurance claims, environmental reports, or regulatory databases—to find relevant information before the LLM generates its response. By incorporating this targeted retrieval step, RAG offers two main advantages:
-
Access to untrained information: RAG allows LLMs to draw on real-time or domain-specific data, enabling accurate responses to questions without requiring constant retraining.
-
Traceable responses: Since RAG retrieves information from reliable sources, the LLM’s answers are supported by concrete data, making it possible to verify each insight’s origin, relevance, and accuracy.
To understand how RAG operates in practice, we illustrate a specific example through each step of the process. Consider an environmental risk assessment where we need to identify contaminants on a property. Figure 3 walks through each step of the RAG process, from the initial user question through knowledge base retrieval to the final LLM response.

In essence, RAG gives the LLM the information it needs to complete a task.
2.4. Moving beyond keywords: The power of semantic search
Although RAG ensures the LLM only responds with data from trusted sources—like specific details from our ESA reports—a critical question remains: How do we quickly find the right passages about lead, asbestos, or other site-specific concerns among thousands of pages? In other words, providing the model with the best information hinges on effective retrieval. This is where we move beyond simple keyword searches and embrace more powerful techniques, which we explore next.
A simple, “naive” approach to retrieval might involve searching for keywords. Imagine trying to identify contaminants in an environmental report by pressing Ctrl + F and searching for terms like lead or asbestos. While this will locate direct mentions, it has significant limitations. Keyword searches are literal. They miss synonyms, context, and meaning. For example, searching for lead would not necessarily surface related phrases like heavy metals or toxic substances, potentially missing critical information.
This is where embeddings come into play, offering a far more powerful and nuanced method for retrieving information (Mikolov et al. 2013). Embeddings are a form of vector representation that encode the meaning of text, allowing us to go beyond exact keyword matching. In essence, embeddings represent words, sentences, or even entire documents as points in a high-dimensional space. When two pieces of text have similar meanings, their vectors will be close together in this space, making it easy to find relevant information by measuring their similarity.
To illustrate, we take the word lead and obtain its embedding, which is just a vector, with each number representing one of the dimensions in the high-dimensional space where lead resides.
result = get_embedding(“lead”)
print(result)
>>> [0.003903043922036886, 0.004469134379178286, 0.0018829952459782362,
0.004643926862627268, -0.026028238236904144, -0.002174, ...]
This produces a vector with over 3,056 dimensions, each one encoding a tiny piece of the word’s meaning. In real-world applications, embeddings have anywhere from hundreds to thousands of dimensions, where each dimension captures a subtle aspect of meaning. For example, some dimensions might capture associations related to toxicity, while others might relate to material type or regulatory relevance.
2.5. Visualizing embeddings
Visualizing such high-dimensional vectors is challenging, but with dimensionality reduction techniques, we can project these vectors onto a two- or three-dimensional space to see relationships more intuitively. OpenAI’s embedding model conveniently supports built-in dimensionality reduction, allowing us to request an embedding with a reduced number of dimensions (e.g., from thousands down to three). For the sake of this article, this allows us to easily visualize our vectors in a more accessible form.
However, it is important to note that in production, dimensionality reduction is typically avoided, as it can remove subtle nuances from the high-dimensional space, compromising retrieval accuracy.
The plot in Figure 4 shows that lead contamination and asbestos are grouped closely together, reflecting their shared association with environmental hazards, while flower appears farther away due to its lack of relevance.
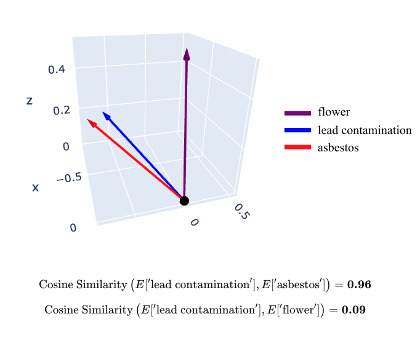
Cosine similarity is a useful metric for quantifying these relationships. It measures how closely related two concepts are based on the “angle” between their vectors in high-dimensional space. A similarity score closer to one indicates strong alignment between concepts, while a score closer to zero indicates weak or no relationship.
