
1. INTRODUCTION
In the rapidly evolving landscape of the insurance industry, data has become an invaluable asset, driving decision-making processes and shaping business strategies. Actuarial ratemaking, a cornerstone of insurance operations, relies heavily on the analysis of vast and detailed datasets to accurately assess risks and determine appropriate premiums. However, as the volume and granularity of data increase, so do the challenges associated with maintaining data privacy and complying with stringent regulatory requirements.
The insurance sector is thus faced with balancing the need for data-driven insights with the imperative to protect sensitive customer information. Traditional data anonymization techniques, such as masking, aggregation, or noise, often fall short in preserving the utility of the data, compromising the accuracy and effectiveness of actuarial models (Fung et al. 2010). This dilemma calls for innovative solutions that can reconcile the seemingly conflicting demands of data utility and privacy protection. A recent Volkswagen privacy breach—in which personal customer details were exposed—serves as a stark reminder of the vulnerabilities inherent in traditional data handling processes (European Commission 2016).
1.1. Research Context
Synthetic data can be a promising solution to this complex challenge, particularly in the context of actuarial ratemaking. By generating granular datasets that mimic the statistical properties of the underlying real data, synthetic data offers a pathway to maintaining data utility while ensuring privacy compliance.
The adoption of synthetic data in actuarial ratemaking is, however, not without its challenges. The complexity of insurance data, characterized by high dimensionality, a mix of categorical and numerical features, sparse distributions, and temporal dependencies, poses unique challenges in synthetic data generation. Ensuring that synthetic datasets accurately capture these nuances while maintaining privacy is a delicate balancing act that requires advanced methodologies and validation processes. Furthermore, the lack of established standards and literature regarding privacy measures for synthetic data in the actuarial context presents a significant gap.
1.2. Objective
This paper aims to address the challenges—and opportunities—of data availability and privacy by providing a comprehensive overview of synthetic data methodologies tailored specifically to actuarial ratemaking. A key contribution of this paper is the proposal of tools for evaluating the privacy robustness of synthetic datasets specifically in the context of insurance ratemaking. These assessment techniques are designed to help actuaries navigate the delicate balance between data fidelity and privacy protection, addressing the current gap in established literature on privacy assessment in actuarial applications. By exploring these aspects, this paper aims to lay the groundwork for the development of future standards in synthetic data privacy and fidelity evaluation within the actuarial field, with a specific focus on ratemaking applications. Our goal is to facilitate the use of sensitive data in actuarial processes while maintaining standards of privacy protection, ultimately leading to more secure, compliant, and effective insurance pricing strategies.
1.3. Outline
This paper is organized as follows: Section 1 examines the regulatory landscape and data sharing challenges faced by the insurance industry, highlighting specific use cases where synthetic data can offer tangible benefits in the ratemaking process while preserving privacy. Section 2 introduces synthetic data with a focus on its application to the unique characteristics of insurance data used in ratemaking and reviews different synthetic data generation techniques. Section 3 discusses a novel approach taken by the authors to generate synthetic data and describes an anonymized dataset used as a proxy for original data. Section 4 compares the performance of synthetic data against the original data and discusses how the technique addresses both utility and privacy considerations. Section 5 summarizes and offers an outlook on the future role of synthetic data in actuarial science.
2. BACKGROUND AND METHODS
2.1. Regulatory landscape and data sharing challenges in insurance
The insurance industry operates in a complex regulatory environment that significantly impacts data usage and sharing practices. Stringent regulations such as the General Data Protection Regulation (GDPR) in Europe (European Commission 2016), the California Consumer Privacy Act (CCPA) in the United States (State of California 2018), and industry-specific laws like the Health Insurance Portability and Accountability Act (HIPAA) (U.S. Congress 1996) have heightened the focus on data privacy and protection.
These regulations impose strict requirements on how insurers collect, process, and store personal data. For instance, GDPR mandates that personal data must be processed lawfully, fairly, and transparently. It also grants individuals the right to access, rectify, and erase their personal data, as well as the right to data portability. Similarly, CCPA gives California residents the right to know what personal information is collected about them and how it is used and shared.
A recent privacy breach demonstrates the vulnerabilities associated with collecting and storing large amounts of sensitive data, posing challenges not only for technology-driven industries but also for sectors like insurance that rely heavily on data for operational efficiency. In late 2024, Cariad, a software subsidiary of the Volkswagen Group, experienced a significant data leak affecting 800,000 electric vehicles, with the precise geolocation of 460,000 cars exposed to an accuracy of 10 centimeters (Schulz and Ludwig 2025). This breach, caused by a misconfiguration in Cariad’s IT applications, highlights the potential risks posed by connected technologies and cloud-based storage solutions. While Cariad responded swiftly after being notified by ethical hackers, the exposure underscores how deeply embedded data collection is within modern products and services, often outpacing the security measures designed to protect it.
For insurers, this incident and others serves as a cautionary tale, illustrating how the integration of digital tools and telematics into vehicles or policyholder interactions could inadvertently expose sensitive information. Actuaries rely on detailed, granular data to accurately assess risks and determine appropriate premiums. However, the use of such data often conflicts with privacy regulations that limit the collection and processing of personal information. For example, the right to erasure under GDPR allows individuals to access and request the deletion of their personal data. If a policyholder terminates their insurance policy and exercises this right, insurers must ensure that all instances of the data are erased without disrupting operations—an increasingly complex task given that many databases are not designed for seamless data deletion. Moreover, removing such data could affect actuarial models that depend on it. As insurers continue to adopt connected technologies for usage-based insurance (UBI) or risk assessment, robust data governance, anonymization techniques, and synthetic data generation become critical strategies to mitigate privacy risks while maintaining operational innovation.
Several key use cases illustrate the potential of synthetic data in actuarial ratemaking for privacy protection:
-
Model development and testing: actuaries can use synthetic data to develop and test ratemaking models without the risk of exposing sensitive customer information, ensuring that model development processes adhere to strict privacy standards. This is especially valuable when working with machine learning (ML) models that require large amounts of data for training. Moreover, as demonstrated by Carlini et al. (2019), ML models can unintentionally memorize and expose rare or unique training data.
