
















































Introduction
The benefits of using Bayesian MCMC for a reserve analysis are described in the monograph “Stochastic Loss Reserving Using Bayesian MCMC 2nd Edition” by Meyers. In that monograph, he demonstrated that Bayesian MCMC provides a useful platform for doing a reserve analysis, since those estimates tend to be more accurate than those estimated via link ratio based methods. As Meyers noted in his monograph, with the availability of the STAN software and related tools, it has become more practical to use Bayesian MCMC.
The benefits of using a smooth curve, developed via some form of regression, to model reserve estimates are described in the monograph by Taylor and McGuire, “Stochastic Loss Reserving Using Generalized Linear Models.” At the end of their monograph, they noted that one could fit a smooth curve to describe a development pattern rather than model development one year at a time, which reduces the risk of overfitting. The approach Taylor and McGuire suggested moves the modeling problem from fitting a series of categorical variables to fitting a set of smooth curves (one may need a small number of categorical variables early in the development year pattern). Using a GLM though, requires enough data to train the model parameters which may not be possible with a sparse data set.
The prior distribution parameter feature of Bayesian MCMC enables an actuary to fit a smooth curve to a development pattern when working with a sparse data set by incorporating accumulated knowledge to supplement the available data. By utilizing this feature, an actuary can assign a distribution with a specified mean and standard deviation to each of the coefficients in a regression model.
The Bayesian MCMC routine will weight the prior distribution values for the regression parameters with results from fitting the loss triangle to create a posterior distribution for each coefficient. In credibility weighting terms, the prior distributions serve as a compliment of credibility. The reserve modeling examples given in this paper will illustrate how setting the prior distribution parameters can produce plausible ultimate loss reserve distribution estimates when combined with the available data.
A practical way to view the prior distribution feature of Bayesian MCMC is that it allows the actuary to set guard rails for the MCMC machinery in its search for the optimal set of parameter estimates, eliminating the need to search the entire real number line. By narrowing the range of plausible results for the coefficient estimates, the actuary makes the MCMC task more manageable and significantly reduces the likelihood of the process producing nonsensical results for the forecast loss reserve distribution.
If the data set contains sufficient information, the results derived from the data, under normal circumstances, will override the prior distributions. This is similar to our credibility weighting approach, where for data sets with ample information, the indications from the data set receive nearly 100% credibility, while the compliment of credibility receives 0% or a small percentage. However, it is possible to configure the prior distribution to prevent the MCMC routine from exploring certain regions of potential answers, which is why the caveat “under normal circumstances” is necessary.
This paper is centered around a series of reserve modeling examples that were created with the goal of illustrating the concepts described above. Before we can get to those examples, some introductory comments are necessary.
I.1. Linking Credibility Weighting to Prior Distributions
Most actuaries have some exposure to regression modeling, and many CAS members may recall studying Bayesian conjugate prior credibility weighting and least squares credibility weighting concepts for their exams. However, the idea of developing a set of prior distributions to describe the likely range of values for the coefficients in a regression equation, as a means of incorporating a form of credibility weighting into a model, may be unfamiliar to a significant portion of the actuarial community.
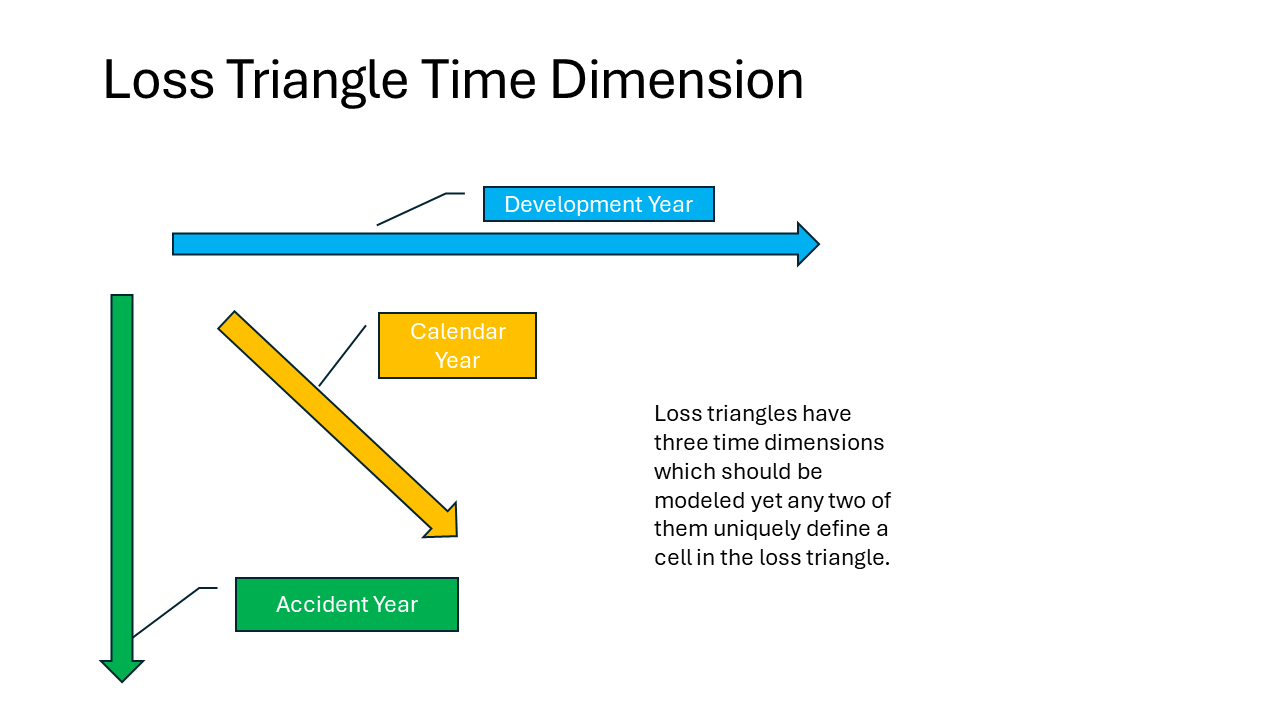
Loss triangles have three time dimensions: accident year, calendar year and development year. In the reserve models that follow, the type of credibility weighting will vary by time dimension.

The regression coefficients for development year and calendar year will have prior distributions with selected parameters that are adjusted by the data to form a posterior distribution for each coefficient. These regression coefficients are for variables that fall under the population variable category.
The regression coefficients for accident year will be classified as group variables and will be modified using a least squares-type credibility weighting. This means that the prior distribution parameters, which control the weighting between a group’s estimate and the overall estimate, will be calculated based on the data set.
Each variable in a Bayesian MCMC model will have a prior distribution and the instructions to set up the prior distribution will be contained in the code used to call STAN.

Please note that the prior distributions used in a Bayesian MCMC model differ from those in the credibility weighting concepts we read about on the exams for Bayesian conjugate prior combinations, as they are not limited to the distributions that form conjugate priors. The development of efficient algorithms in the MCMC environment has freed us from this constraint by eliminating the need to calculate the weighted average denominator required to move from the prior to the posterior distribution.
The way Bayesian MCMC handles group variables in terms of credibility weighting shares some similarities with least squares credibility weighting, but the terminology differs. Least squares credibility weighting examines how the data behaves in terms of variance of the group means relative to process variance. This means the credibility weighting between the group estimate and the overall estimate is driven by the data’s behavior rather than a selected prior distribution.
In the Bayesian MCMC environment, achieving a similar effect involves using a model structure where the prior distribution for the group variable depends on another layer of priors (hyperparameters) forming a hierarchical model. The hyperparameters are estimated from the data at hand. In the Bayesian MCMC literature, this approach is described as partial pooling, which is a compromise between pooling (assuming no difference in by group behavior) and modeling each group separately (no pooling). Partial pooling is useful when information about one group’s behavior can improve the estimates for the other groups’ behavior, even though they are not identical. We will revisit this topic when we set up the first reserve model.
I.2. Reserve Analysis Example Overview
The reserve analysis examples will be set up to forecast incremental loss payments. The reserve estimate will be the sum of the forecasted future incremental loss payments.
The incremental payments will be normalized prior to modeling to make it easier to focus on common development patterns across the accident years. The normalization process will be reversed when the modeling process goes from estimating the modeling parameters to forecasting the future incremental payments.
The normalization process will have two parts:
-
Dividing the incremental payments by an exposure base attached to the accident year. The exposure base in this case will be reported claim counts at 12 months of development.
-
Dividing the incremental payments by an inflation index. We will accomplish this by the use of a simulated inflation index.
Normalizing the incremental payments will make it easier to view the underlying development pattern across accident years by removing the effect of varying business volumes and putting the dollar values of payments on a common basis.
The normalized incremental payments will be modeled using the lognormal distribution and will be referred to as deflated pure premium values in the sections that talk about the reserve modeling results. The mu and sigma values for the lognormal distribution will be modeled as a function of accident year, development year and calendar year. The formulas used to fit mu and sigma will be described once we move into the reserve model examples.
An outline of the sequence of steps used to build the reserve model examples in this paper is given below:

The sequence is similar to the usual sequence of steps in building a GLM model:
-
Build the data sets.
-
Do some exploratory analysis to understand the data.
-
Set up the model.
-
Run the model.
-
Evaluate the model results.
There are some differences:
-
The loss triangle data sets are built via simulation.
-
There is a simulation routine to generate inflation and loss cost trend.
-
Inclusion of prior distributions.
-
Posterior distribution of results rather than point estimates
The data sets for the incremental loss triangles were built via simulation for the purpose of illustrating when selecting the prior distribution parameters using insight developed from on the job reserving experience can be useful. The loss triangles were created so as to mimic a generic pattern for liability lines where incremental payments start slowly, peak after a few development years and then taper to close to zero dollars per development period as the accident year ages with the development pattern becoming more unstable at later development periods. For this paper, simulating the data sets had the advantages of eliminating the need to obtain data from a company and allowing anyone who opens up the code to see an example of how one can use simulation to build data sets and experiment with building a Bayesian MCMC model. The data sets were simulated by inverting the Poisson distribution to generate incremental paid counts and inverting the lognormal distribution for the severity amounts with the parameters for these distributions set in the code. More details on the data set construction can be found in Appendix A.
The simulation routine to generate inflation and loss cost trend sets up the ability to attach a distribution of inflation forecasts to the distribution of incremental loss cost estimates to give a realistic picture of the variability of the reserve estimates.
The Bayesian MCMC routines generates a random sample of the parameters for a posterior distribution rather than point estimates. Point estimates of the coefficient values can be obtained by summarizing the information in the posterior distribution data set. This approach contrasts with the GLM process, where one would need to bootstrap the model results to obtain a distribution.
The process used to generate the reserve model forecast is summarized below:

One can apply the model results to future explanatory variables (future development years for the set of accident years) to obtain a forecast which is similar to a GLM modeling routine, but the forecast will be in the form of a distribution of future results.
More detail on the steps behind creating the forecast distribution can be found in Appendix B.
Information on the software selected to create the examples can be found in Appendix C.
I.3. Reserve Analysis Example Scope
This paper focuses on how Bayesian MCMC can assist actuaries in dealing with sparse data in reserving through the prior distribution feature of Bayesian MCMC. In a typical reserve analysis, one would investigate multiple models with different explanatory variables to evaluate their forecasting reliability. However, this paper will not delve into the analysis required to compare different potential model forms (different explanatory variables) using metrics such as a form of the AIC statistic or cross-validation adapted for Bayesian MCMC models. Additionally, while the Bayesian MCMC modeling process usually involves examining and commenting on diagnostics to ensure that the MCMC machinery is functioning correctly, these comments will be omitted from the discussion in this paper.
There are five data sets used in the reserve model examples, each with a decreasing amount of information in the loss triangles to illustrate how the benefit of selecting a prior distribution set of parameters increases as information decreases. The same set of frequency and severity distribution parameters were used to simulate the incremental losses for all data sets. Each data set will be modeled with and without selected prior distributions parameters, using the same set of explanatory variables for each case. The data sets will be labeled by case number when reviewing the reserve modeling results:
- Case 1 has 22 accident years (2000 through 2021) with a uniform reported claim count of 1000 reported claims at 12 months for each accident year and a maximum of 22 years of development time.
- Case 2 has 22 accident years (2000 through 2021) with a uniform reported claim count of 500 reported claims at 12 months for each accident year and a maximum of 22 years of development time.
- Case 3 has 22 accident years (2000 through 2021) with a uniform reported claim count of 100 reported claims at 12 months for each accident year and a maximum of 22 years of development time.
- Case 4 has 22 accident years (2000 through 2021) with a uniform reported claim count of 50 reported claims at 12 months for each accident year and a maximum of 22 years of development time.
- Case 5 has 11 accident years (2011 through 2021) with a uniform reported claim count of 100 reported claims at 12 months for each accident year and a maximum of 22 years of development time.
Comparing modeling results for different data sets with and without selected prior distributions will illustrate how the value of using selected prior distributions varies based on the information in the loss triangle data set. While there will be a limited review of the model’s reasonableness in fitting the data, the examples will primarily focus on how using selected prior distributions can reduce forecast uncertainty. Please note that if the analyst does not select a prior distribution for a given parameter of a population variable, the program will insert flat priors by default which implies the entire real number line provides a set of equally likely results for that parameter.
II. Case 1 Modeling Results
Case 1 has 22 accident years (2000 through 2021) with a uniform reported claim count of 1000 reported claims at 12 months for each accident year and a maximum of 22 years of development time.
II.1. Exploratory Data Analysis
EDA exhibits are included to illustrate the usual and customary process of building a Bayesian MCMC model by starting with EDA exhibits. The graphs are a starting point for formulating potential regression equations for the distribution parameters and checking for outliers.
The Exploratory Data Analysis (EDA) exhibits for the different cases are combined in most of the graphs below since the underlying frequency and severity parameters are the same for each case. The different data sets are denoted by color in the graphs that combine different data sets with the legend at the bottom of the graph giving the color code that identifies the Case number.
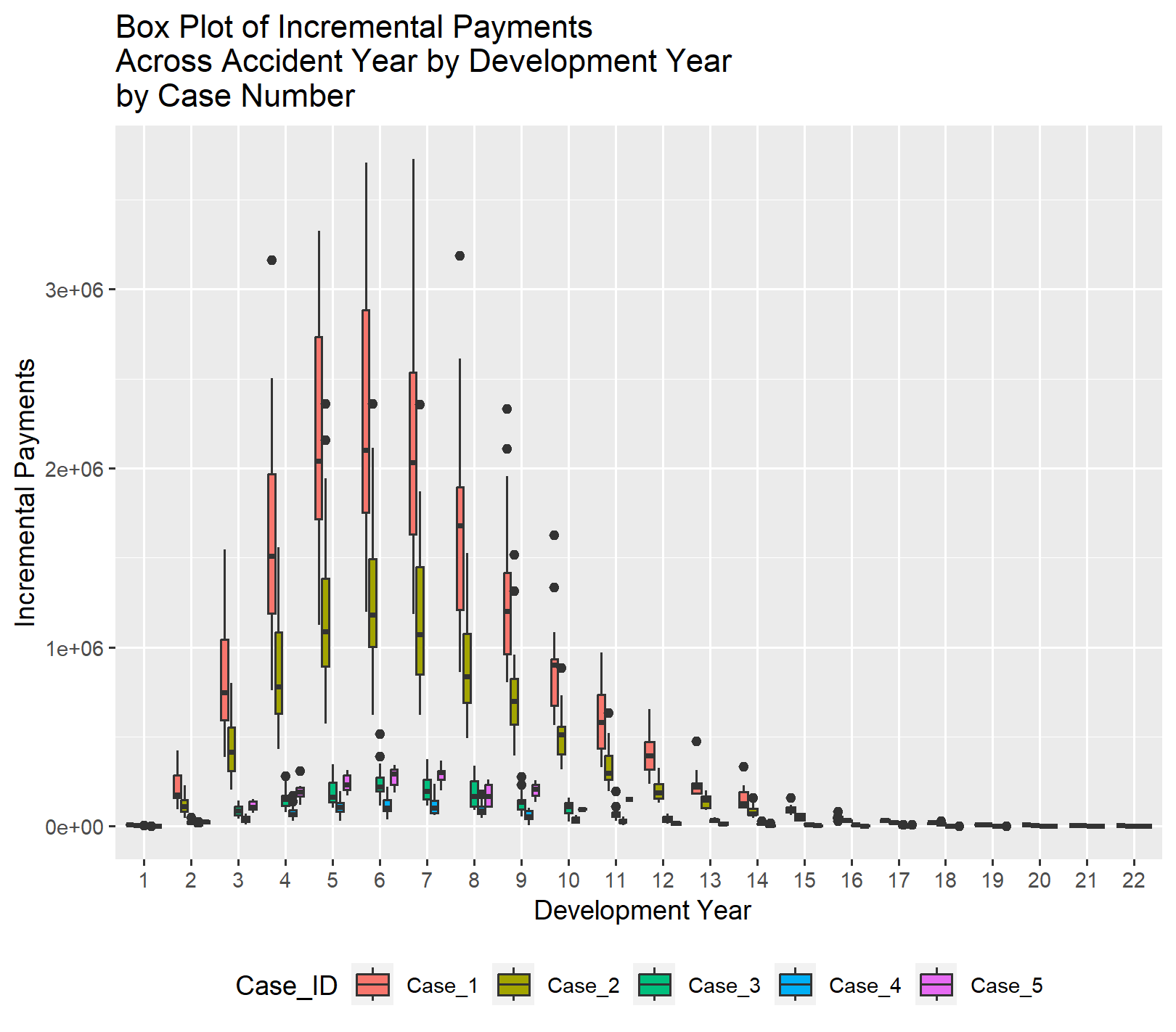
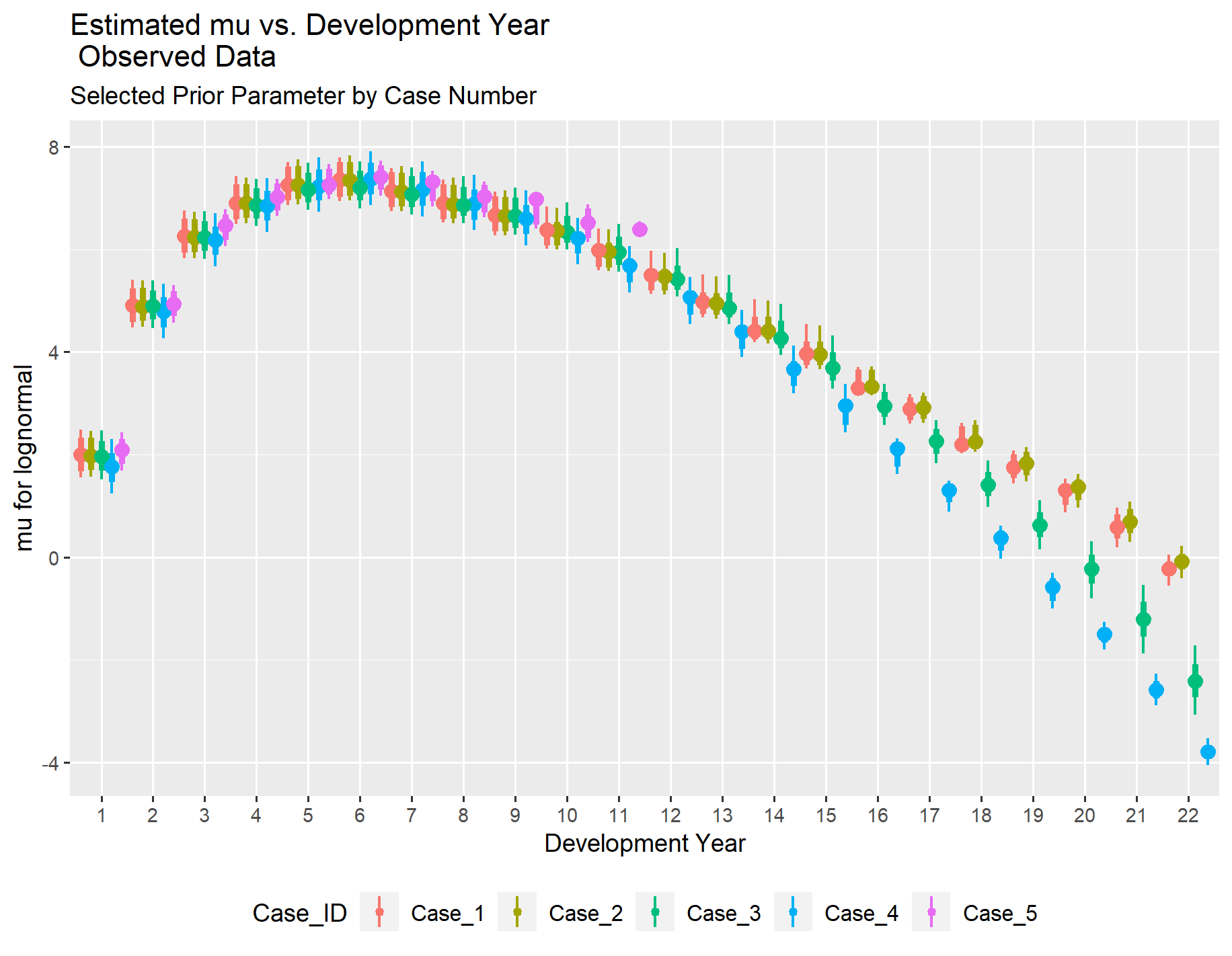
The first graph shows the incremental payments prior to normalization. Subsequent graphs illustrate that as adjustments are made to normalize the values and then transform them to the log scale, the inherent pattern of how incremental payments behave as an accident year ages becomes clearer.