Unlike Euclidean distance, cosine similarity focuses on the direction of the vectors rather than their magnitude, making it especially useful for text embeddings, where we care about the relative orientation (or “meaning”) of concepts rather than their absolute positions in space. This makes it ideal for capturing semantic relationships between words or phrases, even when they may vary in intensity or have different scales.
By leveraging embeddings and cosine similarity, we enable retrieval systems to recognize content that is contextually aligned with a query, even if the exact words do not appear in the documents. This approach enhances information retrieval, making it more flexible and effective at finding nuanced connections that traditional keyword-based systems might miss.
2.6. Parsing documents into embeddings
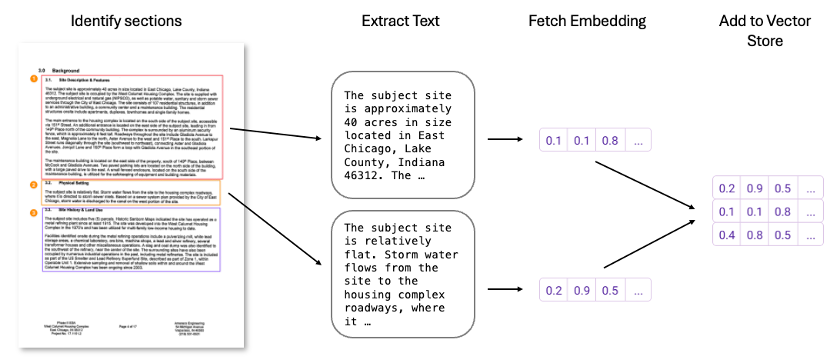
To maximize the relevance and accuracy of retrieval, we aim to pinpoint specific passages within documents that directly address a given query. This is especially important for large Phase I ESA or environmental assessment reports, which may span dozens or even hundreds of pages, covering everything from historical site usage to soil contamination levels. Rather than processing entire documents (which may contain diverse, loosely related content), we break them down into smaller, focused sections. This approach allows the system to zero in on the most relevant passages and return more precise results.
Many of the current embedding models perform best with text chunks of around 100 to 1,000 words, or roughly a few paragraphs. This chunk size allows the model to capture cohesive information while preserving context, which is essential for embedding accuracy. Typically, each section of a document is thematically focused, so chunking helps maintain this thematic coherence, improving both the relevance of embeddings and the precision of retrieval.
In practice, this means that large documents, such as environmental assessments with tens of thousands of words, are divided into coherent segments. By embedding these smaller chunks and attaching metadata (e.g., document name, page number) to each one, we can precisely show users where the information originates in the retrieval step and enable our system to pinpoint the most relevant excerpts.
Figure 5 illustrates converting document sections into embeddings for efficient, context-driven search in a vector database.
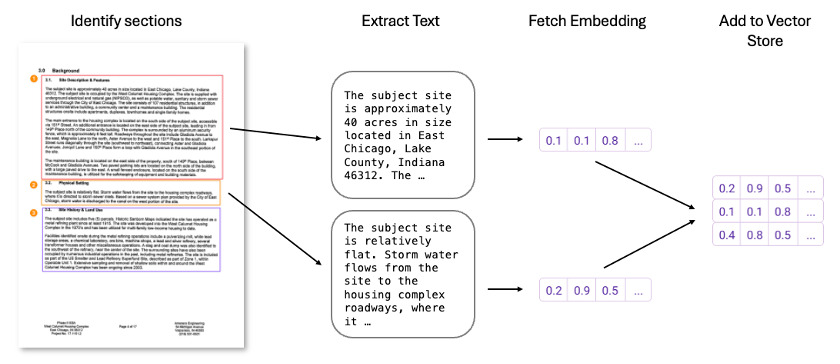
While our example focuses on a single document for simplicity, the same principles apply when working with thousands or even millions of documents. By breaking down each document into manageable sections, we can create a database of embeddings that can be efficiently searched and matched to user queries.
With this setup, even vast repositories of information—such as regulatory databases, policy documents, or insurance claims—can be queried at scale. Using fast retrieval algorithms and efficient vector search techniques, we can quickly surface the most relevant sections across an entire corpus.