-
Legacy system migration: when transitioning between systems or updating ratemaking models, synthetic data can be used to test and validate new systems without compromising the privacy of historical policyholder data. Synthetic data can be generated to mimic the structure, volume, and complexity of historical data, allowing thorough testing of new systems and migration processes without risking data breaches.
-
Compliance with the right to be forgotten: the right of customers to be forgotten poses challenges for platforms utilizing interconnected data. Synthetic data can help maintain workflow integrity when original data must be deleted. By creating synthetic versions of the data before deletion, the relationships between tables can be preserved without retaining identifiable customer information.
-
Secure data sharing: synthetic data allows insurers to share information with regulators, academic researchers, or industry partners without exposing actual policyholder data, facilitating collaborative research and regulatory compliance. This enables more open collaboration and knowledge sharing across the industry, potentially leading to improved risk assessment models and more accurate pricing strategies.
The adoption of synthetic data in actuarial ratemaking therefore offers a promising solution to the hurdles posed by stringent privacy regulations. However, its implementation requires careful consideration of the unique characteristics of insurance data and the development of robust privacy evaluation frameworks specific to actuarial applications.
2.2. Synthetic data overview
Consider the following scenario: an auto insurance company collects data from its policyholders, including:
-
Personal information: age, gender, income range, medical status.
-
Vehicle information: brand, model, year.
-
Location data: ZIP code, city, state.
-
Policy data: premium, deductibles.
The company plans to share this data with researchers for actuarial modeling but wishes to protect policyholder privacy. To this end, they apply simple de-identification techniques, such as removing direct identifiers (names, phone numbers, email addresses), generalizing sensitive attributes (e.g., replacing exact ages with age groups), and suppressing rare combinations (e.g., unique claims associated with rare vehicles).
Despite these de-identification efforts, re-identification can occur when attackers use external, publicly available datasets (Lauradoux, Curelariu, and Lodie 2023). These include sources such as public voter registries, vehicle registration databases, and accidents and claim reports. An attacker seeking to identify specific individuals in the dataset can link the de-identified dataset with these external sources. For example, ZIP codes and specific car models can significantly reduce the pool of potential individuals, as can a specific accident record or a unique combination of demographic information. The attacker can thus gain access to an individual’s claim history, financial details, and other personal insights like driving habits.
The insurance company therefore faces significant legal and reputational risks by releasing insufficiently protected data (U.S. Congress 1996). If re-identification occurs, the company could be held liable for violating data protection laws, which could result in substantial financial penalties, legal action from affected policyholders, and severe damage to the company’s reputation and trust. For policyholders, the consequences of re-identification can be far-reaching and deeply personal. Their sensitive information, including medical status, financial details, and driving habits, could be used for identity theft, fraud, or discrimination. This exposure might lead to higher insurance premiums, denied coverage, or even impact their employment prospects and personal relationships. Additionally, the revealed information could be used for stalking or other malicious purposes, putting policyholders’ physical safety at risk.
In light of these privacy concerns, a more robust approach is needed to properly anonymize the dataset. Synthetic data is artificially generated information that mimics the statistical properties and structure of real data such that there is no one-to-one correspondence between any of the subjects in the original data and the fictitious subjects in the generated data. It is created using ML algorithms and computational techniques to produce a new dataset of the same approximate size that preserves the overall characteristics and relationships found in the original data while ensuring that individual records cannot be traced back to real people. This enables modeling tasks to be performed that will result in the same approximate insights and will obviate the hurdles of working with private data.
Insurance data presents unique characteristics that make synthetic data generation both challenging and valuable. One key aspect is the highly sensitive nature of insurance information, which often includes personal details, medical histories, financial records, daily activities including telematics, etc. This sensitivity requires robust privacy protection measures to ensure compliance with regulations like GDPR, CCPA, and HIPAA.
Another characteristic of insurance data is its complexity and multidimensionality. Insurance datasets typically contain a wide range of variables, including demographic information, policy details, claims history, and risk factors. An additional challenge in insurance data is the rarity of meaningful claims data. The infrequency of claims presents a significant hurdle for data analysis and modeling, as it creates highly imbalanced and skewed datasets, yet it is exactly those events that most impact the risk models. Synthetic data generation techniques must accurately capture the intricate relationships and dependencies to produce realistic and useful datasets, while handling outliers in a way that both preserves their structure and discards them if they are too rare.
Advanced methodologies leveraging statistical methods and ML and artificial intelligence (AI) methods exist that approach synthetic data generation in different ways (see, e.g., Abay et al. 2019; Kuo 2019; Assefa et al. 2019). While both aim to produce data that replicates the statistical properties of real and granular datasets, they differ significantly in methodology, complexity, and interpretability. Statistical methods rely on predefined mathematical models and probability distributions and often require assumptions about the data’s underlying distribution. They can either be parametric or nonparametric, the latter offering a more flexible alternative, e.g., kernel density estimation, which creates a smooth estimate of the probability density function. Another example is copula methods, which can model complex dependencies between heavy-tailed risk factors while retaining their individual marginal distributions, making them particularly useful for insurance use cases. Conversely, ML/AI methods learn patterns and structures directly from the data without explicit distributional assumptions. They often use complex neural network architectures and thus may be more suitable to modeling high dimensional datasets; however, for the same reason they often lack interpretability, which can be a significant drawback in regulated industries where understanding the model used to generate the synthetic data is crucial.
2.3. Generation of synthetic data using our proposed method
2.3.1. Overview of the synthesizer
The synthesizer uses a structured kernel density estimation (KDE) approach, where categorical variables are processed before numerical variables to preserve privacy and maintain data fidelity. This sequential methodology is essential, as categorical variables define distinct subpopulations within the dataset, forming the basis for subsequent modeling of numerical variables.
KDE is a nonparametric technique used to estimate the probability density function (PDF) of a random variable. Unlike parametric methods that assume a specific distribution, KDE constructs the PDF by smoothing observed data points through a kernel function, resulting in a continuous estimate of the data’s underlying distribution. It preserves intricate, multimodal distributions without directly replicating data points from the original dataset.