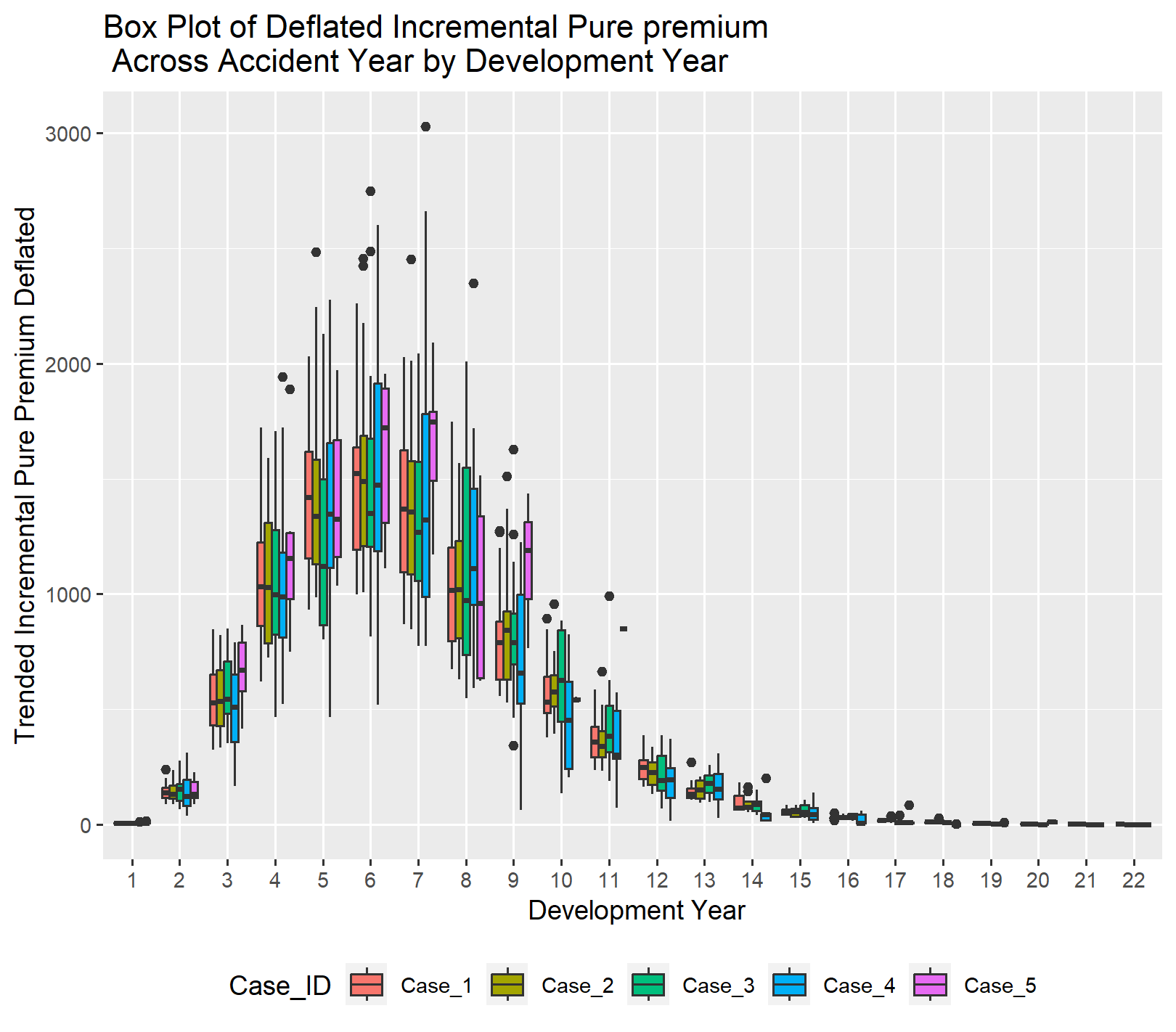
By normalizing using the reported claim count to account for the volume of business and adjusting for inflation to put the dollar values on the same scale, the similarity in the pattern across the cases becomes clearer. Please note that the additional loss cost trend beyond general inflation is still reflected in the normalized pure premium values below.
Since Case 5 does not include any development years beyond eleven years, you will not see any data for Case 5 beyond eleven years in the EDA exhibits.

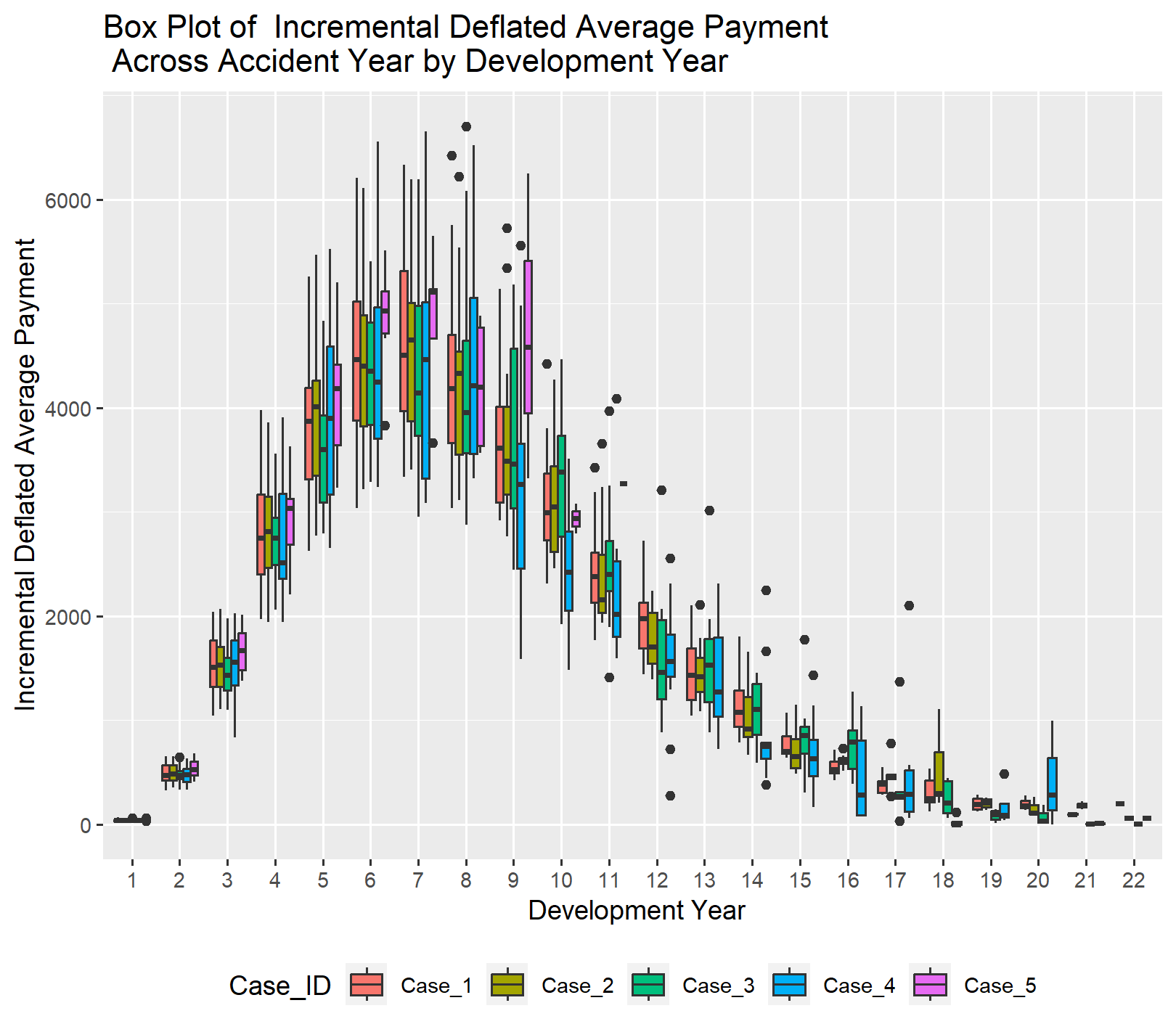
The next set of graphs examine the frequency and severity components of the pure premium graph above. For the incremental average severity, it is important to note that Case #5 includes a higher proportion of observations from more recent calendar years compared to the other cases. This is because it only encompasses the most recent ten accident years, which tends to skew the incremental average severity higher than the other cases.

The incremental frequency plot is given below. Incremental frequency tends to peak at either development year three, four or five while incremental average severity tends to peak at age six or seven.

If we look at the incremental normalized pure premiums on the natural log scale using a QQ plot for Case #1 as a representative sample, the graph below indicates that using a lognormal distribution for modeling the incremental normalized pure premiums is a reasonable choice.

The line graph of the average natural log of the normalized pure premium values highlights a few key points:
-
The results for Case 1 and Case 2 are similar across time and have smooth pattern.
-
Case 3 and Case 4 have a similar pattern to the two cases with higher reported claim counts, but the pattern is not as smooth.

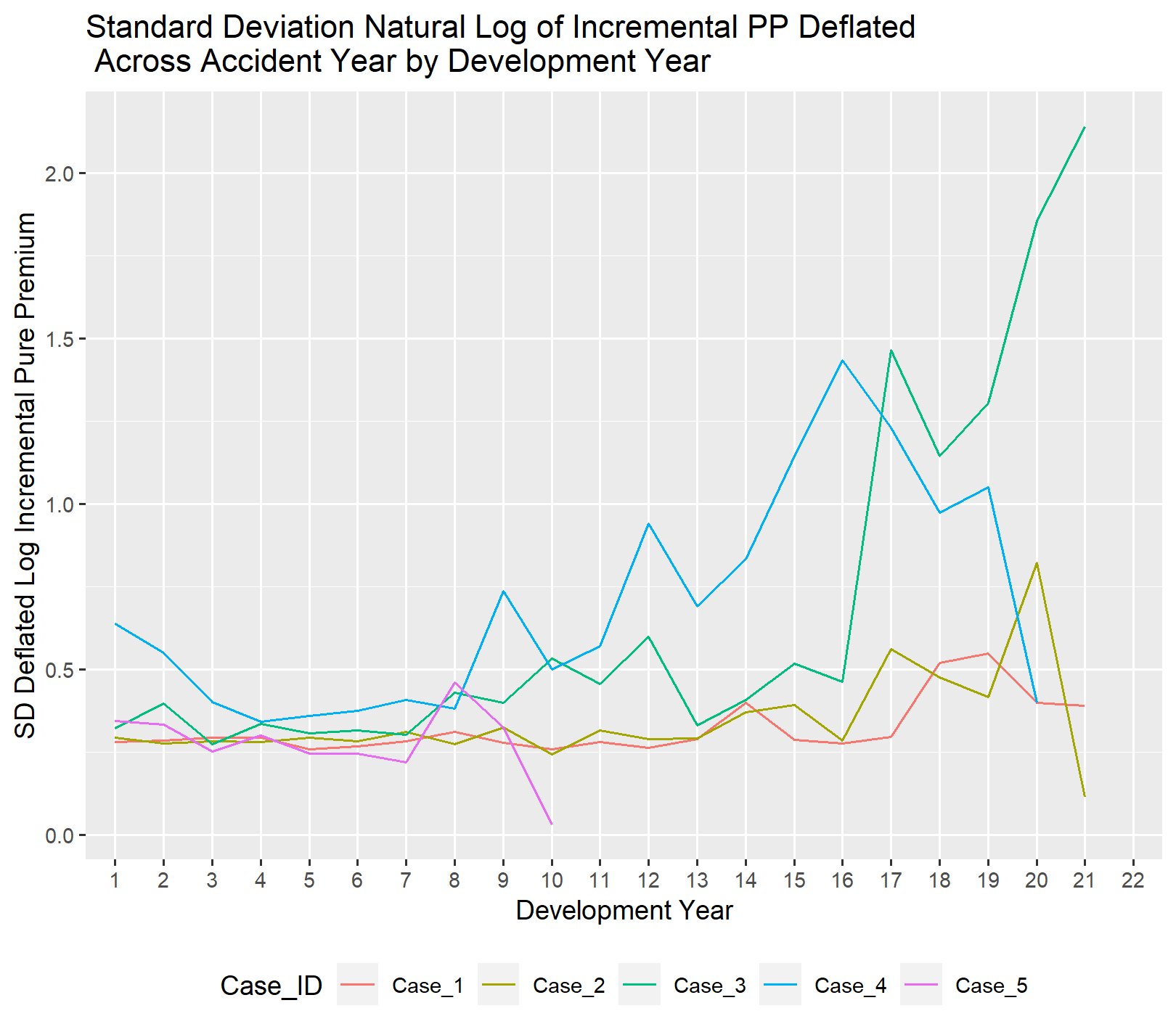
The sigma value for the lognormal distribution varies across development years. Unlike the mu parameter, the indications for sigma are less consistent across cases. Cases with fewer reported claims exhibit greater instability as the accident year ages.

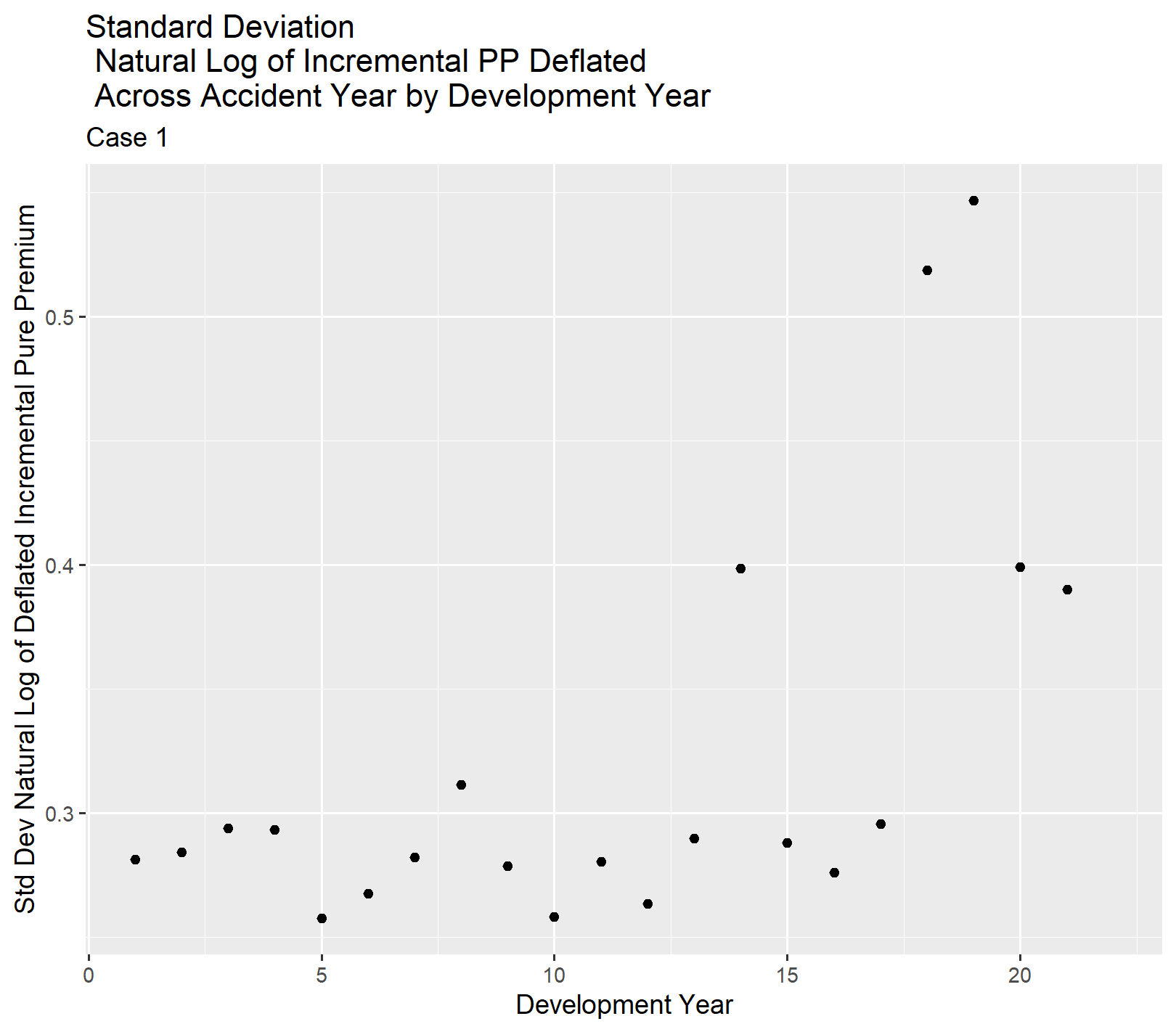
The difference in scale between the cases for sigma makes it necessary to look at Case 1 by itself to identify a likely starting point for a pattern to specify in the Bayesian MCMC models. It looks like sigma is roughly constant for the first ten years then starts to gradually increase.