2.7. Retrieval
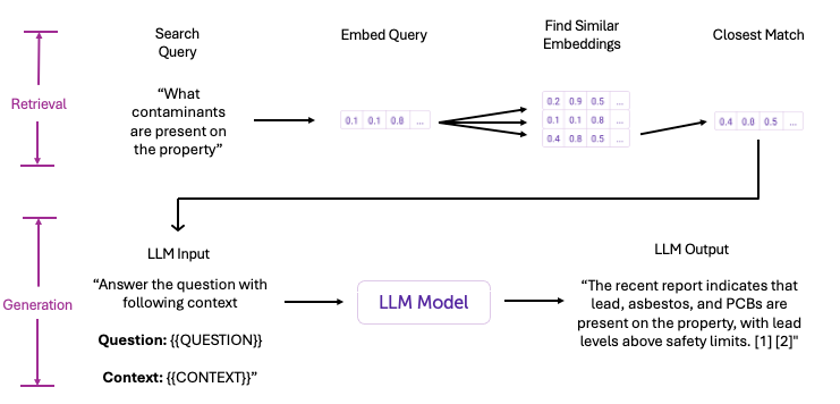
To locate information that precisely answers a user’s query, the system first converts the query—for example, “What contaminants are present on the property?”—into a vector that captures its semantic meaning. This vector is then compared with pre-embedded document chunks within a vector database. By identifying the most similar vectors, the system retrieves the most relevant document sections, links them to their original excerpts, and passes them to an LLM for processing (see Figure 6).
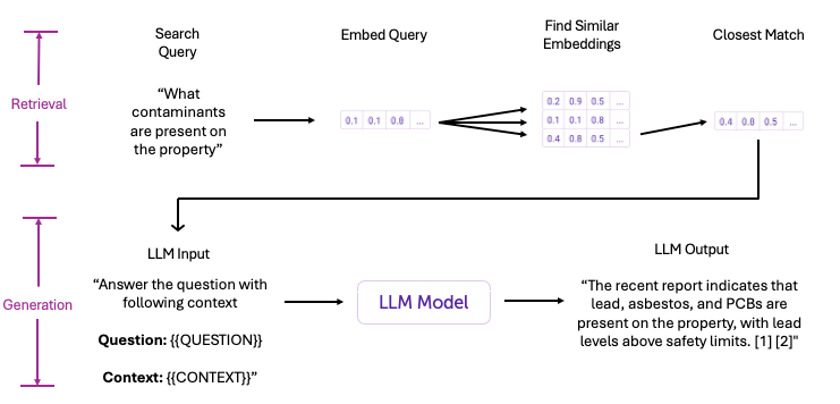
Again, most importantly, this approach “grounds” the LLM’s answers with specific, verified context from the document, allowing us to provide citations and transparency in how we reached each answer.
Like any ML model, input data quality directly impacts output reliability. If the input data are fragmented, outdated, or irrelevant, the LLM’s response will reflect these deficiencies, resulting in unreliable or misleading answers.
2.8. Structured outputs: Bridging LLMs and enterprise systems
So far, we have focused on how natural language responses can provide meaningful insights to users. While these responses are invaluable for human understanding, they often lack the structure required to integrate directly with complex systems like actuarial models, policy databases, and underwriting tools. For these applications, precise, machine-readable data formats are essential to ensure seamless integration and automation.
One of the most widely used formats for data exchange is JavaScript Object Notation (JSON), which enables systems to interpret and act on structured outputs efficiently. Most foundational models now support generating structured responses that adhere to a predefined JSON schema. By defining such a schema, we can enforce the following:
-
Required fields that must be present
-
Data type constraints (numbers, strings, booleans, etc.)
-
Value ranges and acceptable options
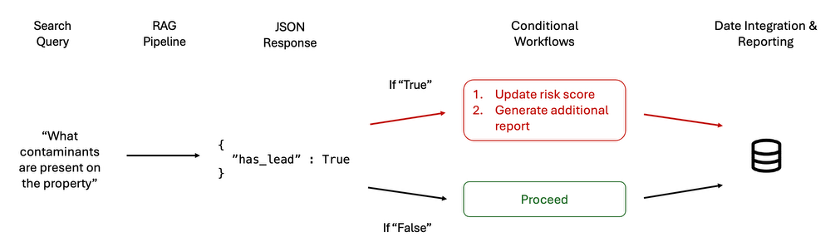
Structured outputs (like JSON) act as a “translation layer,” making it possible for AI-generated responses to plug directly into these systems. For example, if an LLM flags a potential contamination risk, it can return the exact nature of that risk (e.g., lead or asbestos), formatted in a way that can immediately update relevant underwriting criteria or trigger further assessment in existing systems (see Figure 7).