Categorical variables, such as gender, marital status, or car model, delineate discrete groups within the dataset and often carry a higher risk of identification than numerical variables. Their finite and discrete nature can lead to unique combinations that may inadvertently reveal sensitive information. For example, a rare combination of ZIP code, car model, and marital status could easily single out one individual. In contrast, the flexibility in numerical data enables controlled distortion, preserving the statistical properties of the dataset while enhancing privacy.
To illustrate this process, consider a demand modeling dataset that includes categorical variables such as gender, marital status, ZIP code, and car model. Initially, the synthesizer applies a privacy parameter, denoted by K, to ensure that no category contains fewer than K records (Sweeney 2002). Categories that fall below this threshold are generalized into broader, less specific groups. For instance, rare car models may be aggregated under the label “censored,” reducing the likelihood of re-identification by limiting the presence of small, distinctive subpopulations.
The selection of K often depends on factors such as regulatory requirements, the sensitivity of the data, and the overall size of the dataset. The specific K value might also vary depending on the size of the insurer’s customer base and the granularity of data needed for actuarial analysis.
The absence of established norms in the insurance sector underscores the importance of iterative testing and consultation with domain experts to determine an appropriate threshold that aligns with the intended use case and privacy expectations.
Once the categorical variables have been processed, numerical variables such as age, income, or mileage are transformed and clustered within the subpopulations defined by the categorical variables. KDE is then applied within each subpopulation to generate synthetic numerical data that mirrors the empirical distribution of the original dataset. By sampling from continuous distributions with infinite support, KDE ensures that the likelihood of reproducing any exact original data point is virtually zero, enhancing privacy while maintaining the fidelity of the synthetic dataset.
Applying KDE within the subpopulations defined by categorical variables is crucial to preserving the logical relationships between variables. For example, generating mileage data without consideration for car model or ZIP code may yield unrealistic combinations, thereby reducing the utility of the synthetic data. By segmenting KDE by categorical subspaces, the synthesizer ensures that numerical values reflect the distributions specific to each subpopulation, reinforcing coherence and applicability.