II.2. Parameter Estimates Based Solely on Prior Distribution Selection
This section has two goals:
- Illustrate what it means to select prior distributions for the coefficients in the Bayesian MCMC model equations.
- Provide an example of how to review the results of selecting a set of prior distributions for a development curve formula and parameters beyond the observed development period in a new line of business before running the Bayesian MCMC model.
Before addressing those two goals, we need to introduce some of the terminology that will be used in the reserve model results throughout the rest of this paper.
The same explanatory variables will be used throughout this paper. The variables were selected to follow the patterns illustrated in the EDA exhibits for mu and sigma on the lognormal scale. A description of the variables used follows:
- Dev_Yr_2_Factor: A categorical variable for the first three development years
- Dev_Yr_6_Cap: A continuous variable that is capped at 6 for all years after development year 6.
- Dev_Yr_6_Cap_Sqrd: Dev_Yr_6_Cap * Dev_Yr_6_Cap
- Dev_Yr_6_Spline: A continuous variable equal to 0 if development year <7 and development year - 6 otherwise
- Dev_Yr_6_Spline_Sqrd: Dev_Yr_6_Spline * Dev_Yr_6_Spline
- Cal_Yr_Time: A continuous variable equal to Accident Year + Development Year – 1 -2000
- Dev_Yr_10_Spline: A continuous variable equal to 0 if development year <11 and development year -10 otherwise
- Dev_Yr_10_Spline_Ln: A continuous variable equal to 0 if development year <11 and log(development year -10) otherwise
- (1||Acc_Yr): A group variable (the prior variables are population variables) that adjusts the intercept by accident year after a form of credibility weighting to reflect a given group’s effect on the Intercept. Please note that the “||” within the parentheses is included to tell the program to assume that the accident years are not correlated. This set of examples assumes all observations are uncorrelated, but one may need to account for correlation in modeling work on the job.
Each example will include an extract of the summary of the modeling posterior distribution results for the population variables (those not receiving the least squares type credibility weighting). A brief description of the terms used in these summary exhibits is provided below:
- Coefficient: The name of the explanatory variable being modeled
- Estimate: mean of posterior distribution for that parameter
- Std_Err: standard deviation of the parameter estimate for the posterior distribution
- LB_CI_95: lower bound of the 95% confidence interval for the parameter estimate from the posterior distribution
- UB_CI_95: upper bound of the 95% confidence interval for the parameter estimate from the posterior distribution
The results for each model will also display the prior distribution definitions used, along with instructions on how to build the model to generate the Bayesian MCMC results. A summary of selected columns from the prior definitions table includes:
- Prior_Distribution: prior distribution for the coefficient and selected parameters for that distribution.
- Variable_Class: type of coefficient either a b for a beta in a regression equation or sd for standard deviation (used for group variable).
- Coefficient: name of explanatory variable attached to the coefficient
- Group_Indicator: identifies a group variable (blank for population variables)
- Distribution_Parameter: identifies distribution parameter variables besides the mean (in this case sigma) with a blank indicating that coefficient is part of the regression equation for the mean (mu in this case). This particular model assumes that sigma should be modeled separately and simultaneously with mu for the lognormal distribution. There are other distributional models one could use to match the behavior of a different data set.
- Source: either “user” (user selects prior distribution) or “default” (flat prior)
If you choose to run the code in the attached files, please note that I renamed the labels from the summary exhibit and the prior distribution exhibits produced by running the models in Rstudio. This was done to make it easier to follow the discussion.
The results presented in this section were generated by running the model without using the loss triangle data set. This feature allows for the evaluation and documentation of the initial assumptions for the reserve analysis.
As an example of reviewing starting assumptions, the results below show the implied development curves for mu and sigma based solely on the prior distribution selections used in modeling Case 1 and 2. Please note that the parameter results shown under the “Estimate” column are just the selected prior distribution figures along with their standard errors, shown under the “Std_Err” column, in this particular run. This will not generally be true in general. The prior distribution selections for Case 3, 4 and 5 will be described when those model results are presented.
For this example, the prior distribution for the Dev_Yr_6_Cap coefficient is set to a Normal distribution with mean equal to 1.5 and a standard deviation of 0.2. These figures are reflected in the results summary for this example, with a slight variation due to simulation noise. By examining the figures for other explanatory variable coefficients, one can observe the same pattern, illustrating how to review the implications of the selected prior distributions. Normally, the posterior distributions of the parameters will differ from the prior distributions.
There are separate regression equations for mu and sigma. In the table below, the coefficient labels for sigma start with “sigma_” followed by the name of the explanatory variable appended. The coefficient labels for mu are simply the names of the explanatory variables included in the regression equation for mu.
In practice, prior parameter estimates do not have to be calibrated to match the data to provide useful guard rails for the convergence routines in STAN, rather they just need to be plausible. In this case, plausible would mean you would feel comfortable presenting the results to another actuary experienced in reserving.

There are a variety of approaches to setting up the prior distributions for a reserve model. One could run a GLM model focusing on the development pattern for a loss triangle for a similar line of business or, if sufficient data is available, use the loss triangle to be modeled. Sometimes, experimenting with different equations and parameters in EXCEL can provide a logical starting point for setting the mean values in the prior distributions, with the standard deviation set by informed judgement on the degree to which the actuary believes the compliment of credibility should influence the posterior distribution coefficient estimates.
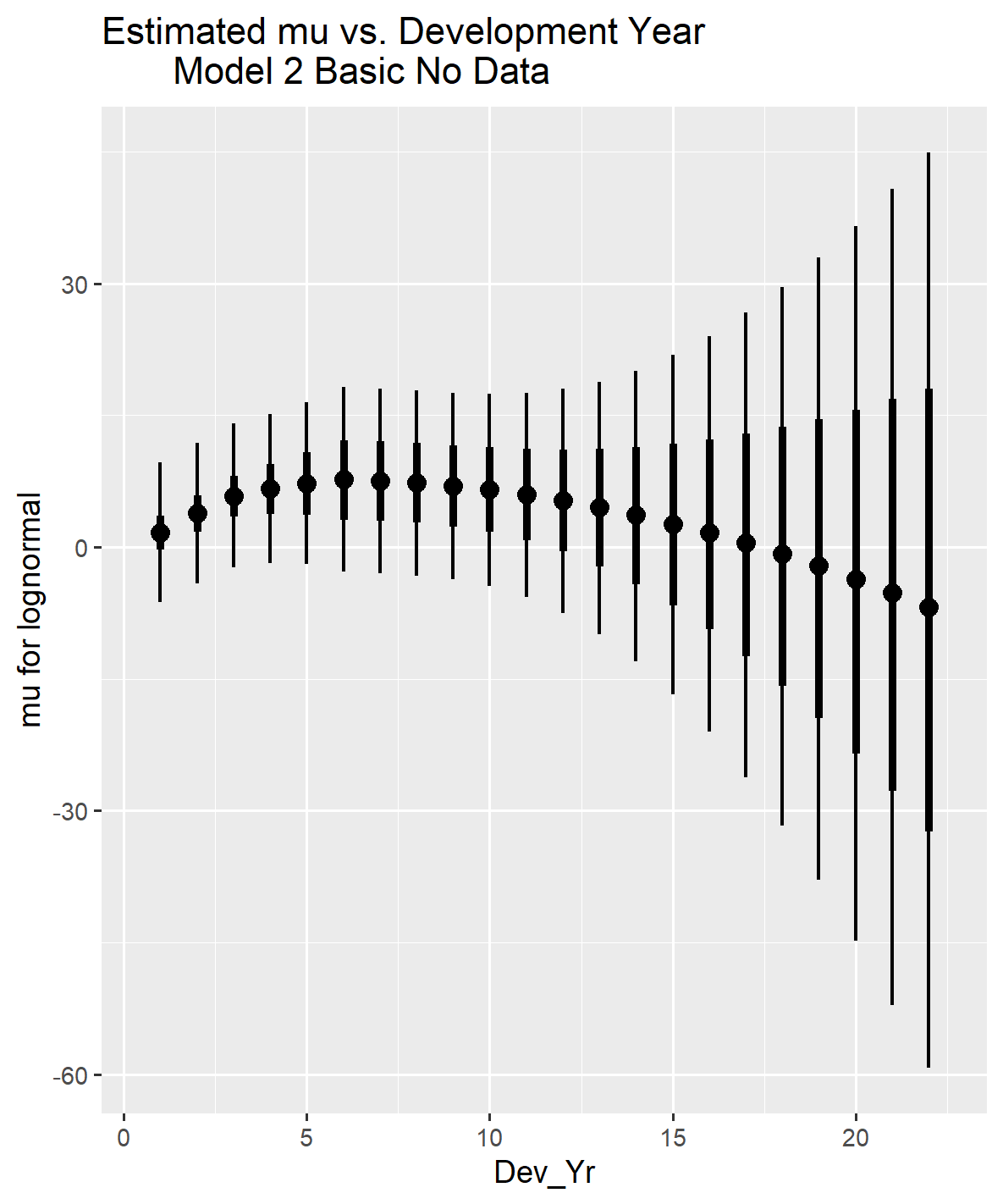
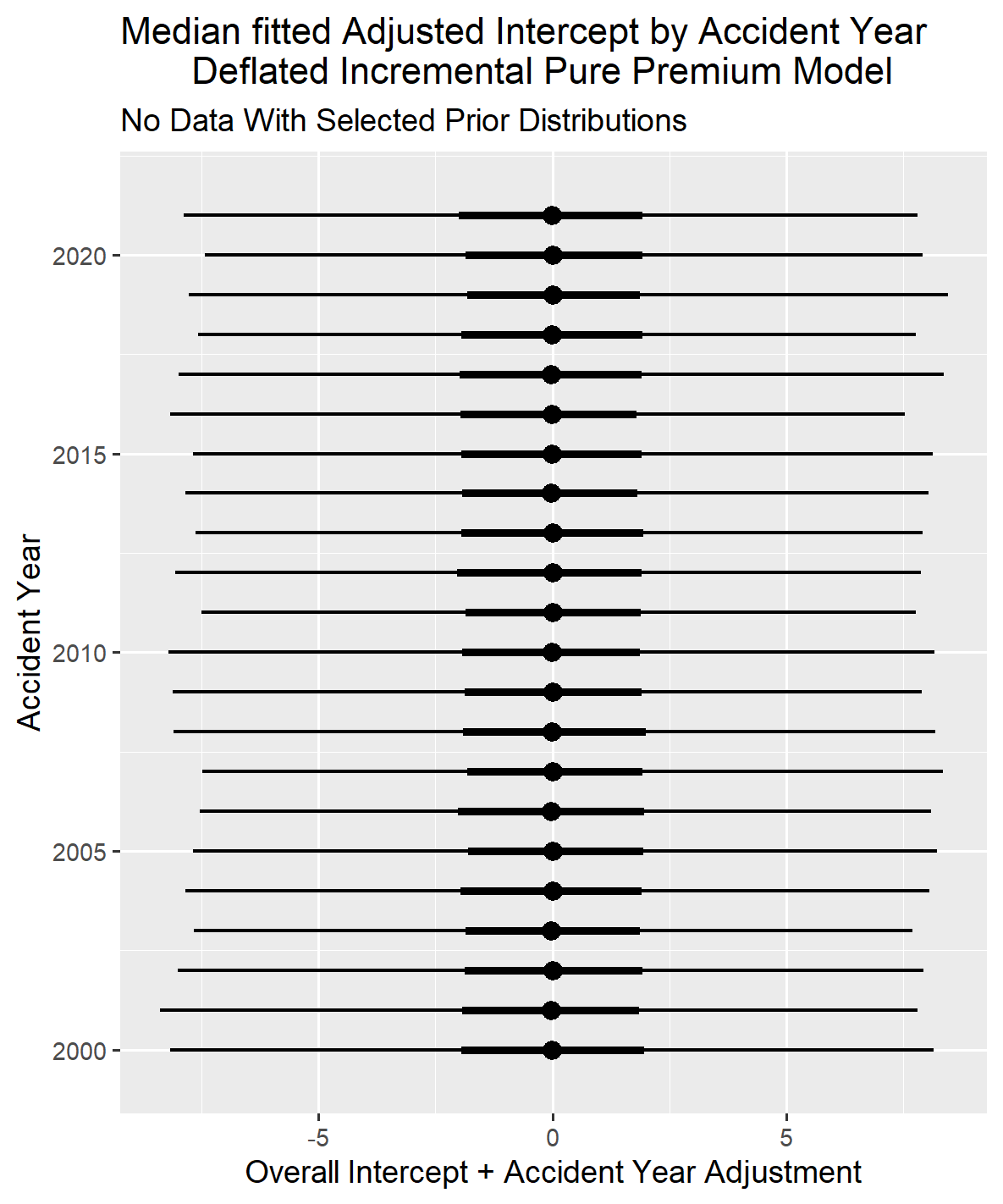
Only the graphs for mu and sigma modeled for the lognormal distribution and the accident year intercepts are shown below. Normally, there would be some comparison of modeled to observed results but given there was no data used in running this model such a comparison is not possible. The graph for mu demonstrates that the pattern implied by the prior distributions follows a roughly parabolic path. In contrast, the graph for sigma indicates it remains relatively constant for the first ten years and then develops upward with some variation around these average patterns. The accident year graph shows that the intercepts are all centered around the same intercept value, zero, which is consistent with the instructions to STAN to gather information to set the relative weight for the group-level variable effect from the data, despite no data being provided.
All of the graphs for the reserve modeling results that are not box plots will show the median result as a dark dot in the center of two sets of lines. The broader inner line represents the 66% confidence interval, and the narrower outer line represents the 95% confidence interval, as drawn from the information in the posterior distribution data set created by the model.



II.3. Case 1 Results with Prior Distribution Selected
There are a few additional preliminary items to address before commenting on the Bayesian MCMC modeling results.
The models used in this paper make the following assumptions:
- A smooth curve describes how the normalized incremental payments (deflated pure premium) develop as an accident year ages, and this pattern is consistent across accident years.
- Beyond the overall inflation effect on loss costs, there is a loss cost trend with an average annual compound effect across all calendar years.
- The insured population’s makeup is similar across accident years, but not necessarily identical and that effect can be measured via an intercept value that varies across accident years. The least squares type approach to credibility weighting (partial pooling) is an appropriate way to reflect the idea that the population as grouped by accident year is similar but not the same across accident years.
Each Case presented will follow the same format:
- Summary exhibits on the fit of the model using selected prior distributions.
- Summary exhibits on the fit of the model using flat priors.
- A comparison of the lognormal parameters mu and sigma on the training data set for the models with and without selected prior distribution parameters.
- A comparison of the forecast lognormal parameters mu and sigma for the future development years within an accident year for the models with and without selected prior distribution parameters.
- A comparison of forecast reserve estimates between the model that used selected prior distributions and the one that did not.
The summary exhibits on the fit of the model will be limited in scope relative to what one would typically review when fitting a model. The intent is to provide sufficient information for the reader to evaluate if the model provides a reasonable fit to the observations before moving on to the primary focus of the paper: comparing the forecast variability with and without prior distributions as the volume of information in the loss triangles changes.
The summary for Case 1 shows that all population variables likely have a non-zero effect, as their 95% confidence intervals do not include zero. The graph for observed vs. modeled indicate that the model provides a reasonable fit to the data since the modeled results tend to follow the observed data.
Regarding the prior distribution versus the posterior distribution, we can look at the results for Dev_Yr_6_Cap as an example. The prior distribution specified that the coefficient for this variable follows a Normal Distribution with a mean of 1.5 and a standard deviation of 0.2. The summarized posterior distribution shows a mean of 1.657 and a standard deviation of 0.069. The data set indications shifted the prior distribution mean, and the standard deviation around that parameter estimate became smaller which is a typical result.
In the “Prior_Distribution” column below, you will see that the Normal distribution was selected in all cases but one for the population variables. Sometimes, using the Student distribution can be an effective approach to preventing outliers from weighing too heavily on the fit for a coefficient.