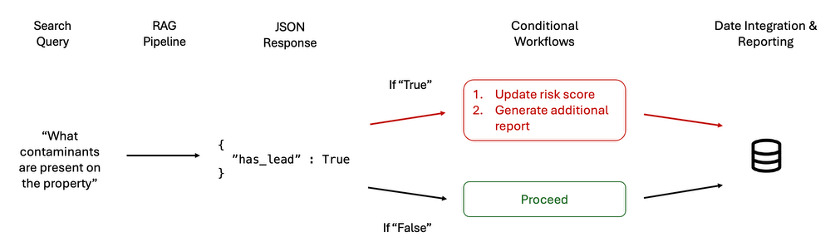
This structured output format allows us to build workflows with complex conditional logic and advanced control flows, which can automatically direct different actions based on specific data values.
You can imagine chaining multiple AI-driven processes together. For instance, if the output indicates contamination, the system might initiate a follow-up query to a different model to assess the severity of the contamination or recommend specific remediation strategies. Similarly, based on the nature of the flagged risk, the system could route additional queries to a specialized LLM trained on regulatory compliance to verify whether the detected levels exceed legal thresholds. This dynamic chaining enables systems to adaptively refine their understanding and provide more granular insights while maintaining a high level of automation and efficiency.
By combining structured outputs with chained workflows, we unlock the ability to orchestrate increasingly sophisticated AI-driven systems, seamlessly integrating multiple models and processes to handle even the most complex decision-making scenarios.
2.9. RAG is more than just embeddings
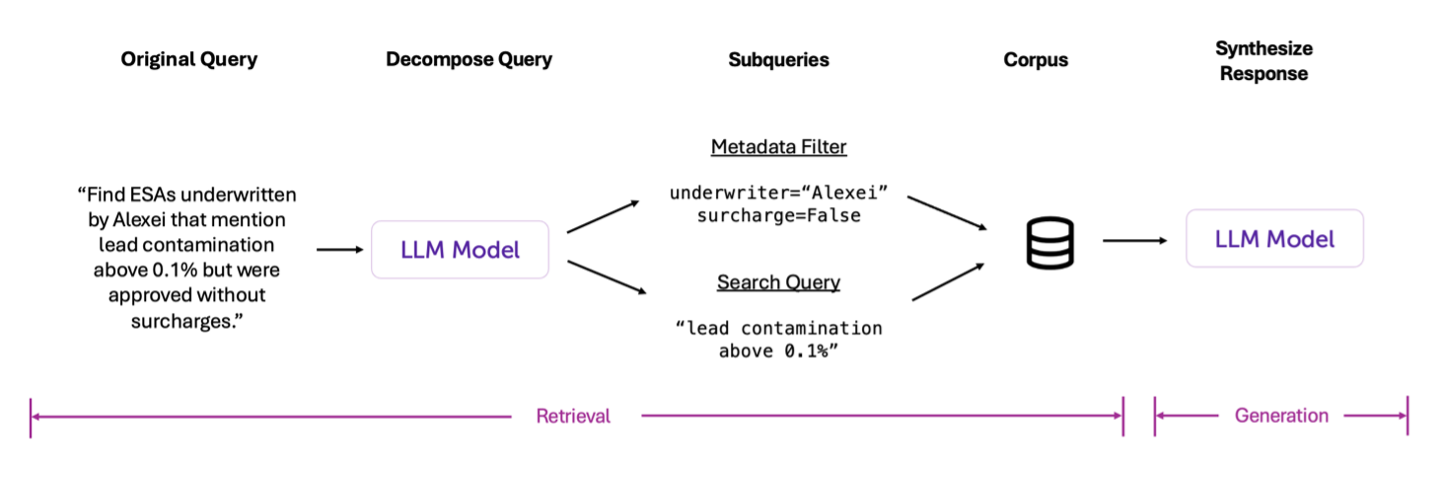
While embedding-based RAG solutions are indispensable for efficiently handling massive text corpora, overreliance on embeddings can introduce limitations. Embeddings are excellent at handling straightforward lookups and matching semantically similar text. However, many questions actuaries face require more nuanced logic, such as time-sensitive queries, multistep reasoning, and conditional filtering. Under these conditions, simple embedding-based retrieval alone may not suffice.