While the application of a specific K value is a crucial step in reducing the risk of re-identification, it does not eliminate the need for a comprehensive risk assessment. K-anonymity does not trivially account for risks associated with membership disclosure or the possibility of inferring sensitive information. In Section 4.4 we discuss the robustness of our algorithm to membership inference.
2.3.2. Description of the original data used
The dataset that we will use for our demonstrations is a sample of a comprehensive collection of auto insurance policies from a large U.S.-based insurance company, spanning four years. The data was obtained from the Casualty Actuarial Society (CAS). It provides a rich array of variables that capture diverse aspects of insurance policy details, claims, and exposure metrics. This section elaborates on the dataset’s structure, content, and potential analytics uses.
The entire dataset is divided into three tables: Bodily Injury (BI), Property Damage (PD), and Collision (COLL). It serves as a valuable source for investigating insurance-related phenomena, such as risk assessment, policy evaluation, and rate prediction. Its variety of features make it well suited to a broad range of analytical and ML applications.
EARNED_EXPOSURE: this variable quantifies the proportion of the policy period during which coverage was active, and it ranges from 0 to 1. It has many negative (13%) and zero (21%) values. This could be a result of policies canceled mid-term, policies that were initially accounted for but canceled retroactively, or errors in data entries.
ULTIMATE_AMOUNT: an integer variable representing the total claim amount associated with the policy, measured over the policy’s lifetime.
ULTIMATE_CLAIM_COUNT: an integer variable describing the number of claims made during the policy period.
The ratio of the latter two variables is equal to the severity of a claim.
In addition, there are 46 variables, named VAR1 through VAR46. We lack the necessary metadata or background information to understand their specific content.
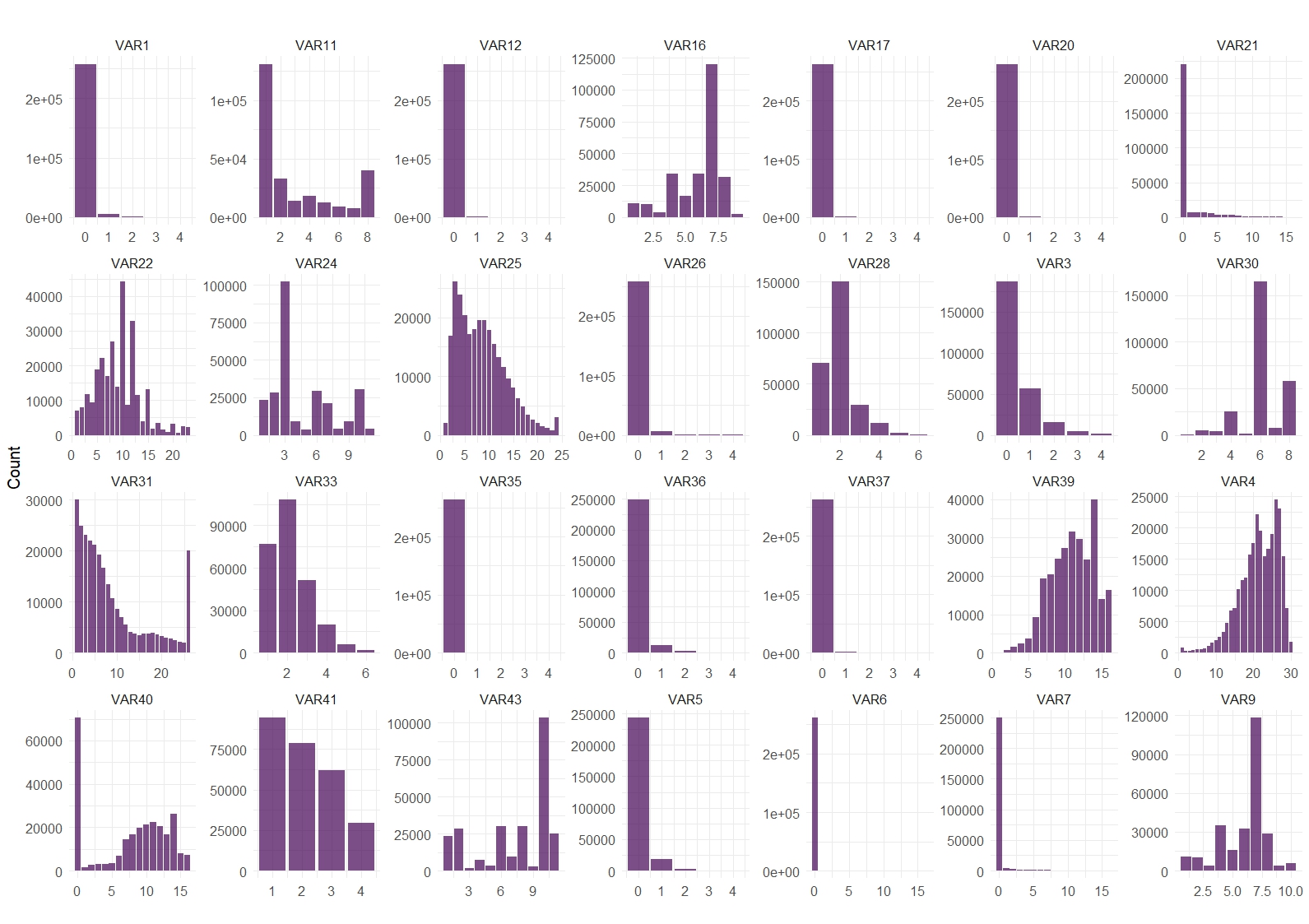
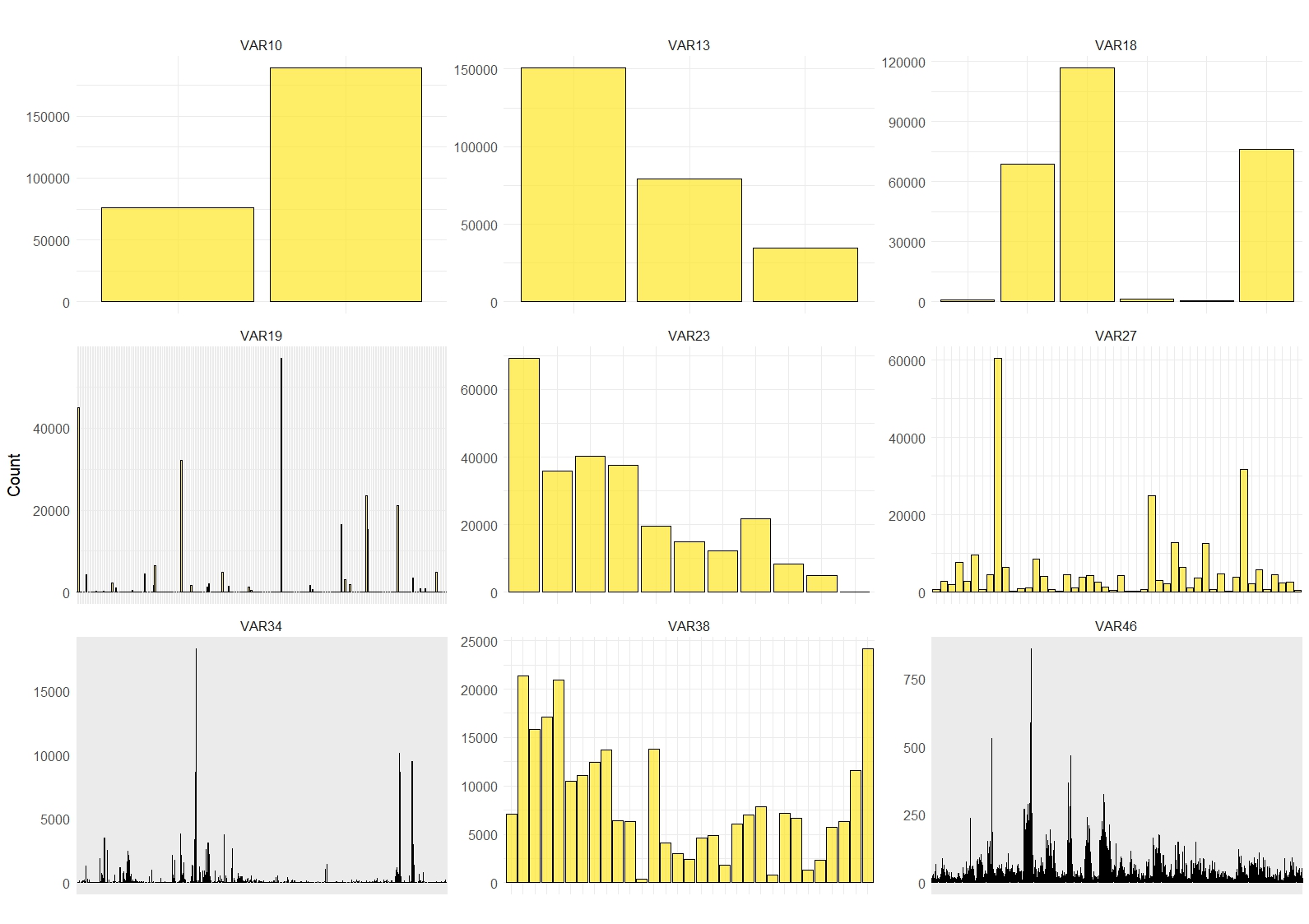
Before synthesizing a sample of the dataset, we discarded policies (rows) with zero or negative exposure. Additionally, variables where 99.9% or more of the observations fell into one category (i.e., the variable is essentially a constant) were discarded. Those variables are VAR2, VAR8, VAR14, VAR15, VAR29, VAR32, VAR42, VAR44, and VAR45.
Figs. 1A and 1B show the histograms of the remaining numeric and categorical variables, respectively.


3. RESULTS AND DISCUSSION
We took a sample of the original dataset (132,243 rows in the sample, along with the 40 columns remaining after the selection described in the variable description section above), divided the original dataset into a training and test set with a 70:30 ratio, and synthesized the training set using our synthesizer with K = 4. The test set was later used to evaluate the results of a severity model on both datasets to compare their performance.