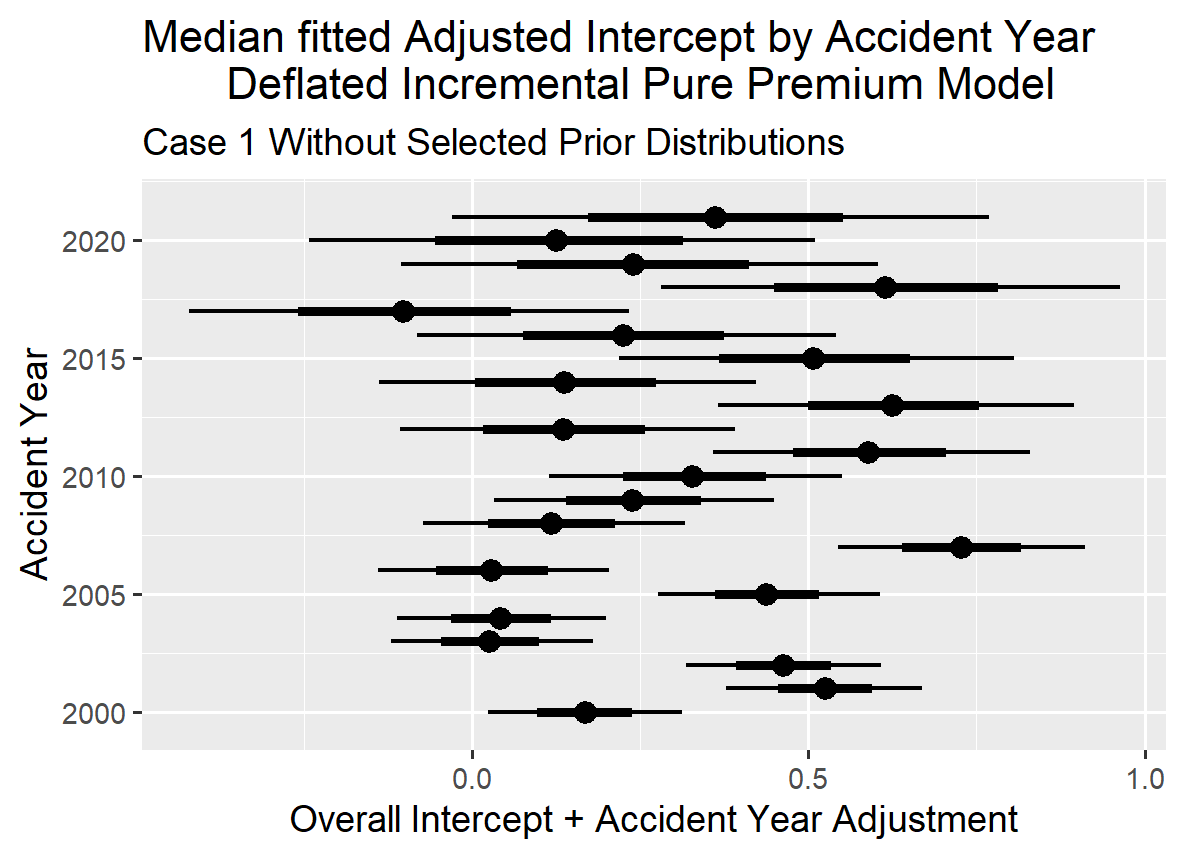
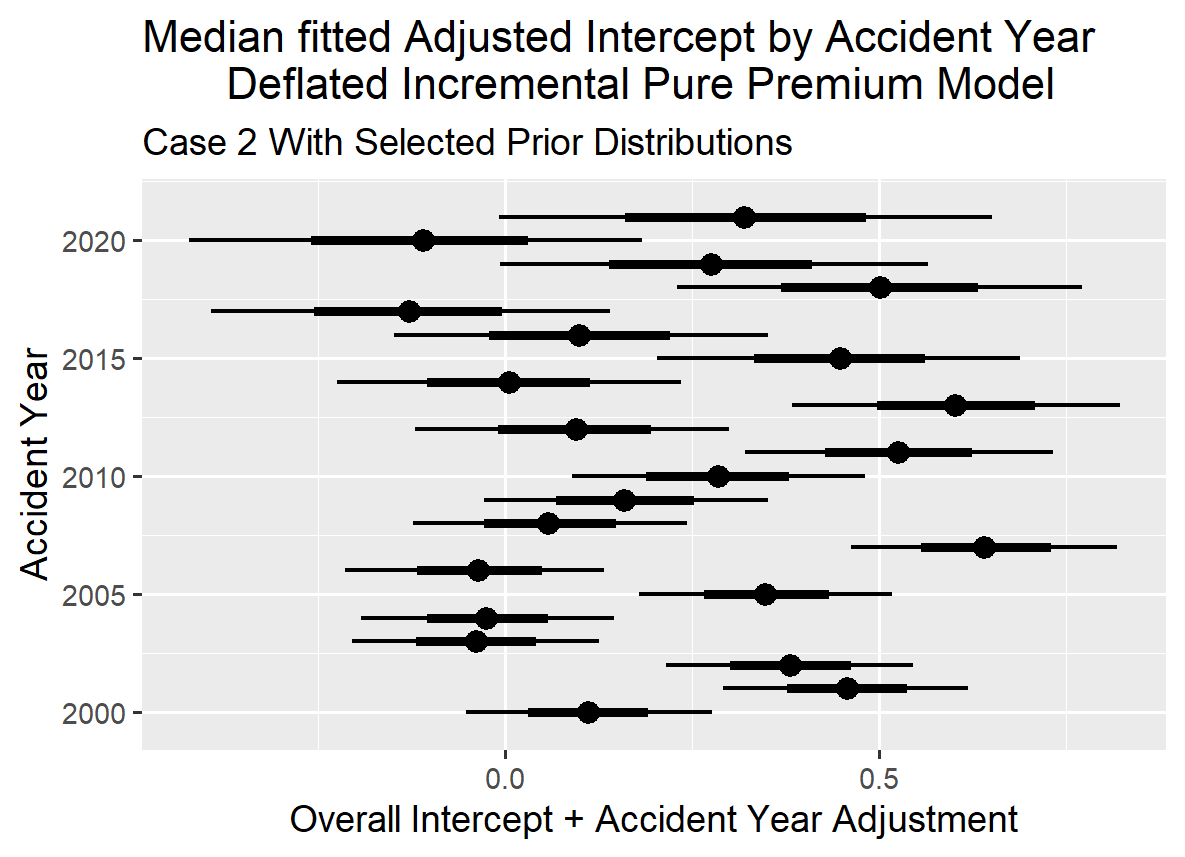
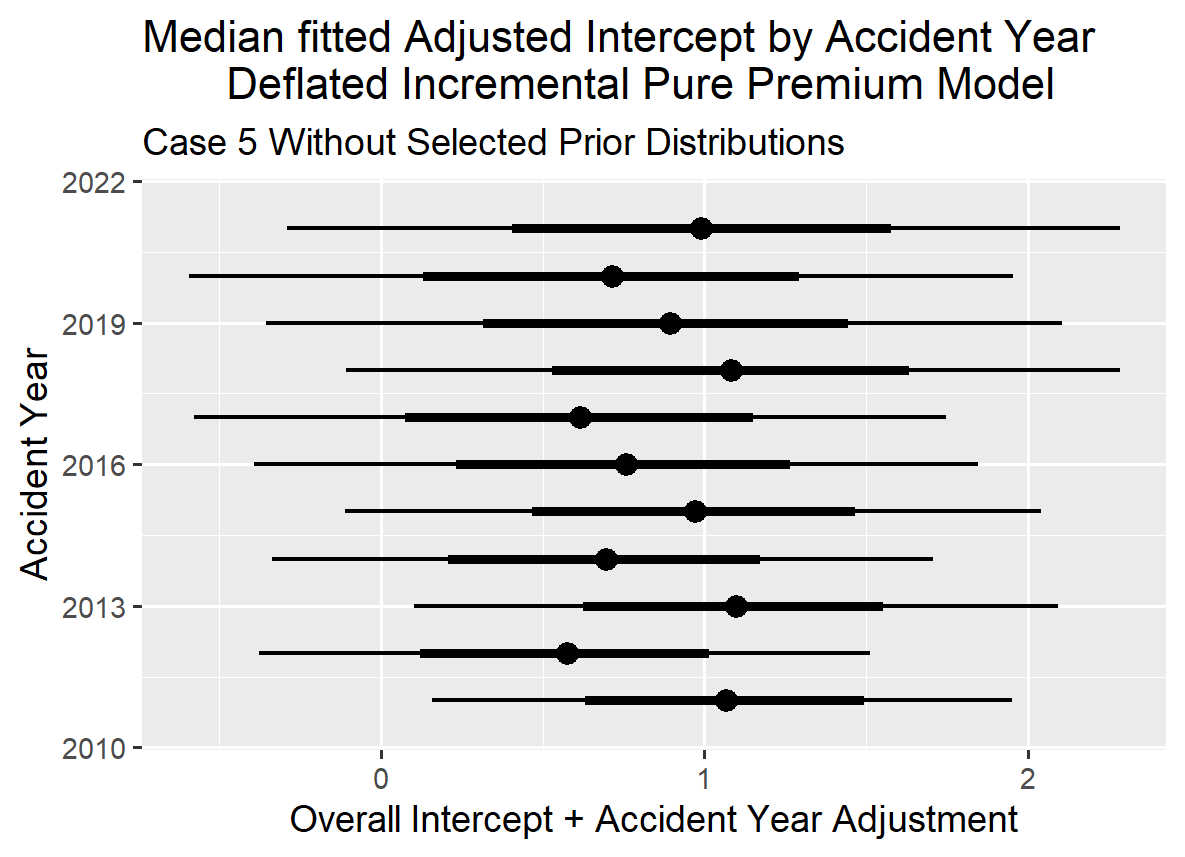
The graph below for the Adjusted Intercept shows the predicted intercept adjusted by accident year with the adjustment calculated using partial pooling. The mean estimate is 0.244 for the Intercept and one can see there is some variation in the Intercept value across the accident years. The least squares approach allows one to recognize that the intercepts are a little different by accident year without running into the multi-collinearity problem created by trying to model in three dimensions (accident year, development year and calendar year) on a two-dimensional data set that one can experience when modeling in a GLM environment.

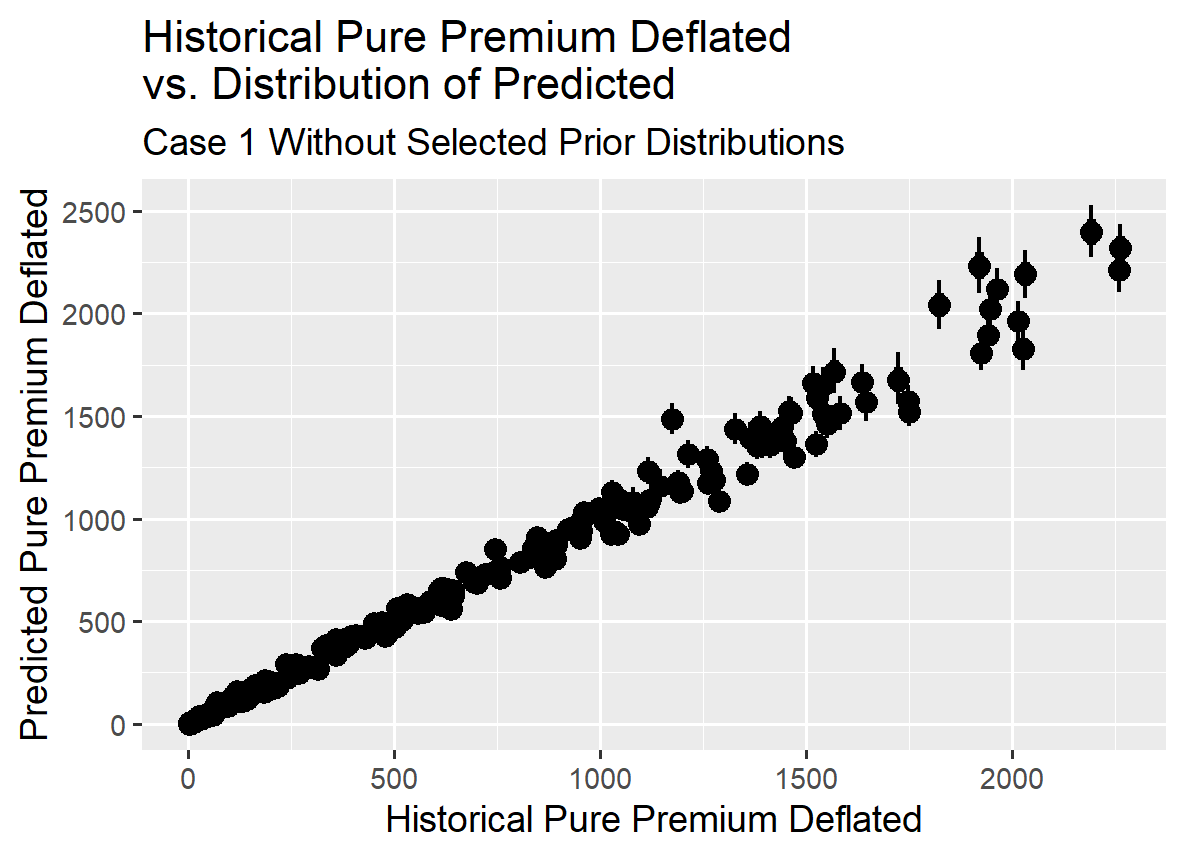
The graph below indicates that the modeled results track reasonably well with the observed deflated pure premium.

II.4. Case 1 With Flat Prior Distribution
The results below were created using the same model as above for Case 1 data but with the priors set to the default value of a flat prior for the real number line. Electing to use the default flat prior means that the prior distribution column will show blanks (without a prior distribution selection) for the rows for the regression equation coefficients in the exhibits showing the prior distributions. In a sense, one cannot avoid selecting a prior distribution for each coefficient but selecting a flat prior means electing to use a prior distribution without specifying the specific distribution and the parameters for that distribution.
The intent is to allow the reader to see that with a large data set (one with lots of information) the Bayesian MCMC routine still produces sensible results without the benefit of selecting a plausible set of prior distribution parameters. The parameter estimates shown in the summary exhibit differ from those from the model, which included selected prior distributions. Although the standard deviation around these estimates can be slightly larger, the residual patterns still indicate the model produces usable results. Additionally, the 95% confidence intervals suggest that the coefficients are reliably non-zero.

The graph below shows the effect of using partial pooling on the intercept by accident year. This illustrates that one can use partial pooling (least squares weighting) in a Bayesian MCMC model even if one does not elect to select the prior distribution parameters for the population variables. Please note that the more recent accident years tend to have larger confidence intervals below, since they have fewer development year observation which translates to more uncertainty in the adjustment forecast.

The graph below demonstrates that, even without selecting prior distribution parameters for the population variables, the triangle data set contains sufficient information to fit the observations reasonably well given the volume of information in Case 1.

II.5. Case I Compare Reserve Distribution Estimate With and Without Selected Priors
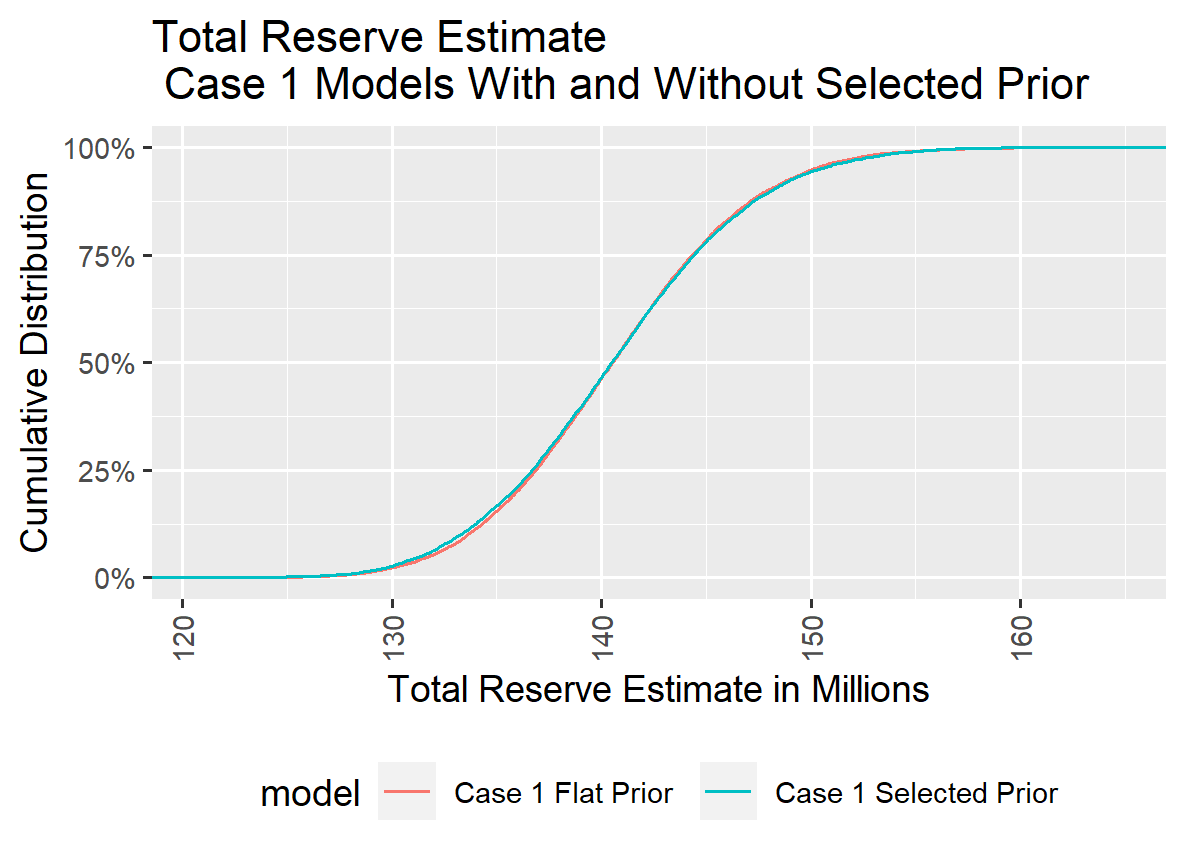
The end result for the total indicated reserve distribution indicates that for Case 1 there is no appreciable difference in the estimated reserve distribution between the model with selected prior distributions and the model that took the default (flat) prior distributions.
It appears that with 1,000 reported claims, the loss triangle contains enough information to outweigh the influence of the prior distribution parameters (close to 100 % credibility).