For example, consider our earlier example of ensuring consistent policy interpretations across multiple underwriters. An embedding index alone may not handle such nuanced requests. Instead, you might need to break the question down into steps or apply additional constraints—such as metadata filtering or conditional logic—before retrieving relevant data. In other words, you can—and sometimes should—layer on more sophisticated retrieval techniques to augment embeddings.
As shown in Figure 8, the LLM is not just responsible for generating the final answer—it also plays a key role in the retrieval step by interpreting the user’s query and turning it into subqueries that combine metadata filtering with embedding-based search.
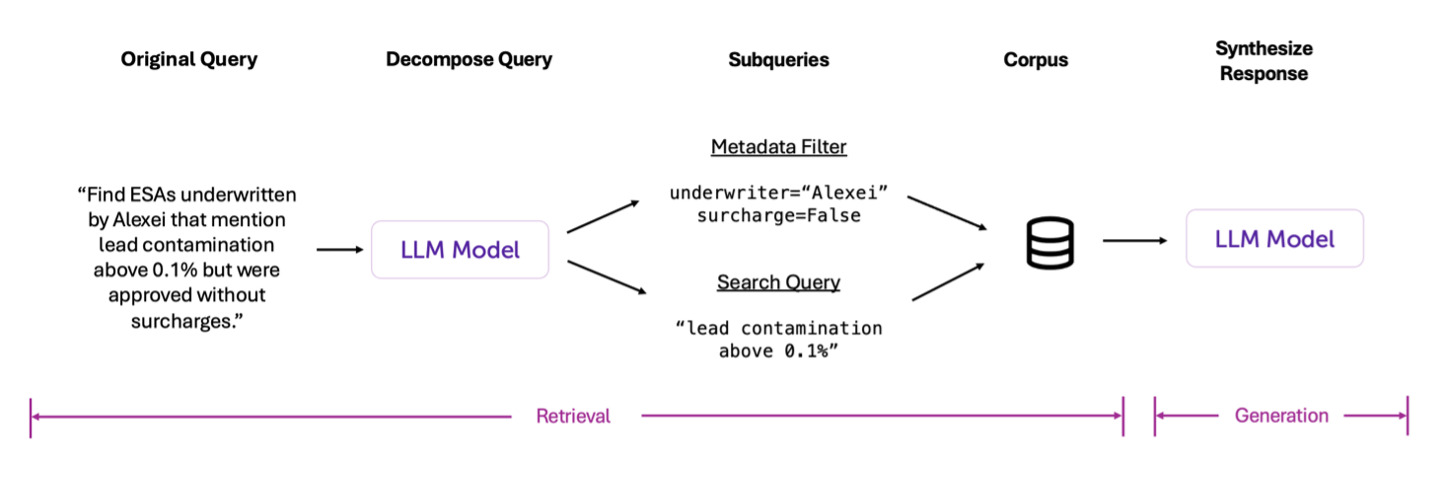
At a high level, though, RAG simply means letting your model “look up” the information it needs rather than hallucinate or guess. How you do that lookup—whether it is a basic embedding search or a more complex, step-by-step pipeline—depends on your business question and the nature of your data. For many routine tasks, embedding-based retrieval is an easy and effective starting point. As your team and technology mature, you can incorporate additional logic and filtering, ensuring that your AI remains grounded in accurate, up-to-date information no matter how large or diverse your data corpus becomes.
Regardless of the approach, the foundational principle remains the same: grounding the LLM’s answers in verified, high-quality data is essential for producing reliable, transparent, and actionable results.
3. The foundations of LLM evaluations
One of the major roadblocks to enterprise AI adoption is evaluating the performance of these systems. Unlike traditional software, where deterministic outputs make testing straightforward, LLMs are inherently stochastic, producing varied responses to the same input. This variability requires a different approach to testing: one that captures accuracy, reliability, and consistency in a measurable way.