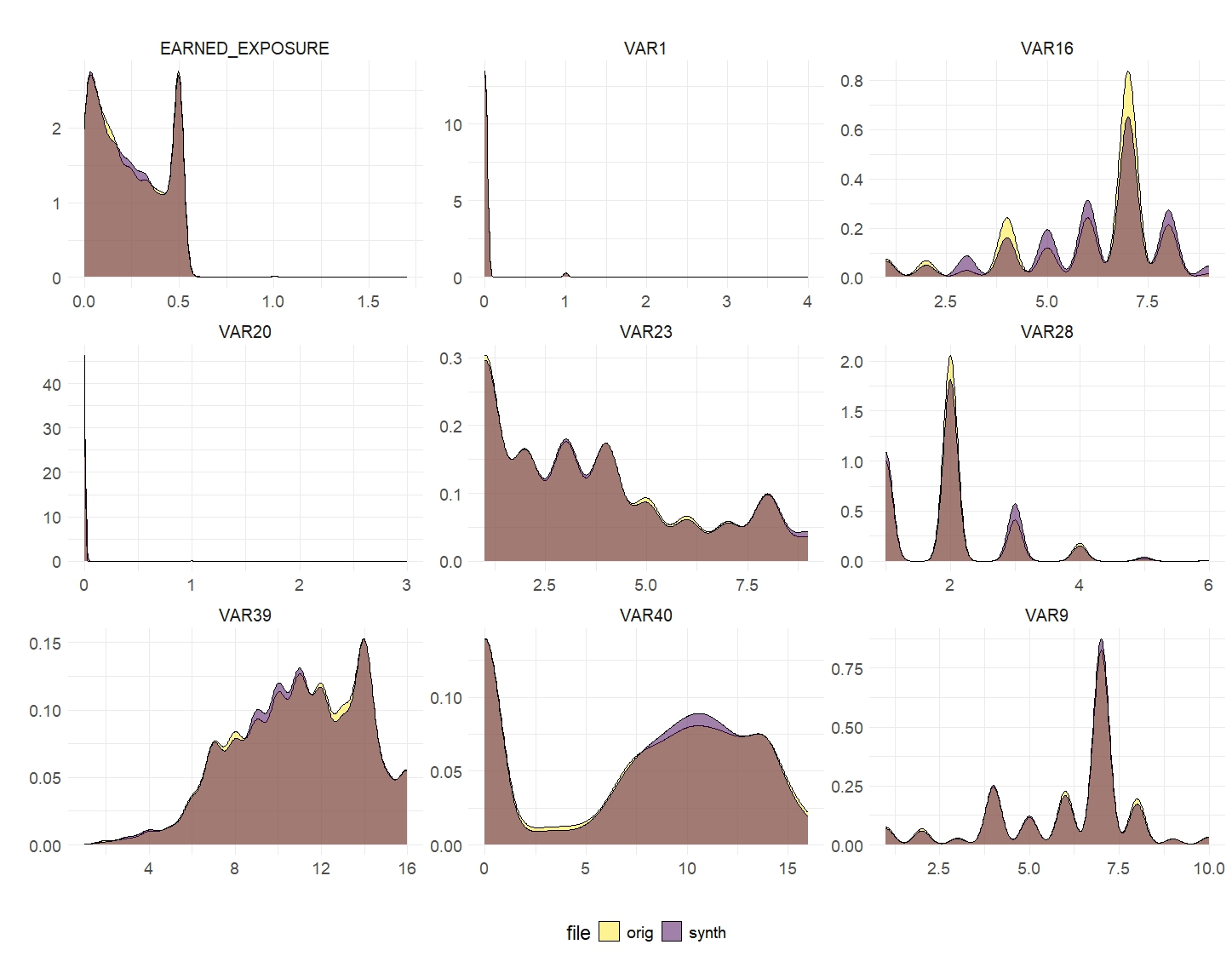
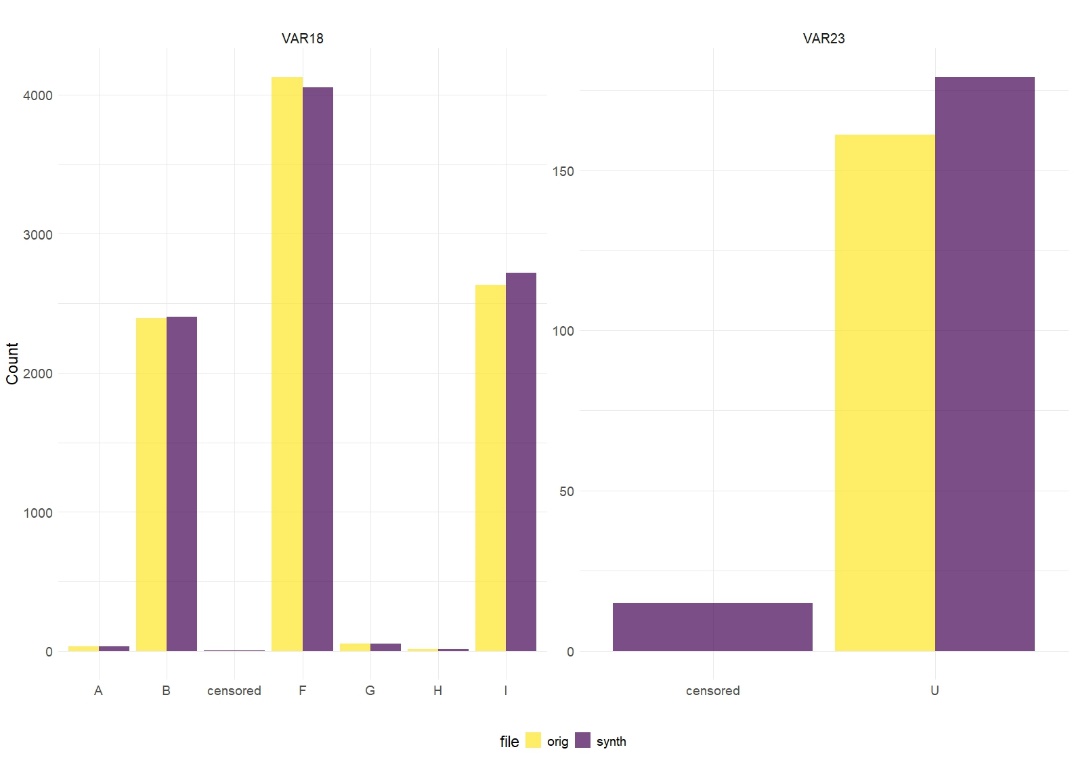
First, we compare univariate and bivariate statistics on both datasets. For brevity, we sampled 10 random variables to present these measures: eight numeric variables (EARNED_EXPOSURE, VAR1, VAR16, VAR20, VAR28, VAR39, VAR40, and VAR9) and two categorical variables (VAR23 and VAR18). Of note, all 40 features were synthesized, but only the above 10 are presented.