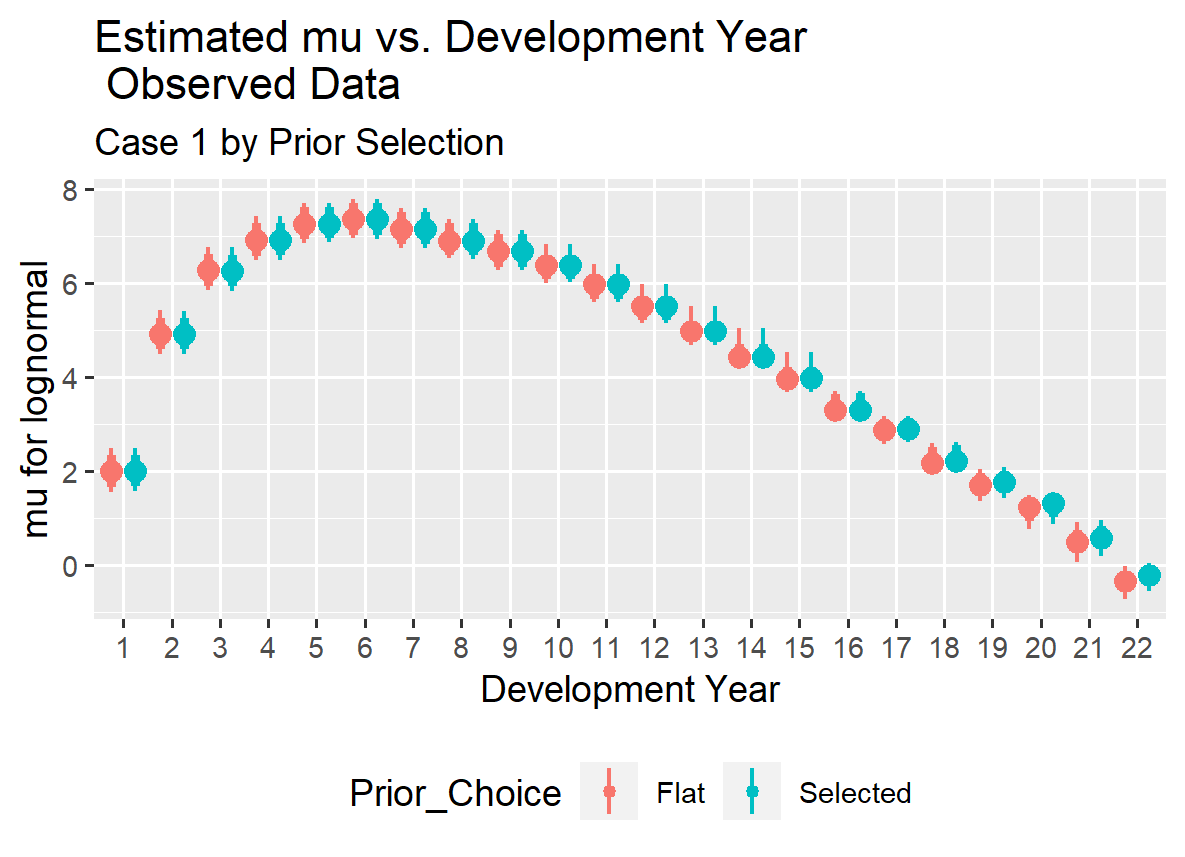
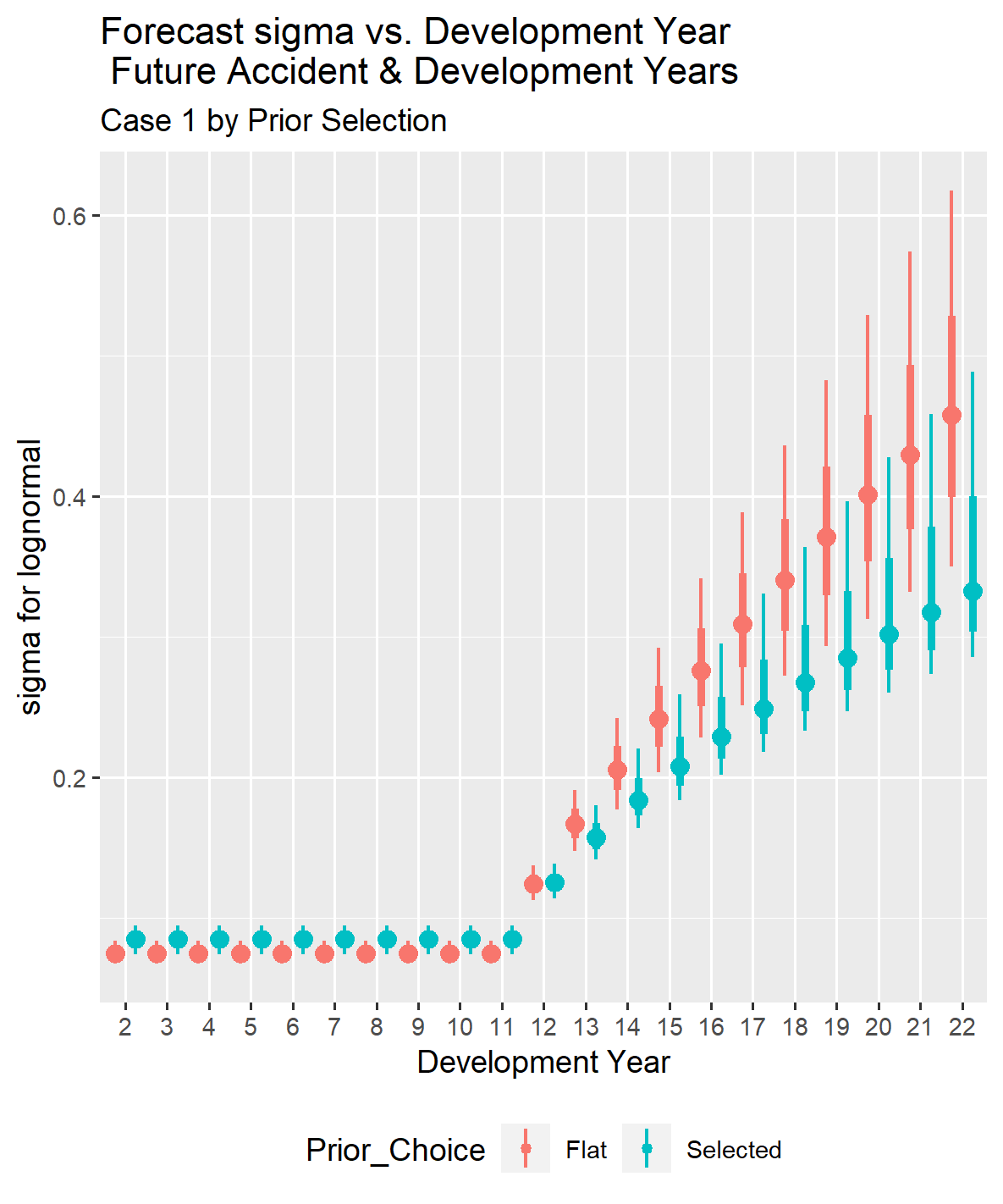
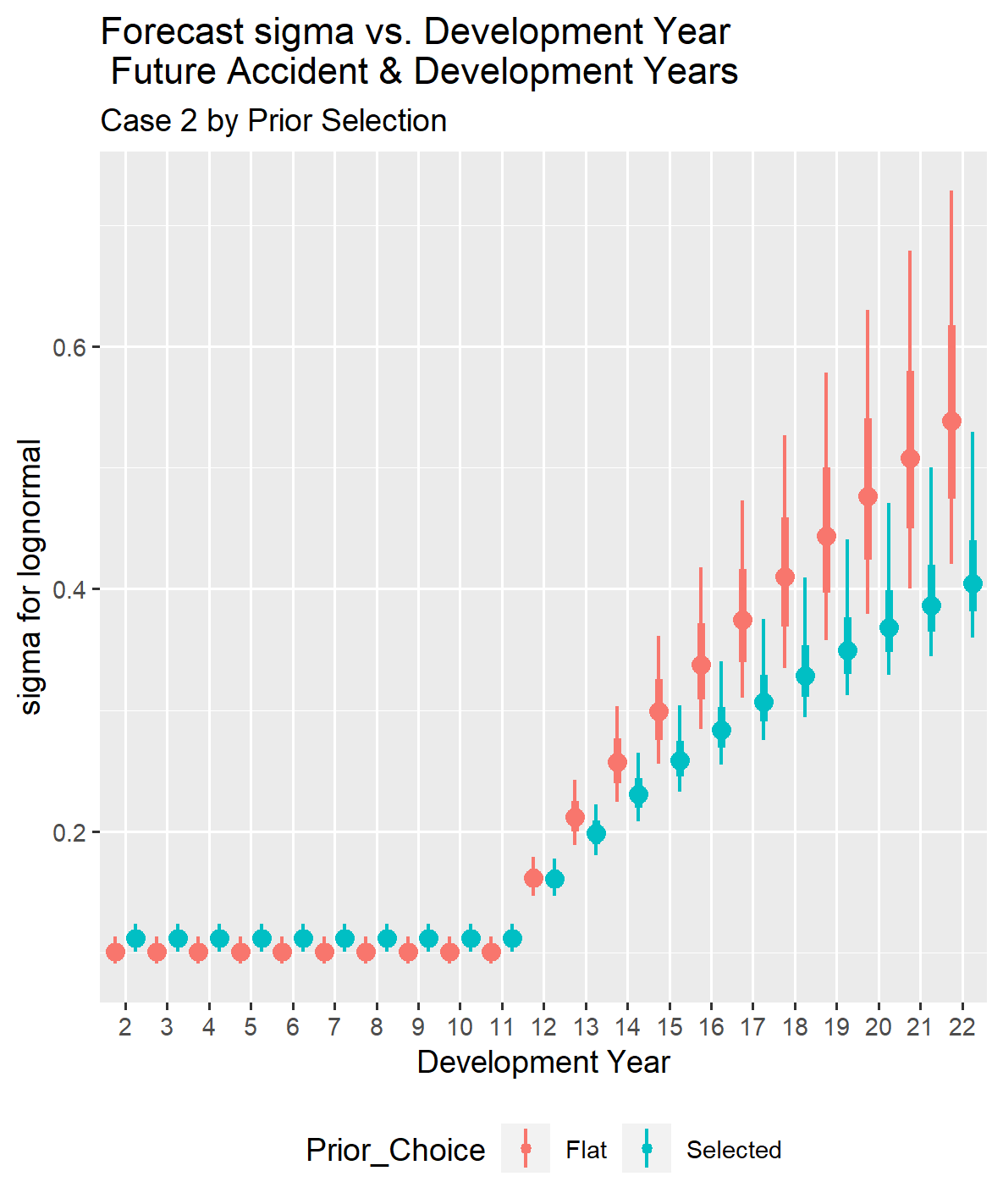
Given that there is less information for older development ages in the observed loss triangle, there is some difference in the estimates for sigma in the tail.
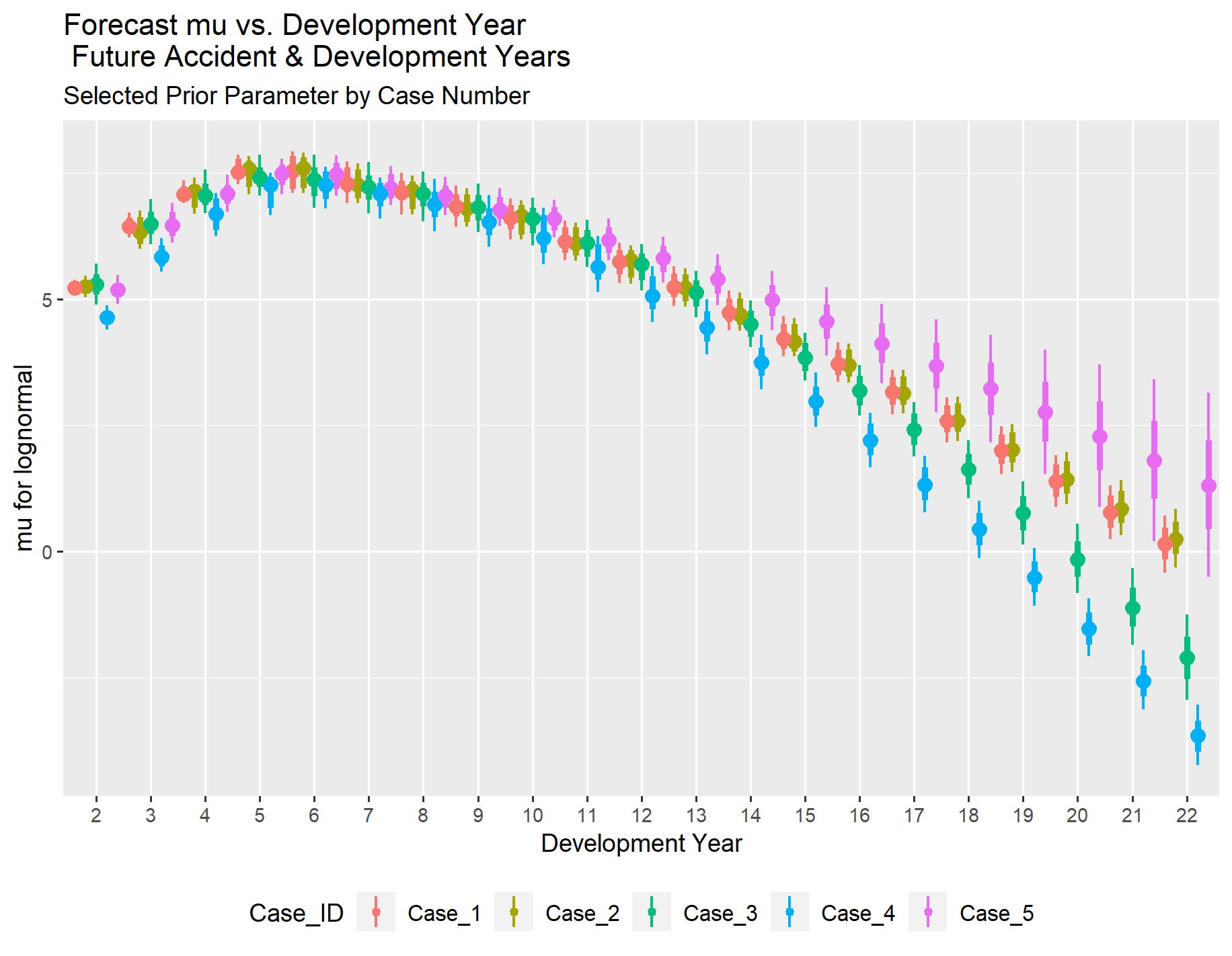
We can also examine the mu and sigma values for the future time periods in the forecast. It is important to note that when the posterior distribution for the forecast loss payments is created, the routines will invert the lognormal distribution using those parameters rather than simply calculating the expected values, as is done for the time periods with observations. In other words, the loss reserve forecasts (the sum of the future incremental loss payments) will account for both process variance and parameter uncertainty.
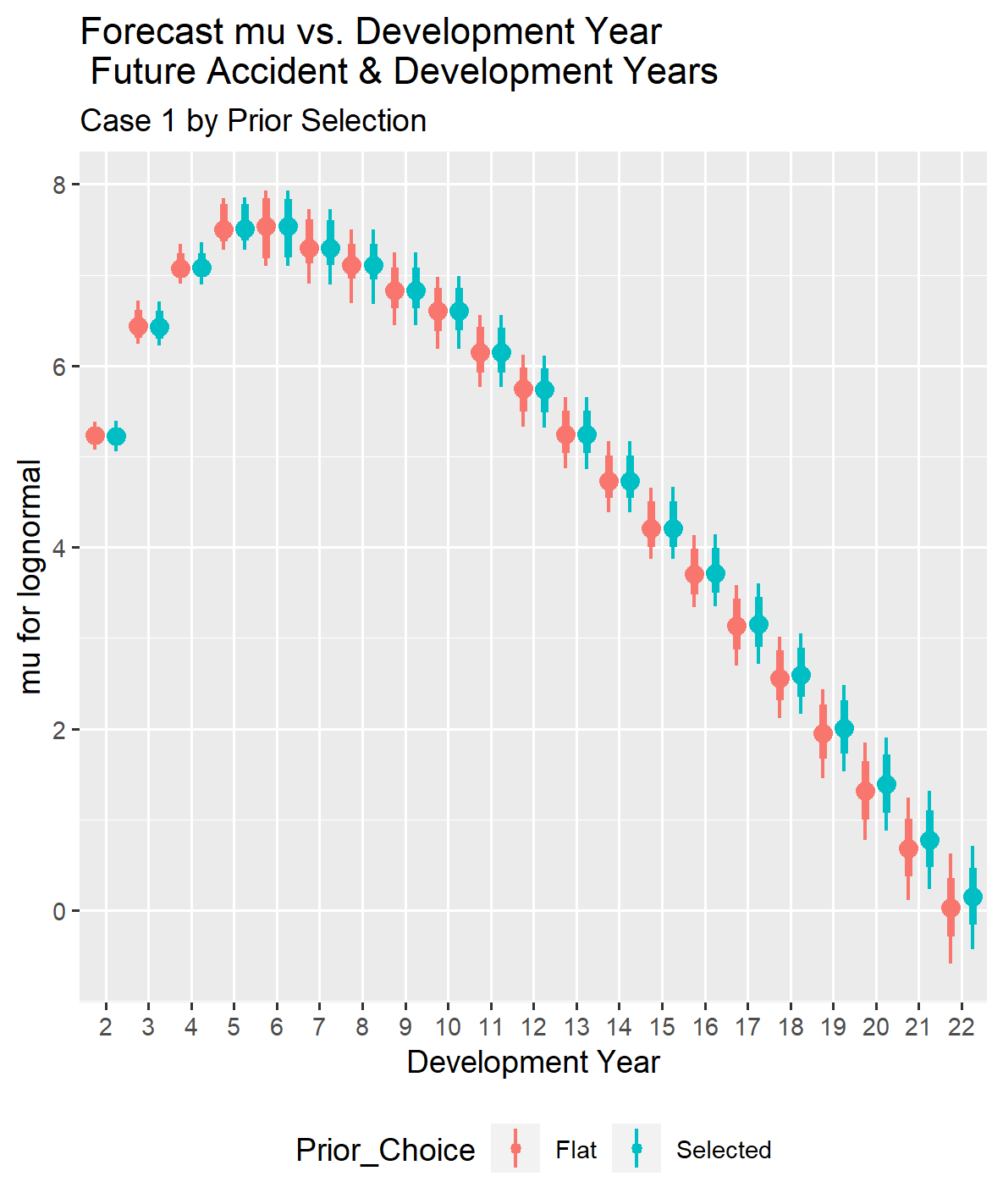
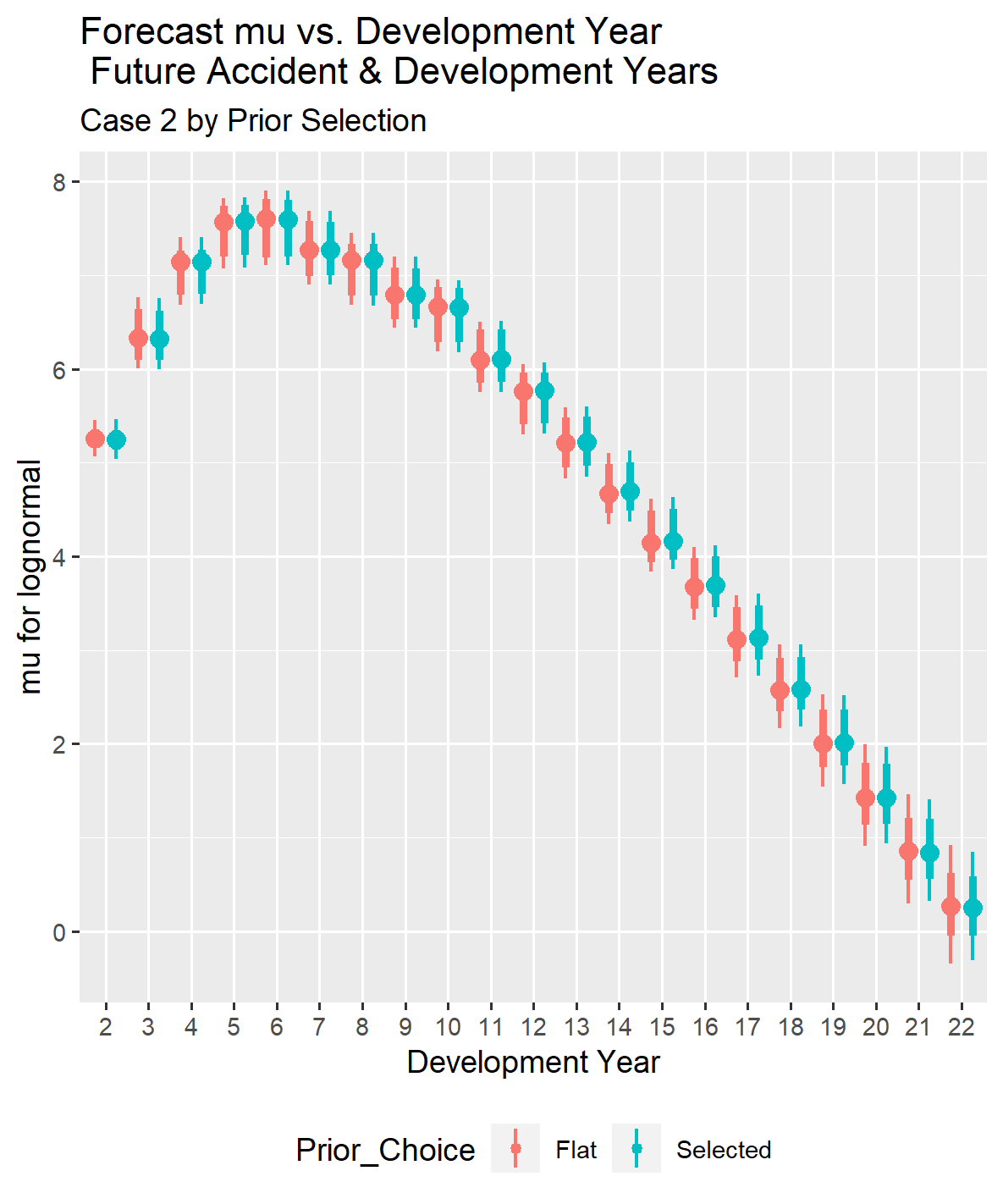
If you look at the two graphs below, you can see that the development year starts at two rather than one because all of the future development years for the accident years in the forecast are greater than one.