This is where evaluations come in. Think of evaluations as unit tests for language models; they allow teams to systematically measure how well a model performs on specific tasks. By turning ambiguous outputs into structured experiments, evaluations make model governance and upgrades more manageable, helping to build confidence across teams and stakeholders.
To establish a baseline, many companies begin with a straightforward approach—using human reviewers to assess model outputs. Human annotators can create a “golden test dataset” by evaluating responses against key criteria, providing a high-quality signal for performance.
For our ESA use case, this might mean verifying how accurately the model identifies key contaminants compared with an expert-labeled Phase I summary. If the model misidentifies asbestos references or omits mention of PCBs, that signals a gap we need to address. Evaluations that compare these model outputs with known “ground truth” in ESA reports help us understand whether our system is genuinely capturing the necessary risk factors for ratemaking.
3.1. Scaling evaluations with LLM-assisted approaches
While this approach offers valuable insights, it quickly becomes costly and impractical to scale. Model-graded evaluations, essentially using AI to assess AI, are a scalable alternative. Foundational models have shown strong alignment with human judgment in evaluating natural language tasks (Zheng, Chiang, Sheng, et al. 2023). By reducing human effort in the evaluation process, language models can help address complex edge cases.
For example, we can give the model an input query and a pair of responses, then prompt it to compare factual content between the provided answer and an expert answer. We use an LLM as a judge here because minor differences in phrasing or word choice can often obscure the true accuracy of an answer when evaluated by simple metrics. Unlike rigid, automated comparison methods that flag any variation as incorrect, an LLM can assess subtle differences in meaning, determining whether two answers convey equivalent information or whether discrepancies impact factual accuracy.
Figure 9 illustrates a binary evaluation example where the LLM’s answer and the expert answer are inconsistent, signaling a missing key detail.

While some evaluations may be binary, other scenarios benefit from scaled evaluations. In these cases, responses are rated on a spectrum, typically using a scale from 1 to 5, to capture nuances like relevance, credibility, or correctness. This kind of evaluation is especially useful for complex, open-ended tasks where a simple pass/fail assessment is insufficient to capture response quality. However, implementing scaled evaluations can be challenging, as different models may interpret and rate the same response inconsistently, requiring careful calibration to ensure reliable scoring.
One way to improve consistency in evaluations is through pairwise comparisons. LLMs are particularly effective at comparing two pieces of text to determine which is closer to the ideal response, because they are often better at making relative judgments than absolute ratings. Asking the model to choose between two responses instead of assigning a direct score can reduce ambiguity and achieve more stable results.
Figure 10 illustrates a scaled rating (4 out of 5) while also using a pairwise comparison—the model compares the LLM’s response with the expert’s and highlights minor deviations. In practice, combining both methods helps quantify overall quality and pinpoint where the LLM may diverge from the ideal answer.

As with anything related to LLMs, clear instructions are key. For instance, in the scaled evaluation example, it is crucial to define explicit criteria for what constitutes a 1, 2, 3, 4, or 5 rating. Ambiguity in scoring leads to inconsistent evaluations, reducing the reliability of results. Additionally, including concrete examples for each score can help evaluators—whether human or AI—better understand how to apply the criteria consistently. This level of precision ensures that evaluations remain reliable and actionable, creating a strong foundation for improvement.
While we are only scratching the surface of LLM evaluation, it is crucial to keep a few core principles in mind. First, align your metrics with the specific goals you are trying to achieve. From there, develop a hypothesis about how to improve the system’s performance, implement those changes, and measure whether they move the needle on your chosen metrics. Continually analyze weak areas, refine your approach, and repeat the cycle. By iterating in this way, you transform evaluations from a one-off exercise into a systematic method for guiding ongoing development and ensuring the quality of model outputs.
Evaluation-driven development emphasizes continuous testing, where evaluations become the foundation of the development process. This methodology treats each model update as a hypothesis, tested against real-world use cases and data. With each iteration, developers can use evaluation outputs to refine responses, prioritize areas for improvement, and achieve a measurable impact on target metrics.