3.1. Univariate fidelity
Figs. 2A and 2B overlay histograms and bar plots comparing the marginal distributions of the variables between the original and synthetic training datasets, respectively. The distributions are very similar but not identical, as expected. Note the value “censored” appearing in the synthetic, but not the original, dataset. This is due to some small groups (smaller than K) that are formed in the original dataset when all categorical columns are considered, singling out fewer than K individuals. The formation of these groups forces the algorithm to unite some values into a generalized category called “censored.”


3.2. Bivariate fidelity
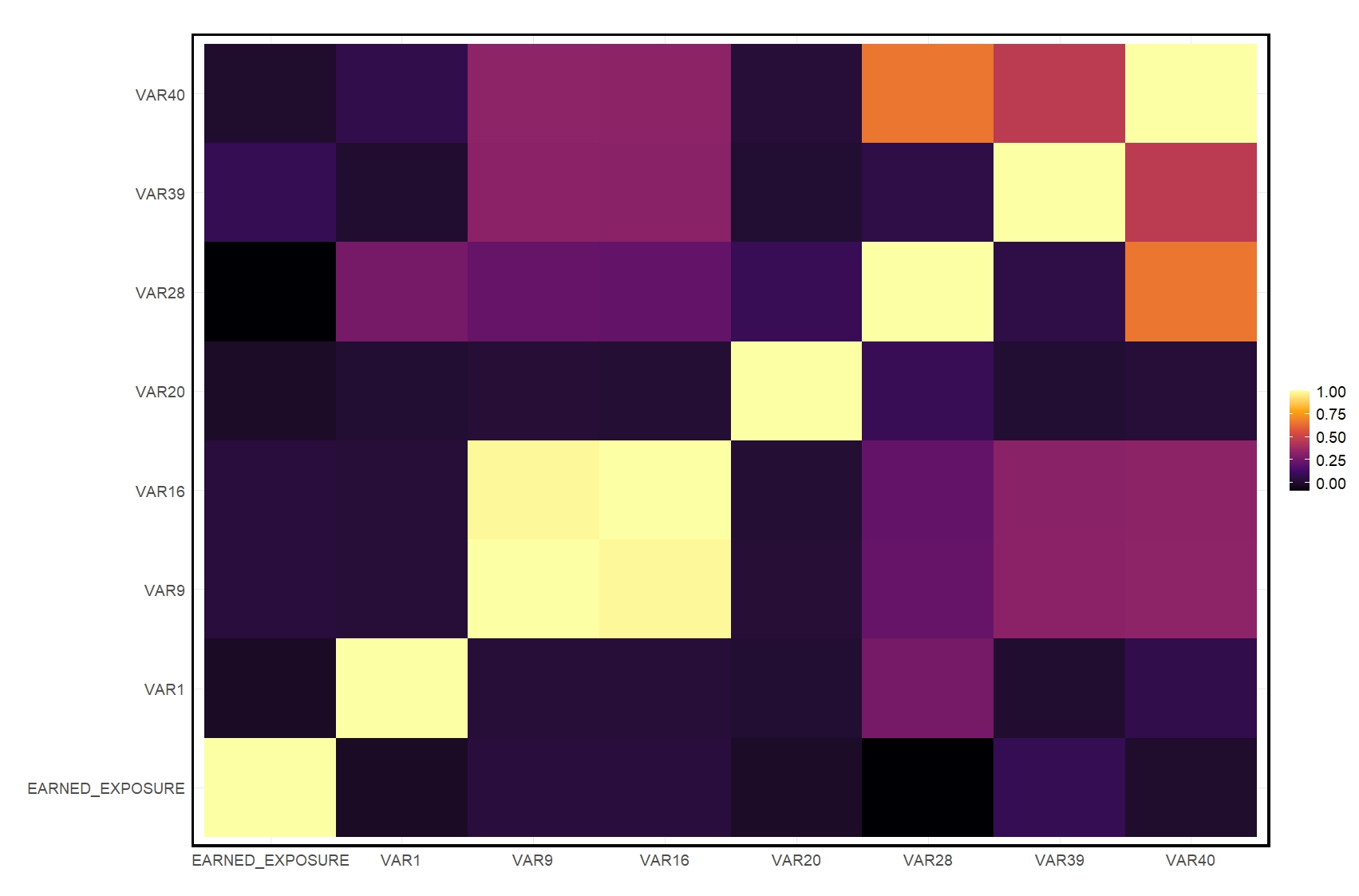
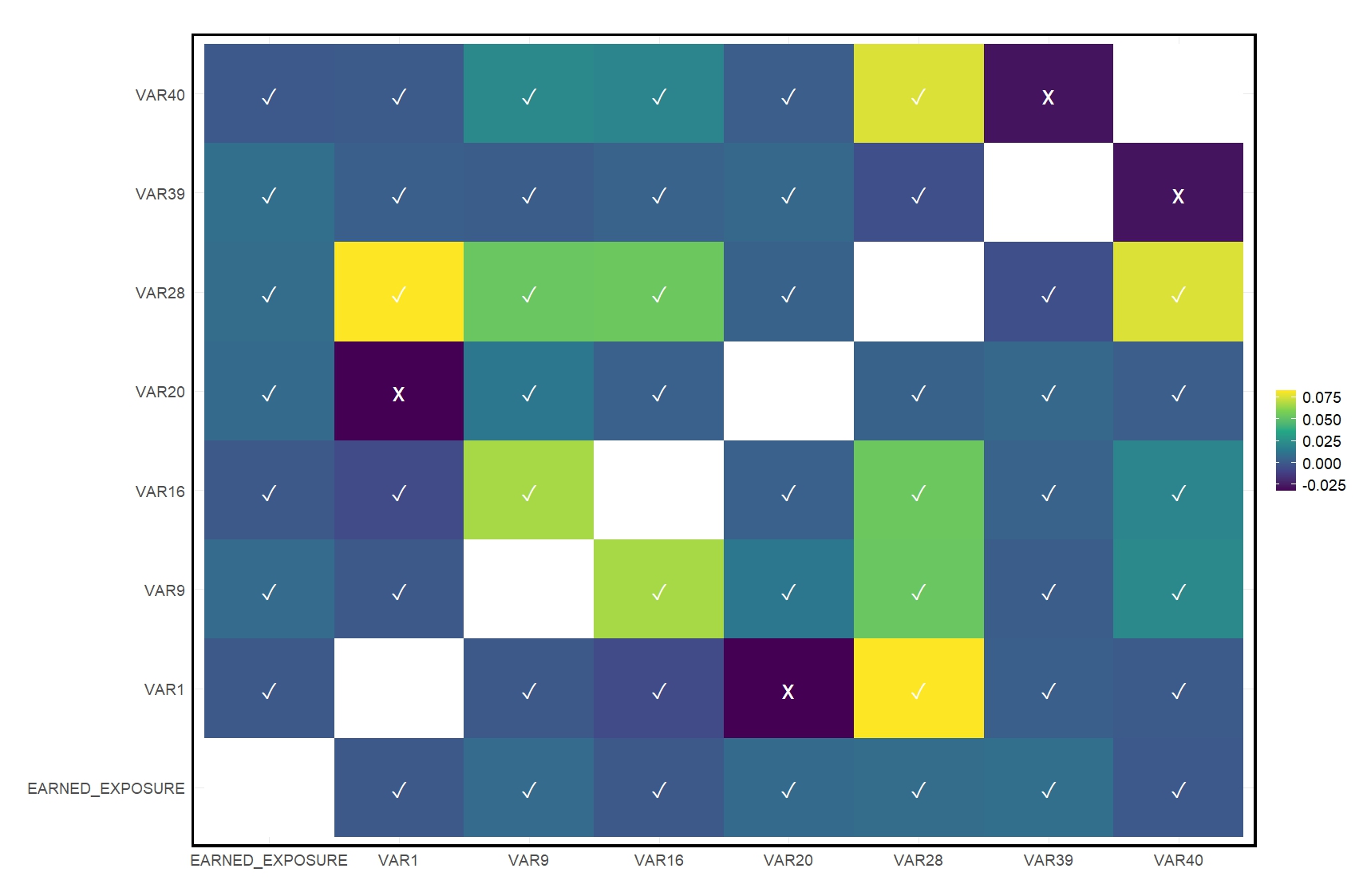
To assess the preservation of relationships between pairs of variables, we compared the Spearman correlation coefficients between the original and synthetic datasets by evaluating the p-values of the comparisons.
Figs. 3A and 3B show the Spearman correlation matrix in the original data and the difference in correlation values between the original and synthetic data, respectively.


The results show that for most variable pairs, the synthetic data demonstrates high fidelity (i.e., insignificant difference between the correlation in the original data and the correlation in the synthetic data). However, some variable pairs show deviations, as reflected in lower p-values, namely EARNED_EXPOSURE vs. VAR9, VAR16, and VAR28. These discrepancies can largely be attributed to the algorithm’s treatment of high-cardinality variables. In cases where these variables interact, the synthetic data generation process can generalize them to “censored” to reduce the risk of re-identification. This generalization tends to smooth out fine-grained subgroup details, which in turn affects the relationships captured by the correlations.
Alternatively, a more domain-specific approach to generalization could be adopted prior to synthesis. For example, rather than arbitrarily grouping postal codes into “censored,” domain knowledge could be leveraged beforehand to create aggregations that describe meaningful patterns to the stakeholder, such as regions or states. This targeted reduction in cardinality could help preserve the critical relationships between variables while maintaining privacy, thereby improving the fidelity of the synthetic data for downstream analyses.
3.3. Multivariate statistical utility
Fig. 4 compares the performance of the two trained frequency models (one trained on the original data and the other trained on the synthetic data) when applied to the common test set. The frequency model used was a Poisson log regression, where the outcome variable was the frequency (i.e., the ULTIMATE_CLAIM_COUNT divided by EARNED_EXPOSURE), weighted by EARNED_EXPOSURE.