Although the parameters differ slightly with and without selected priors, the total reserve distributions with and without selected prior distribution parameters are close. The estimated reserve distributions are shown both separately and overlaid for comparison, as they diverge noticeably in later cases.
The accident year comparison of forecast loss reserves for Case 1 shows that the reserve forecast distributions are virtually identical with and without selecting the prior parameters. However, this will change as the information in the loss triangle decreases.


The total reserve forecasts with and without selected prior distribution parameters are shown separately, even though the overlaid forecasts appear virtually the same. This approach maintains a consistent presentation since at some point, the forecasts without selected prior distribution parameters will exhibit such high tail values that overlaying the two forecast loss distributions would not be useful.


III. Case 2 Modeling Results
Case 2 has 22 accident years (2000 through 2021) with a uniform reported claim count of 500 reported claims at 12 months for each accident year and a maximum of 22 years of development time.
The reason for presenting modeling results for Case 2 is to demonstrate how systematically reducing the information in a loss triangle affects the forecast loss reserve distribution.
III.1. Case 2 Results With Prior Distribution Selected
As the exposure count dropped from 1,000 to 500 reported claims per accident year, the amount of information in the triangle decreased, leading to an increase in the standard error around the parameter estimates. This occurred even though the prior distributions remained the same as for those used in Case 1. The mean parameter estimates also changed slightly, but the 95% confidence intervals still indicate that the effects are non-zero.

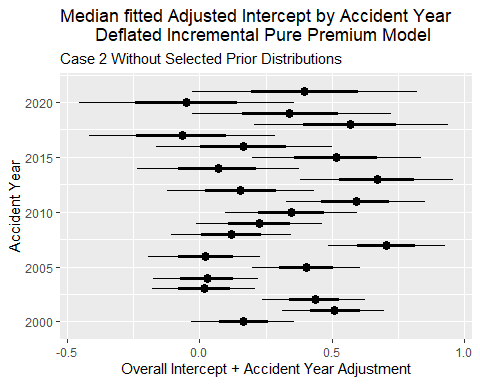
The effect of partial pooling by accident year for the intercept is shown on the graph below.

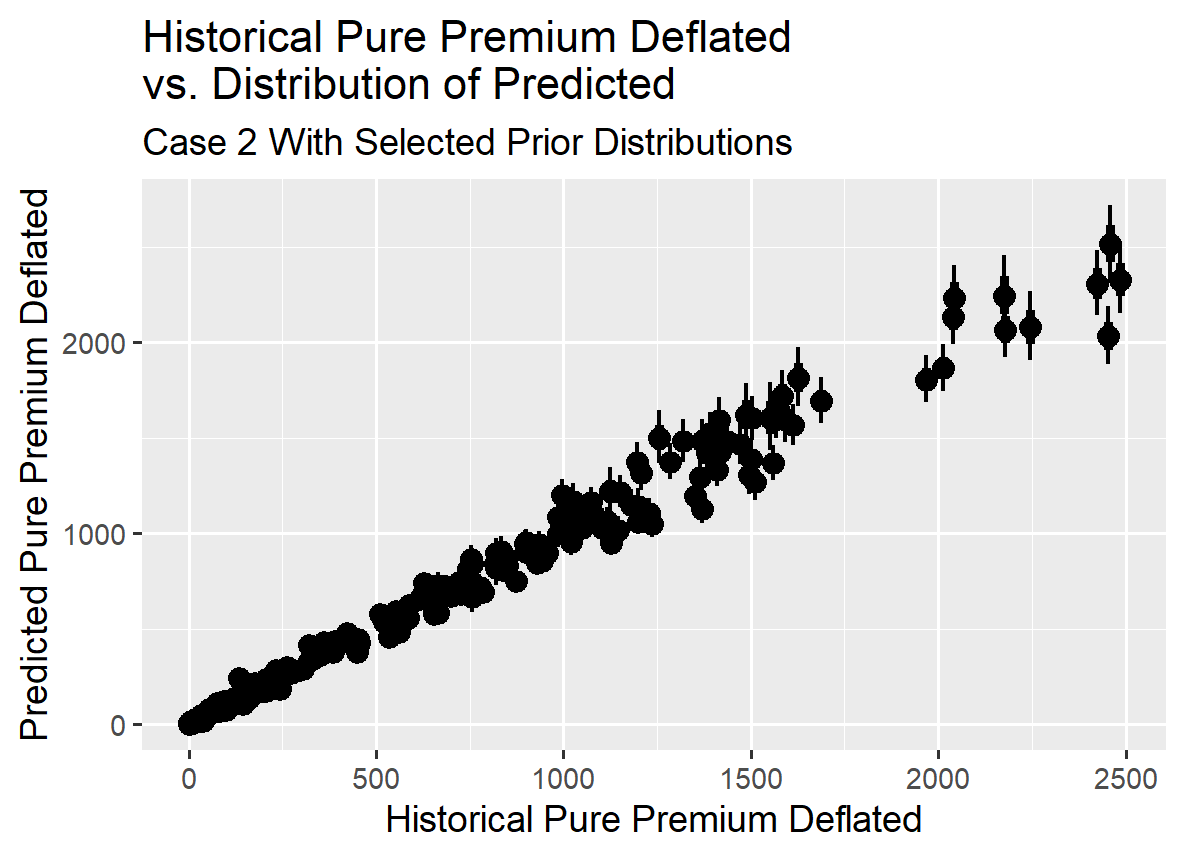
The graphs indicate that the model provides a usable fit to the loss triangles. The predicted vs. observed pure premium graph shows that the model results track reasonably well with the observed values.

III.2. Case 2 With Flat Prior Distribution
The results are similar to those observed in Case 1. Although the standard errors around the parameters are larger when using the flat priors (prior distributions without selected distribution parameters), the model still produces usable results. The summary of results indicate that the parameters can be safely assumed to be non-zero since the 95% confidence interval does not include zero. Additionally, the graphs indicate the model provides a reliable fit to the observed loss triangle.

The graph below shows the effect of partial pooling on the intercept for the equation for the lognormal parameter mu.

The graph showing the observed deflated pure premium compared to the posterior distribution estimates is shown below and indicates that using a flat prior still produces reasonable results.

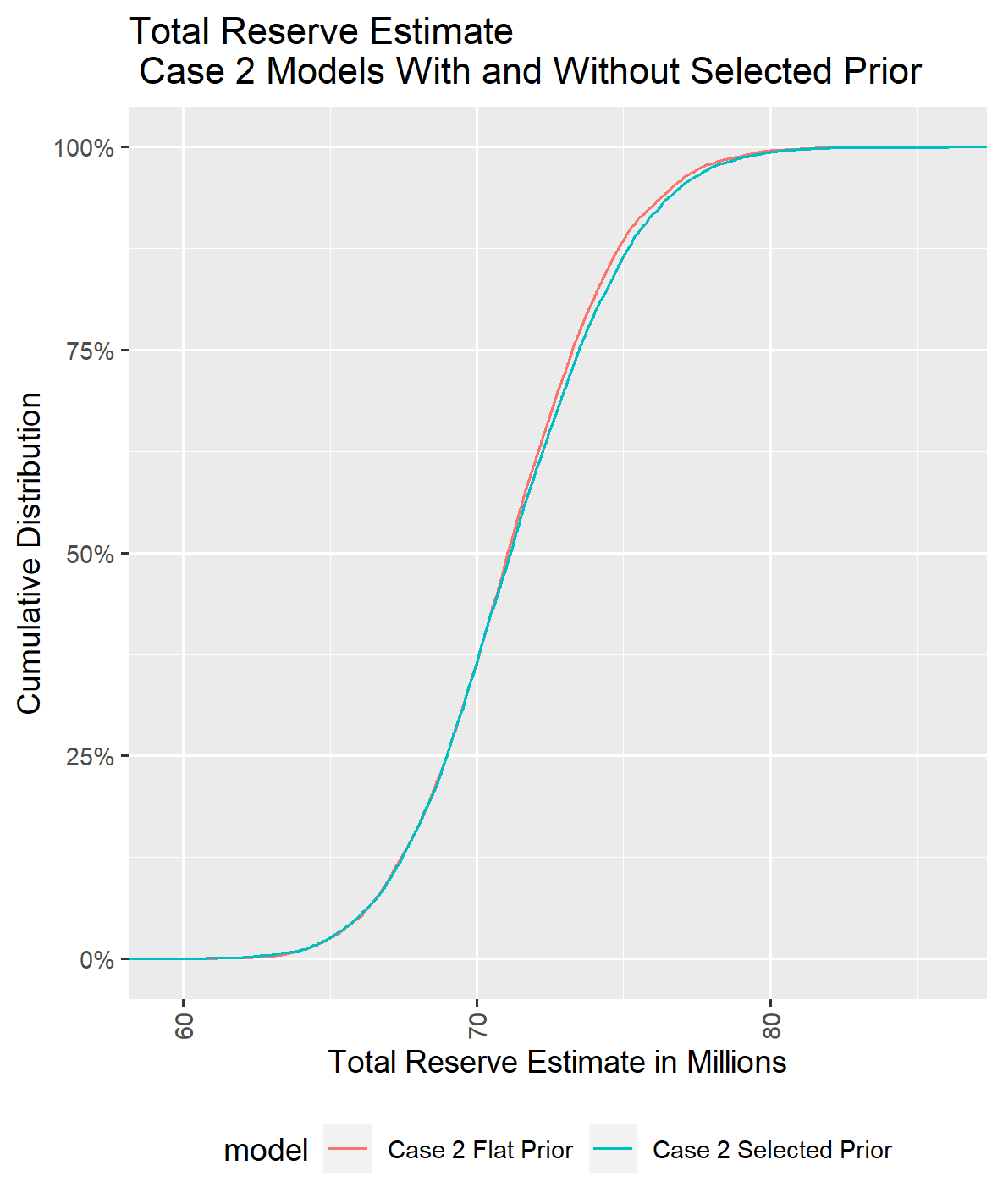
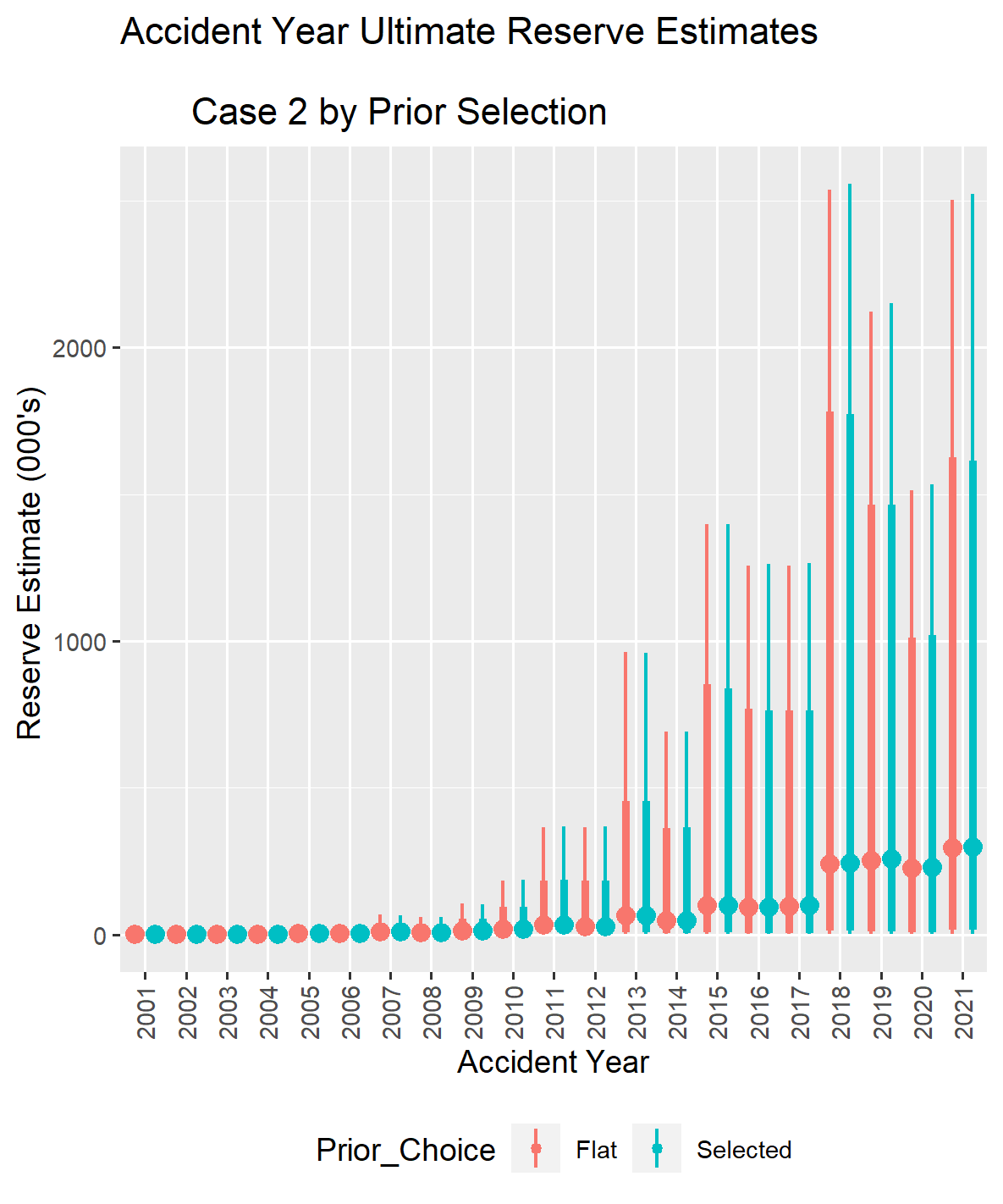
III.3. Case 2 Compare Reserve Distribution Estimate With and Without Selected Priors
The results below were generated using the same process for Case 2 as for Case 1. The results indicate that reducing the number of exposures from 1,000 to 500 did not significantly impact the comparison between using a selected a set of prior distribution parameters and using a flat set of prior distributions.
There is still sufficient information in the loss triangles used to fit the model effectively, outweighing the influence of the selected prior distributions. While using a chosen set of prior distribution parameters produced different posterior estimates for the coefficients, the net difference is negligible. However, there is a slight difference in the total reserve forecast when overlaying the curve from the model with selected prior distribution parameters on the curve from the model with flat priors.
It is important to note that this result is specific to this set of examples. In practice, you would need to experiment with a data set tailored to match observations within your company to evaluate the effect of reducing the exposure count.