4. Navigating regulatory expectations: The NAIC model bulletin
While robust evaluation frameworks are essential for building confidence within organizations, no discussion of AI deployment in the insurance industry would be complete without acknowledging the heightened regulatory scrutiny that accompanies these innovations. NAIC has recently adopted a model bulletin outlining how insurers should govern the development, acquisition, and use of AI systems. Although this guidance is not a model law or regulation per se, it has already gained considerable momentum, with nearly half of states adopting or adapting its key provisions as of December 1, 2024 (NAIC 2025).
A central tenet of the model bulletin is the mandate for an AIS program—a written framework that addresses governance, risk management, and internal controls. This framework spans every stage of the AI life cycle, from design to deployment, and must specifically address how an insurer will prevent adverse consumer outcomes, such as unfair discrimination or inaccurate decisions. In practical terms, this means the following:
-
Data integrity and bias mitigation
-
Key focus: Ensuring that data fueling AI models is accurate, representative, and continuously monitored for shifts or biases.
-
What it involves: Documented processes to validate data, detect potential biases, and address “model drift” as market conditions evolve. RAG can help maintain transparency by grounding outputs in verifiable data, reducing spurious or discriminatory results. Most critical are rigorous evaluation loops—preferably automated—that measure performance against clear benchmarks. This feedback alerts insurers to subtle biases, enabling them to refine their models or datasets and promptly correct any unfair or discriminatory outcomes.
-
Why it matters: By swiftly identifying and addressing inaccuracies and biases, insurers minimize the risk of unfair underwriting or claims decisions.
-
-
Documentation and audit trails
-
Key focus: Creating transparent records of model decisions, version updates, and validation outcomes.
-
What it involves: Tracking all relevant information—such as RAG citations, model changes, and evaluations (human reviewed or model graded). RAG, combined with human oversight, helps tie each output to verifiable data, forming a clear paper trail of evidence.
-
Why it matters: Thorough documentation demonstrates compliance, highlights how blind spots are proactively addressed, and makes it easier to pinpoint—and correct—potential sources of discrimination.
-
-
Accountability and transparency
-
Key focus: Defining governance structures and clear responsibilities across AI initiatives.
-
What it involves: Insurers should establish cross-functional committees (including actuarial, underwriting, legal, and compliance) to vet models for both technical soundness and ethical implications.
-
Why it matters: Regulators want clarity on who “owns” AI decisions. A well-defined chain of accountability aligns with the NAIC model bulletin’s focus on fair, traceable outcomes.
-
Importantly, our approach does not propose using LLMs as a rating engine themselves. Rather, these LLM systems unify data so that transparent, well-established actuarial methodologies (like GLMs) can incorporate newly available features. Distinguishing between the data extraction phase and the rating phase helps ensure alignment with regulatory goals of clarity, fairness, and traceability.
In short, the NAIC model bulletin underscores that robust evaluations, structured RAG approaches, and “human in the loop” feedback are not mere technical extras; they are central to a governance structure that emphasizes fairness, traceability, and accountability when working with LLMs.
5. Looking ahead: The long-term impact of AI on actuarial practices
Moving forward, we can expect LLMs to play an increasingly central role, not by replacing the actuarial toolkit but by enriching it. Where established models such as GLMs once struggled with sparse or unstructured information, LLM-driven methods now translate text into structured signals that feed seamlessly into existing actuarial workflows. This pivot—evolving from static data analysis to real-time, dynamic queries that drive business decisions—holds tremendous potential for innovation in underwriting, pricing, and risk management.
Yet none of these technical advances can succeed without rigorous evaluation. In an industry rightly concerned with fairness, equity, and regulatory compliance, robust testing frameworks and transparent documentation are indispensable. Evaluations that blend human reviewers with AI-assisted scoring create a feedback loop to continually refine performance. NAIC’s model bulletin on AI codifies the need for precisely this type of governance, pointing insurers toward robust AIS programs capable of monitoring data integrity, bias, and consistent decision-making.
Today, the industry stands at the threshold of a new era in data-driven actuarial work. The tools and frameworks described here—RAG pipelines, embedding-based retrieval, structured output formats, and iterative evaluations—provide a blueprint for leveraging LLMs responsibly and effectively. With thoughtful governance and a continuous learning mindset, actuaries can harness these AI technologies to uncover ever deeper insights, deliver more precise risk assessments, and ultimately raise the standard for how insurance is modeled and priced.