In Fig. 4, the x-axis represents the predicted frequency bins for the original model, while the left y-axis shows the actual response rate in the test set for each bin, and the right y-axis indicates the profile count for each bin. The dots represent the actual response rate for the corresponding bin of predicted frequencies, with error bars depicting the confidence intervals. The original data closely matches the synthetic data, especially in bins with a significant number of profiles, as evidenced by the narrow confidence intervals. However, when the number of profiles in a bin is small, the predictions between the two datasets tend to diverge, resulting in wider confidence intervals. This behavior is expected and consistent with the goals of privacy preservation, where exact matching of distributions in sparsely populated bins is avoided to protect individual-level details.
3.4. Privacy
A privacy-preserving algorithm must ensure that no sensitive information about individuals, or rows, in the original data leaks into the synthetic dataset, which is intended for publication or broader access. A fundamental test of this requirement is to confirm that none of the rows in the original data exist fully intact in the synthetic dataset. However, this basic test can be criticized as overly simplistic. For instance, if the algorithm slightly modifies each value, such as adding an insignificant digit to each number, the test for identical rows would fail while still allowing the synthetic data to closely resemble the original data, thus compromising privacy.
To address this limitation, a more robust metric involves grouping similar values in both the original and synthetic datasets using quantiles, such as dividing each column into 10 quantiles. After this transformation, we can perform an inner join between the original and synthetic datasets. Ideally, this join should yield no matches, indicating that no individual in the original data has a synthetic counterpart with values that fall into the same quantile group across all columns. Since synthetic data generation is inherently stochastic, we might observe a small proportion of matches purely by chance. However, these matches should be random and vary with each run of the synthesizer.
To test this approach, we ran the synthesizer 10 times and observed an average of six (6) matches per run (out of 92,561 records synthesized). Importantly, these matches were not consistent across runs—indicating that the algorithm does not deterministically single out specific individuals in the original dataset. This result suggests that the synthetic data generator avoids creating synthetic derivatives that could reliably identify any individual, thereby upholding the privacy-preserving requirements.