IV. Case 3 Modeling Results
Case 3 has 22 accident years (2000 through 2021) with a uniform reported claim count of 100 reported claims at 12 months for each accident year and a maximum of 22 years of development time.
The purpose of presenting the modeling results for Case 3 is to further illustrate how reducing the amount of information in a loss triangle impacts the effectiveness of using a prior distribution in a Bayesian MCMC model.
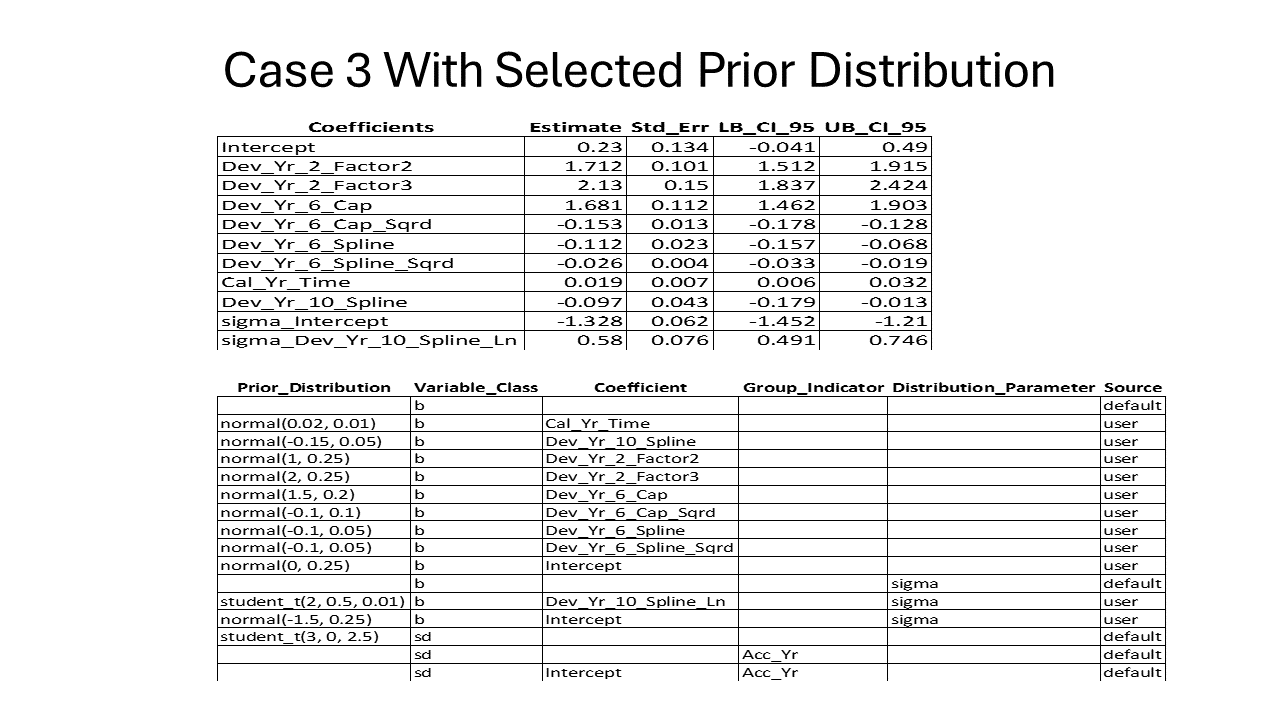
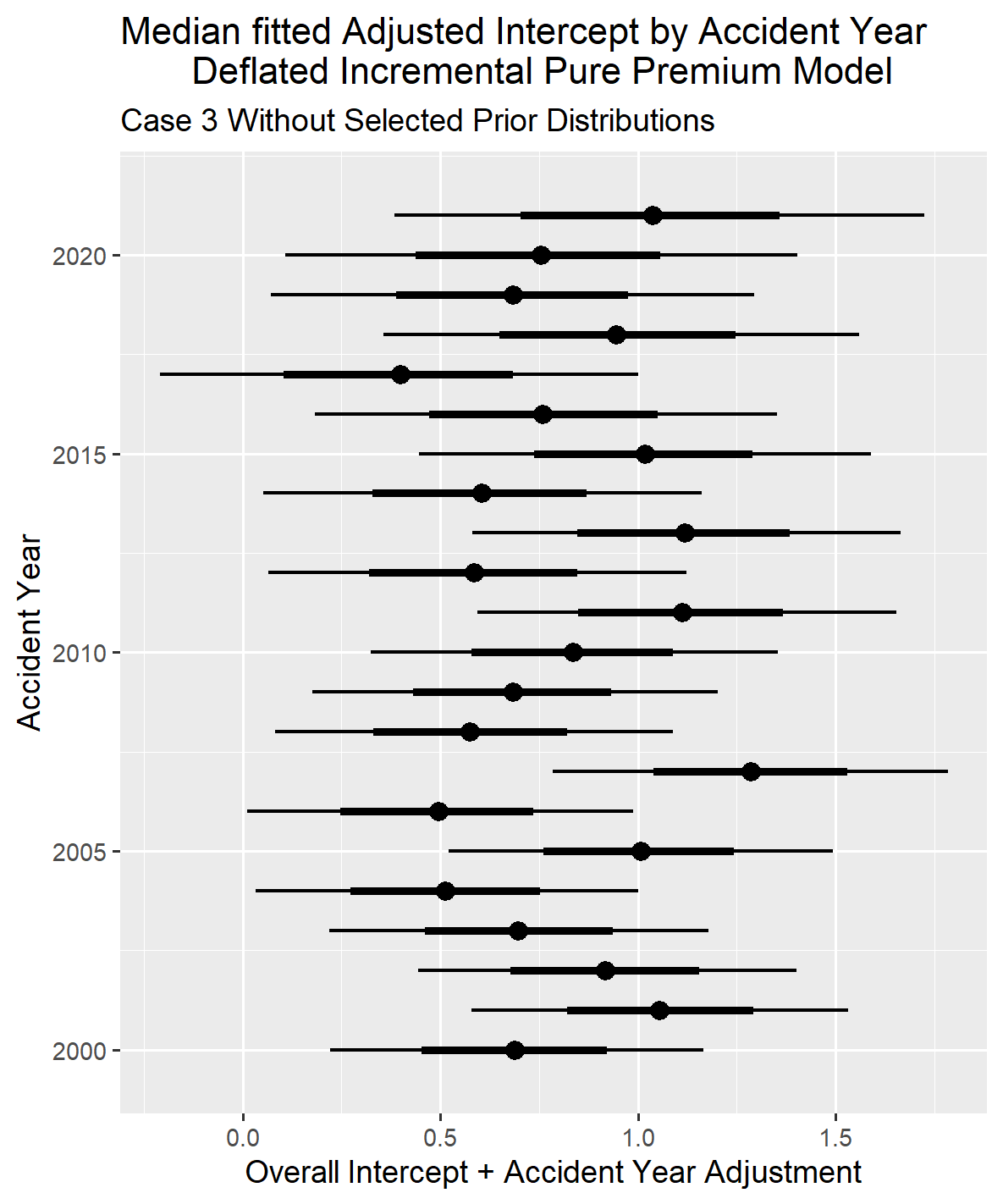
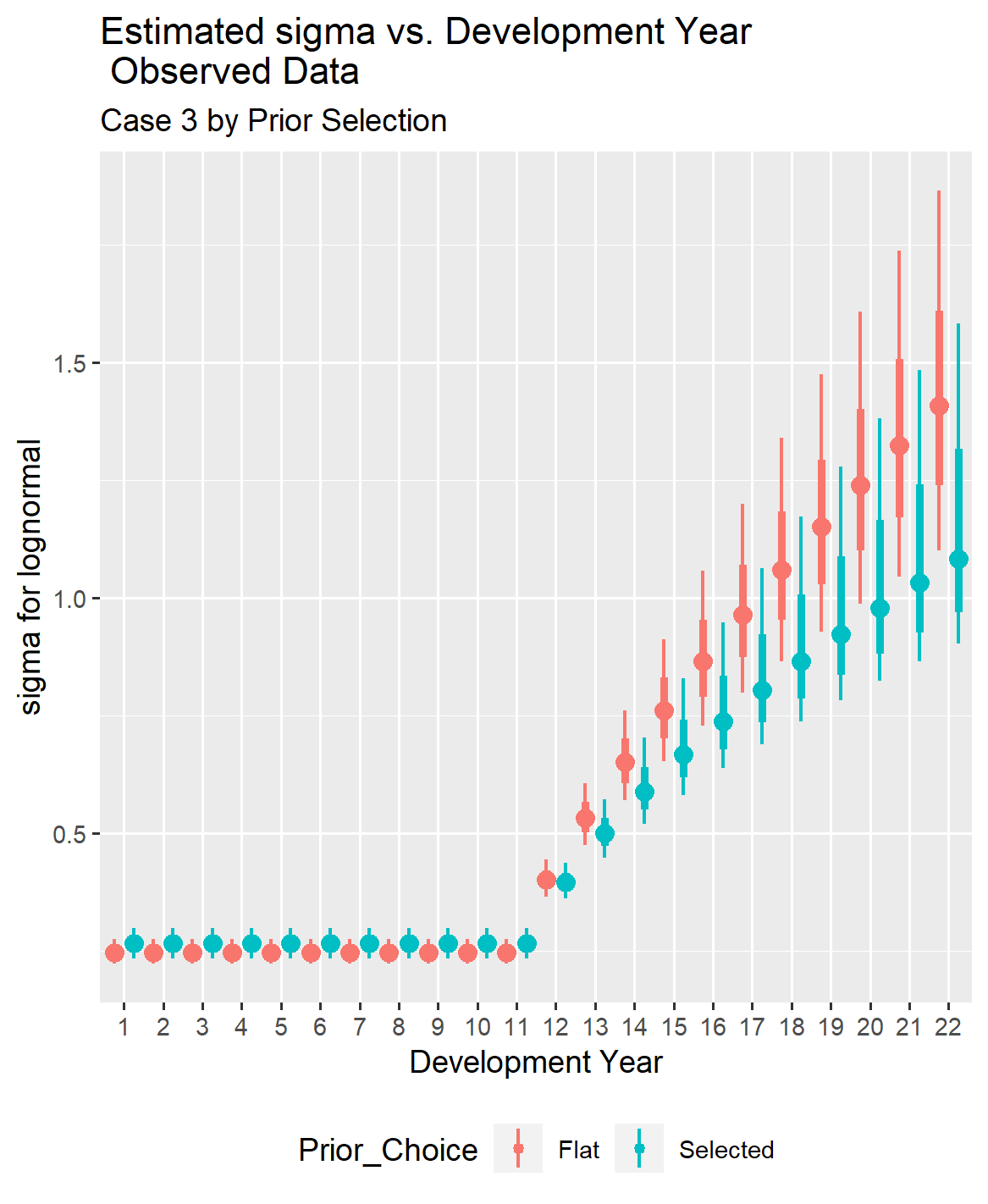
IV.1. Case 3 Results with Prior Distribution Selected
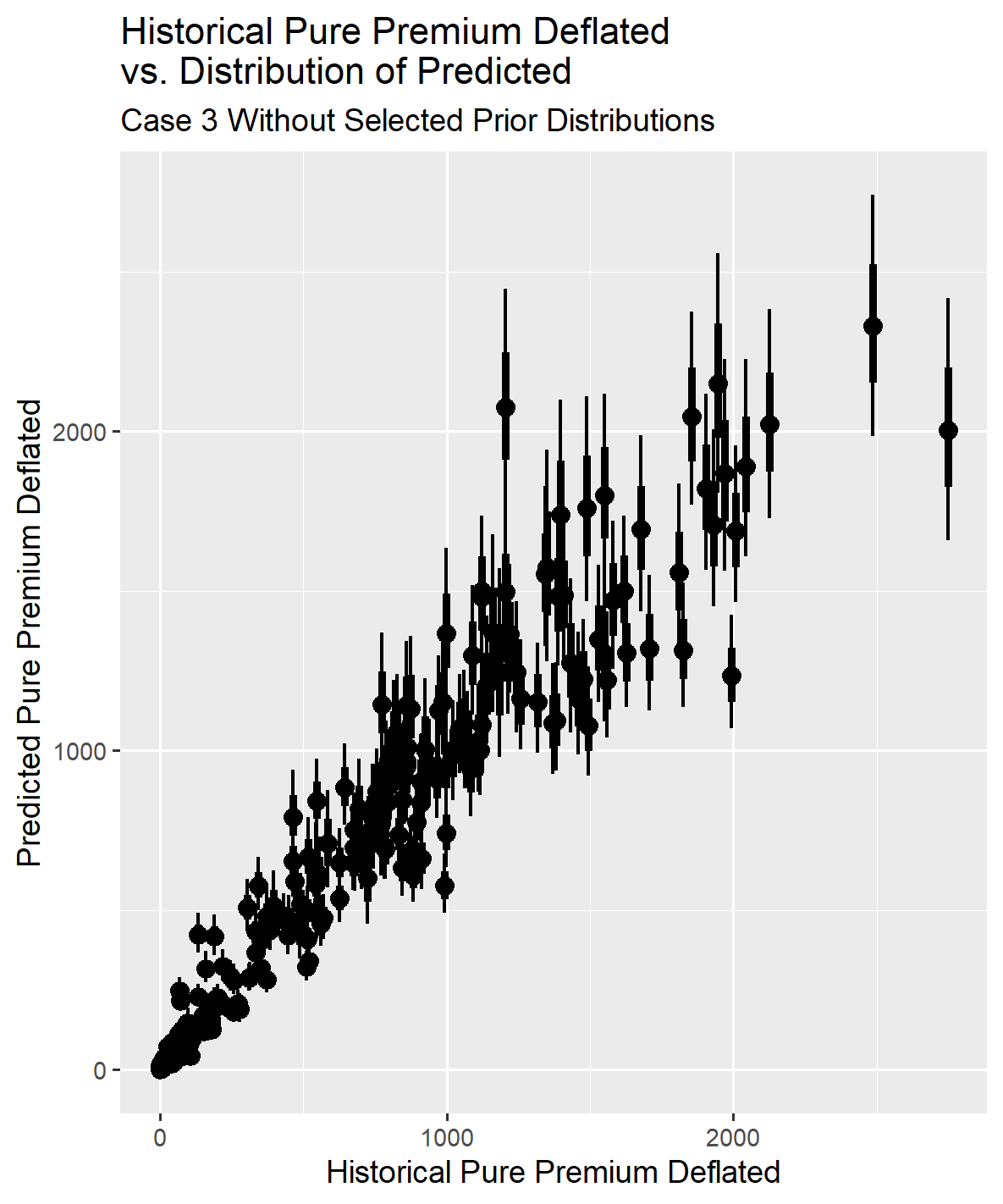
The results for Case 3 will be produced in the same manner as for the first two cases. A similar progression is observed when reducing the exposure base from 500 reported claims to 100, as seen when reducing from 1,000 to 500 reported claims. The standard error around the estimated parameters increased due to the reduced information in the loss triangle, but the actual-to-predicted graph indicates that the model results are still usable.
When moving from 500 to100 claims, the coefficients for development years beyond six years became unstable. That lead to altering the prior distributions for the coefficients used to predict development beyond six years to put in tighter guard rails around the estimation process.
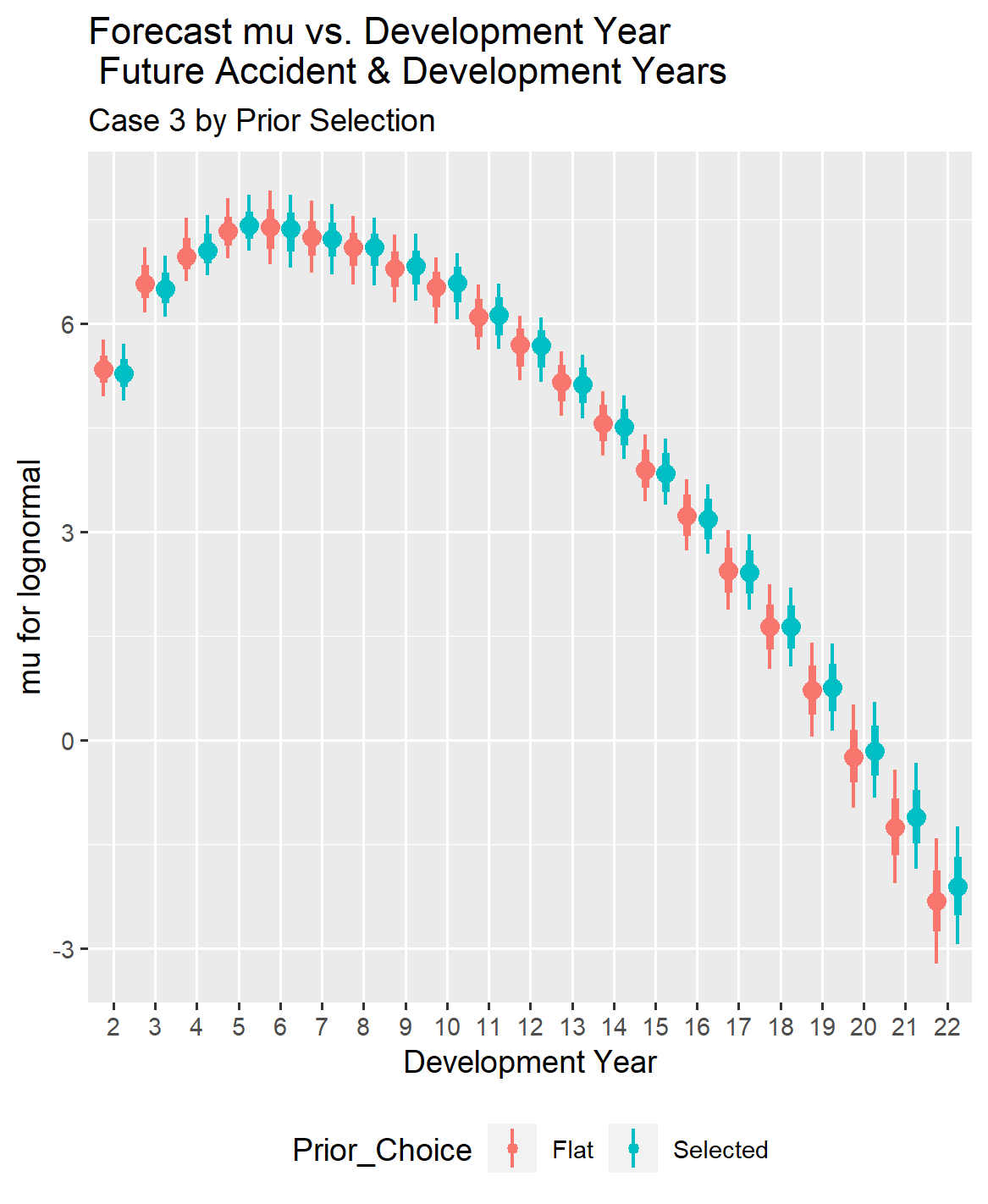
Additionally, comparing the length of the confidence intervals on the observed versus predicted graphs for Cases 1 and 2 reveals that the confidence intervals tend to become larger as the amount of information in the loss triangle decreases, even with tightening the standard deviation for selected coefficients. Later in the paper, comparisons between the cases will directly demonstrate how reducing information in the loss triangle affects the confidence intervals for mu and sigma.



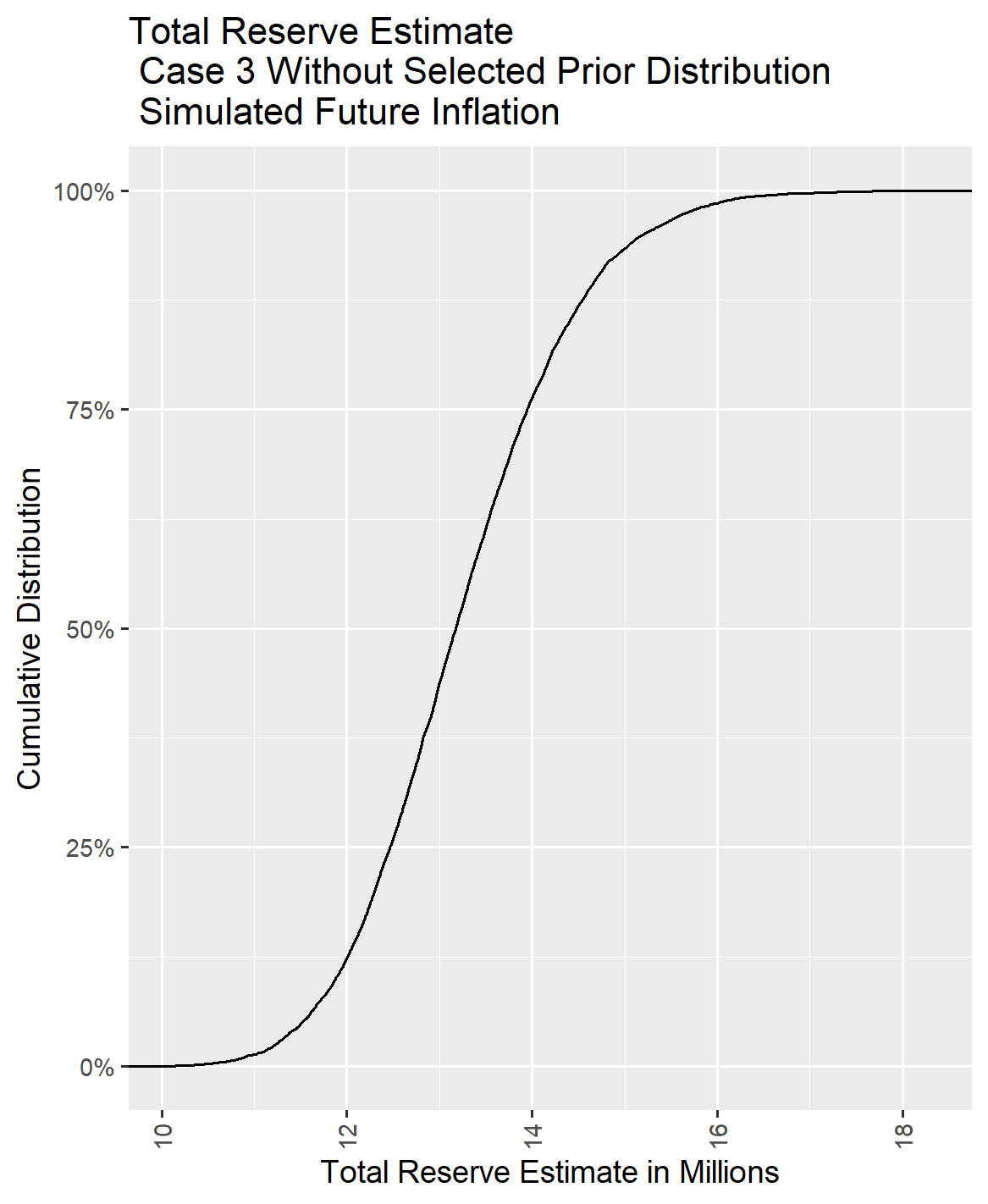
IV.2. Case 3 With Flat Prior
Dropping from 500 to 100 reported claims starts to affect the reliability of the coefficients when a flat prior distribution is used as the compliment of credibility. The variable Dev_Yr_10_Spline was dropped, since its 95% confidence interval included zero. Dropping Dev_Yr_10_Spline tended to stabilize the coefficients for other variables. One can see that the coefficient for additional loss cost trend factor variable, Cal_Yr_Time, now has a confidence interval that border line includes zero, which was not the case for the model for this case that included selected prior distribution parameters.
If you look at the graph comparing the observed deflated pure premium to the predicted, the length of the confidence interval bars has also started to grow as well. Using the model without some form of guard rails is becoming questionable.