An additional layer of privacy testing involves robustness against membership inference attacks (El Emam, Mosquera, and Fang 2022). In such attacks, adversaries aim to determine whether a specific individual’s data was used in a model’s training dataset. Successful membership inference attacks can also serve as a foundation for attribute inference attacks, compounding privacy risks. Attribute inference attacks seek to deduce sensitive attributes of individuals in a dataset by leveraging patterns learned from membership information. For example, if an attacker confirms through a membership inference attack that a specific individual’s data is included in a training set, they can use this knowledge to infer other sensitive attributes (e.g., if this individual’s data was inferred to be included in a claims dataset, then this would imply that the individual had prior accidents or incidents leading to claims).
To simulate a potential membership inference scenario, we divided a portion of the original dataset into a training and test set in a 50%-50% ratio (the reason for using a portion is due to the computational effort involved in calculating distance matrices; in production this can be solved using parallel computation). The training set was used to synthesize the dataset, while the test set was held back for evaluation purposes. Additionally, we sampled another 50% of the original data, which we assumed an attacker may have access to, labeling it as the accessible dataset. This division is meant to mimic a scenario where an attacker might possess public or leaked records and wants to infer whether those records participated in model training.
We then calculated the nearest neighbor distances for three key pairs:
-
Train-Synthetic: the distance between the training data and the resulting synthetic data.
-
Test-Synthetic: the distance between the test data and the synthetic data.
-
Accessible-Synthetic: the distance between the accessible data and the synthetic data.
The distance measure we used was Gower’s distance, which is particularly well suited for mixed data types (numerical and categorical) (D’Orazio 2021). It computes a normalized similarity score for each variable and aggregates these scores to produce an overall distance.
The nearest neighbor distances from each dataset pair were extracted and compared statistically and were found to be statistically indistinguishable. This means that an attacker with access to part of the original data and the synthetic data cannot successfully determine whether those original records were part of the training data used to derive the synthetic data.
4. CONCLUSIONS
Synthetic data offers a viable pathway to addressing the dual imperatives of data utility and privacy in actuarial science. By preserving statistical fidelity while ensuring compliance with privacy standards, it enables actuaries to build robust models without compromising the privacy of policyholders. In this paper, we explored the use of a synthetic dataset as a proxy for a realistic dataset, which presented challenges such as sparsity, high cardinality, and multidimensional complexity.
We evaluated the fidelity of the synthetic data through univariate, bivariate, and multivariate performance assessments. The results confirmed that the synthetic data effectively preserves key statistical relationships, with deviations primarily attributed to the algorithm’s prioritization of privacy. Specifically, the algorithm smooths out details pertaining to groups smaller than a predefined privacy threshold K, generalizing or censoring small categories to prevent re-identification. This generalization introduces deviations, but it serves a critical role in maintaining compliance with stringent data protection standards like GDPR and CCPA.
These deviations, while expected in privacy-preserving methods, can be mitigated through domain-specific generalizations. For example, instead of arbitrary aggregation of high-cardinality variables such as postal codes, grouping them into clusters based on meaningful patterns—such as accident frequency clusters or risk-based segmentation—could improve fidelity. Such targeted adjustments leverage domain knowledge to preserve critical relationships essential for accurate actuarial modeling without exposing identifiable information.
The privacy-utility tradeoff underscores the dual advantage of minimizing data complexity while strategically leveraging granular information in actuarial ratemaking. Reducing the number of columns and the level of detail required aligns with privacy laws like GDPR and CCPA, which emphasize data minimization. Fewer columns and less granularity not only simplify the task of preserving privacy but also improve the fidelity of synthetic data by reducing the need for generalizations that could dilute statistical relationships. However, granular data often contains critical insights essential for accurate and meaningful modeling. The key is to include such details selectively—only to the extent they are required and add value to the specific task at hand.
Synthetic data generation in fact supports this approach through its inherently iterative nature. After an initial round of synthesis and modeling, actuaries can assess the utility of the synthetic data and refine their understanding of which features are truly necessary for the analysis. This iterative feedback loop enables the selective re-introduction of meaningful granularity while discarding unnecessary details, striking an optimal balance between privacy and utility. By progressively fine-tuning the synthesis process, actuaries can ensure that granular data is utilized only where it is indispensable, while maintaining compliance with privacy standards and maximizing the utility of synthetic datasets. This dynamic and adaptive approach highlights the transformative potential of synthetic data in reconciling privacy with analytical precision.
The adoption of synthetic data in actuarial science is poised to transform the field by addressing critical challenges in data accessibility, privacy, and innovation. As regulatory pressures and data privacy concerns continue to grow, synthetic data offers a promising solution that ensures compliance while maintaining the analytical utility required for accurate modeling.
Looking ahead, several key trends and developments are likely to shape the future of synthetic data in actuarial science. First, the development of industry-wide standards and best practices for generating and validating synthetic data could become essential. Second, automation of pipelines capable of generating and validating those datasets in real time would become increasingly necessary. Third, synthetic data could foster greater collaboration across the insurance industry by enabling secure data sharing among insurers, regulators, researchers, and technology partners. Shared synthetic datasets could allow actuaries to benchmark models, test new methodologies, and develop innovative solutions to emerging risks. This collaborative approach could drive advancements in pricing strategies, risk assessment, and regulatory compliance. Fourth, the adoption of synthetic data may necessitate new educational initiatives to train actuaries in its use. Curricula in actuarial science programs would include modules on synthetic data generation, privacy preservation, and validation techniques. Finally, synthetic data has the potential to bridge the gap between regulatory compliance and technological innovation. By providing a privacy-preserving alternative to traditional datasets, synthetic data could enable insurers to innovate while remaining compliant with data protection laws. This balance could be crucial as insurers adopt cutting-edge technologies like artificial intelligence and predictive analytics.
Acknowledgment
N.Z. acknowledges fruitful discussions with Daniel Lupton, Joseph Griffin, and Brian Chiarella during the preparation of this paper. N.Z. also expresses gratitude to Earnix for providing a supportive environment that facilitated this research. The views expressed in this paper are solely those of the author and are academic in nature; they do not necessarily reflect the official positions or policies of Earnix.