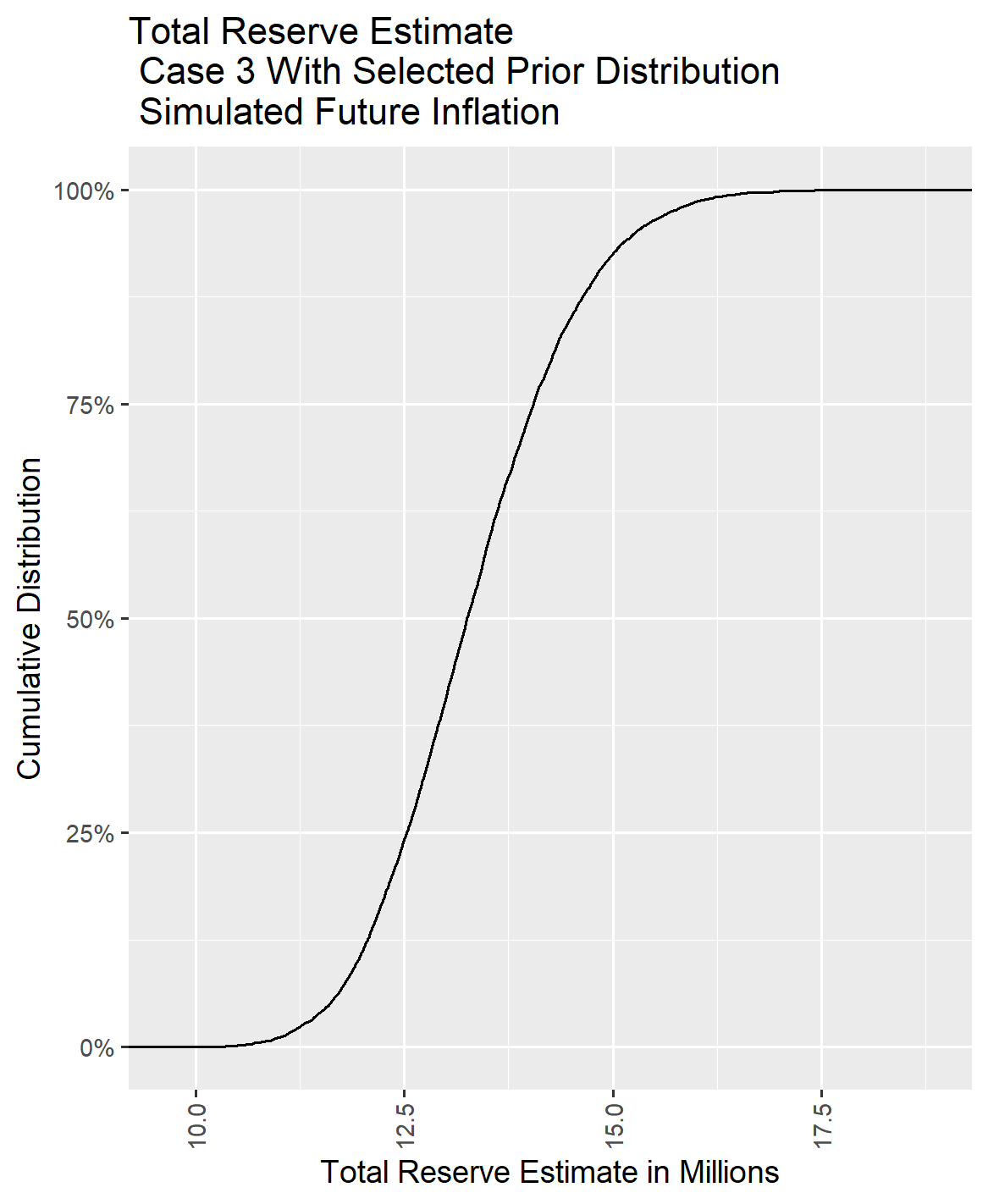
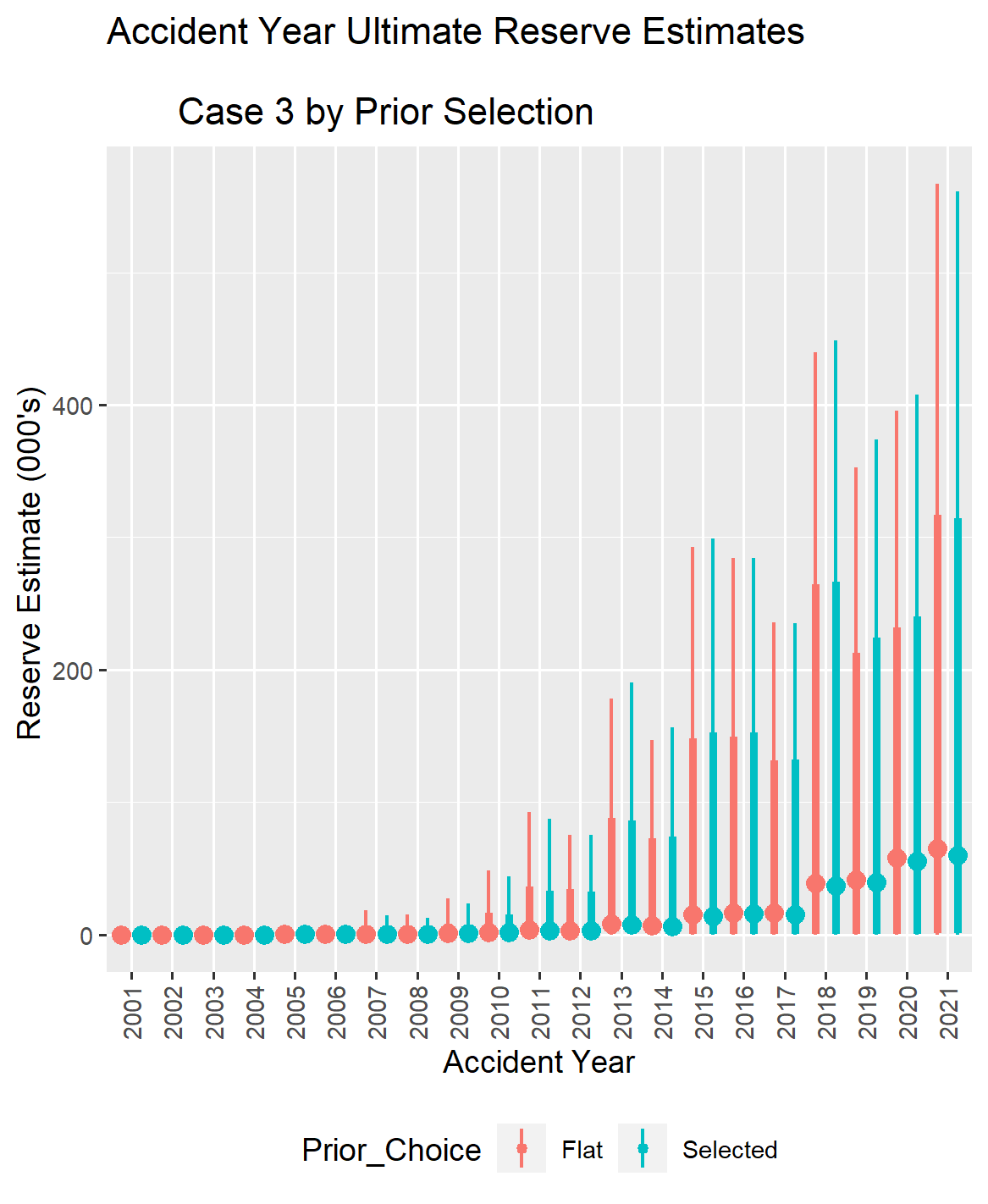
IV.3. Case 3 Comparison of Reserve Distribution With and Without Selected Priors
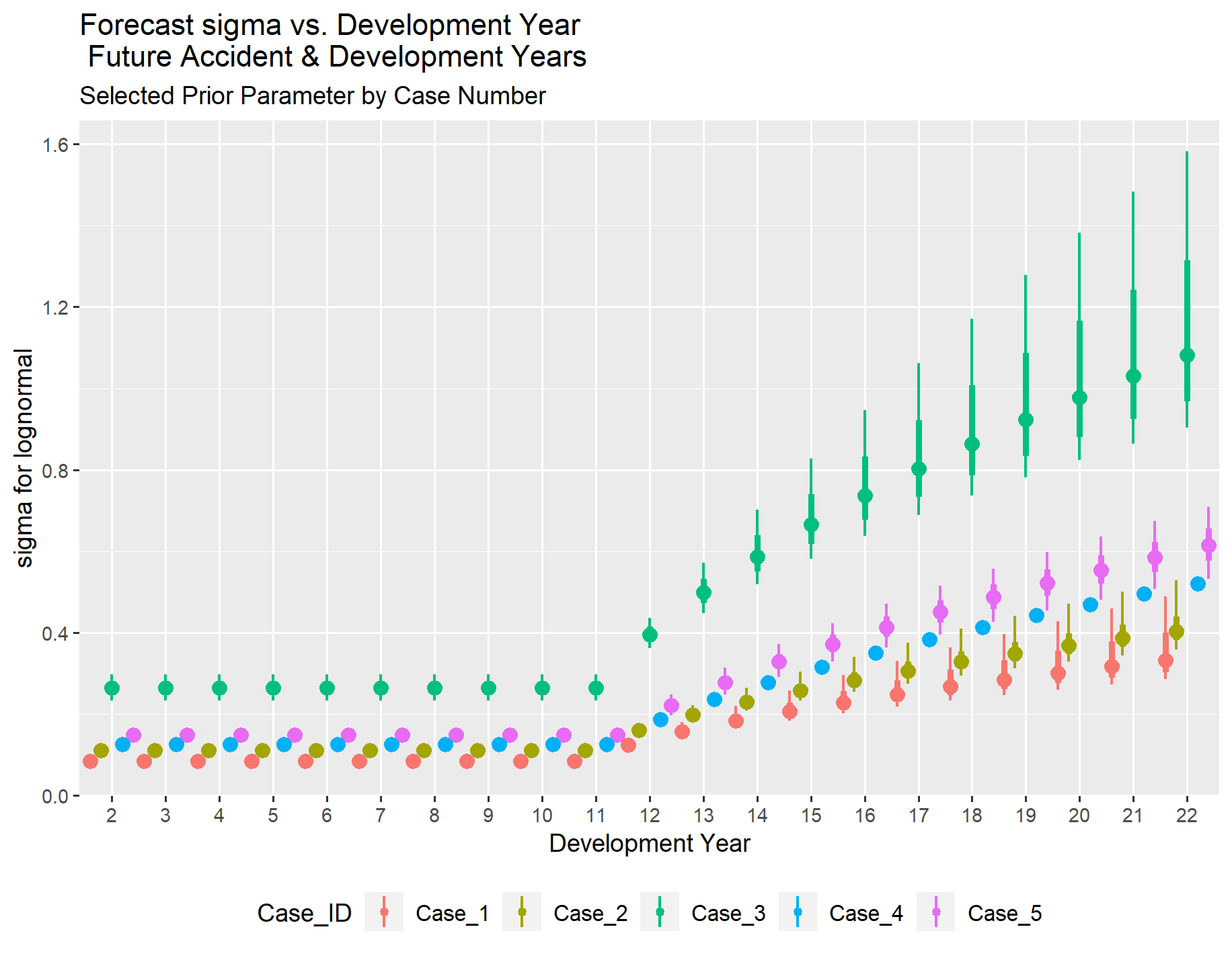
Dropping down to 100 exposures in Case 3 from 500 exposures in Case 2 tended to boost the parameter estimates for sigma as the accident year ages.
In practice, results from a larger sample could be used to inform prior distribution selections for all of the variables in a smaller sample. Using tighter standard deviation figures in the prior distribution for selected coefficients can compensate for limited information in the loss triangle. However, it is important to recognize that with a smaller amount of information, an increase in the variability of forecast results could be a realistic expectation. Then too, a given data set may just behave differently, and some caution is warranted in dialing down the standard deviation to avoid overriding information in the data set.








V. Case 4 Modeling Results
Case 4 has 22 accident years (2000 through 2021) with a uniform reported claim count of 50 reported claims at 12 months for each accident year and a maximum of 22 years of development time.
Case 4 is included to further explore how reducing the exposure amounts within accident years impacts the value of using selected prior distributions as the complement of credibility. This continuation of the experiment will help illustrate the effect of decreasing information in the loss triangle on the model’s accuracy and reliability.
V.1. Case 4 Results With Prior Distribution Selected
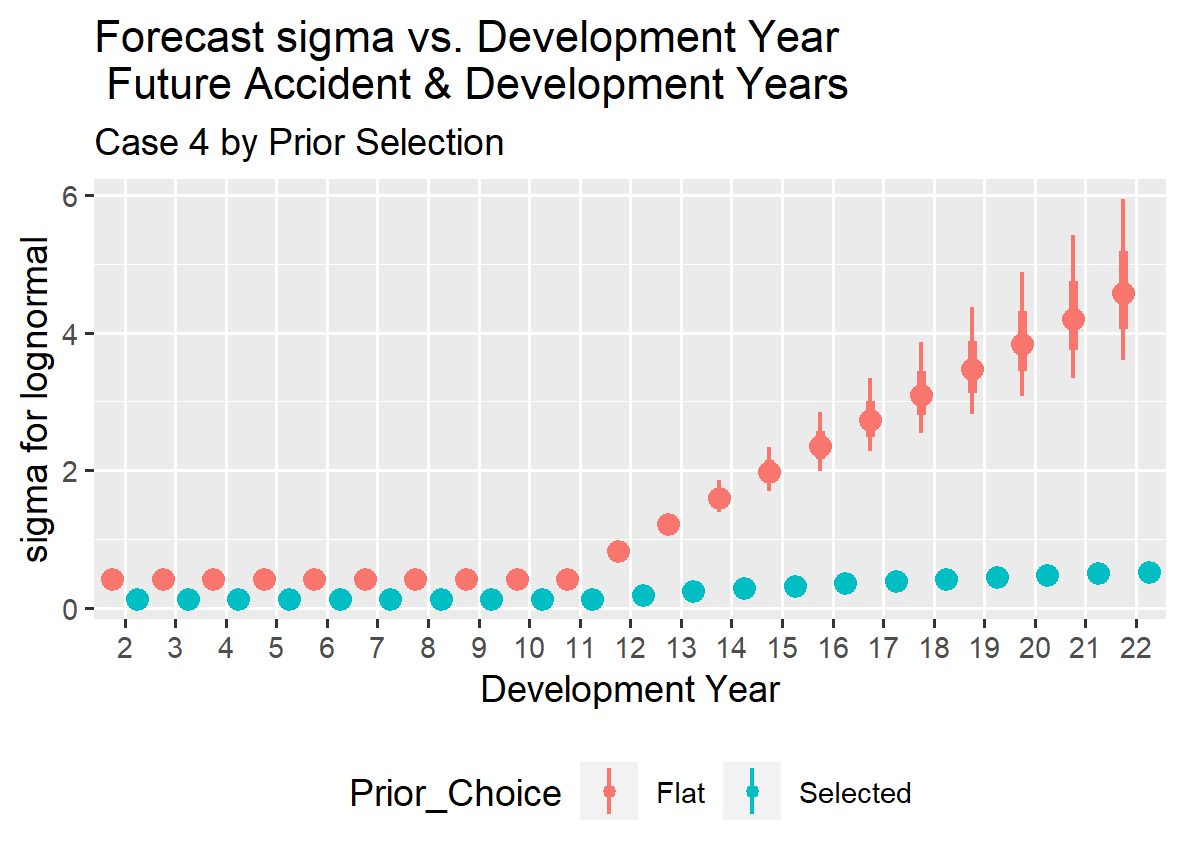
The prior distribution for Case 4 was based on the results from Case 1 due to the lower exposure levels in Case 4. In this particular situation, it was necessary to set one of the parameters for sigma, specifically Dev_Yr_10_Spline_Ln, to a constant of 0.57 which is the mean value from the Case 1 results. This adjustment was required because the information for sigma beyond ten years of development was too limited to model any change in sigma successfully with this reduced exposure (50 reported claims per accident year).
Given the relatively small number of exposures for Case 4, the prior distribution was adjusted to reflect the results from Case 1, with the standard deviation for the coefficients in the prior distribution set to a smaller number. This adjustment places less weight on the results from the data and more on the actuary’s prior estimates of the behavior of the development curve.
Please note that even though the reported claim count dropped from 100 in Case 3 to 50 in Case 4, the standard errors around the modeled parameters decreased with the use of tighter standard errors in the selected prior distributions. This made it practical to retain the Dev_Yr_10_Spline variable in the regression equation for mu.



V.2. Case 4 Results With Flat Prior
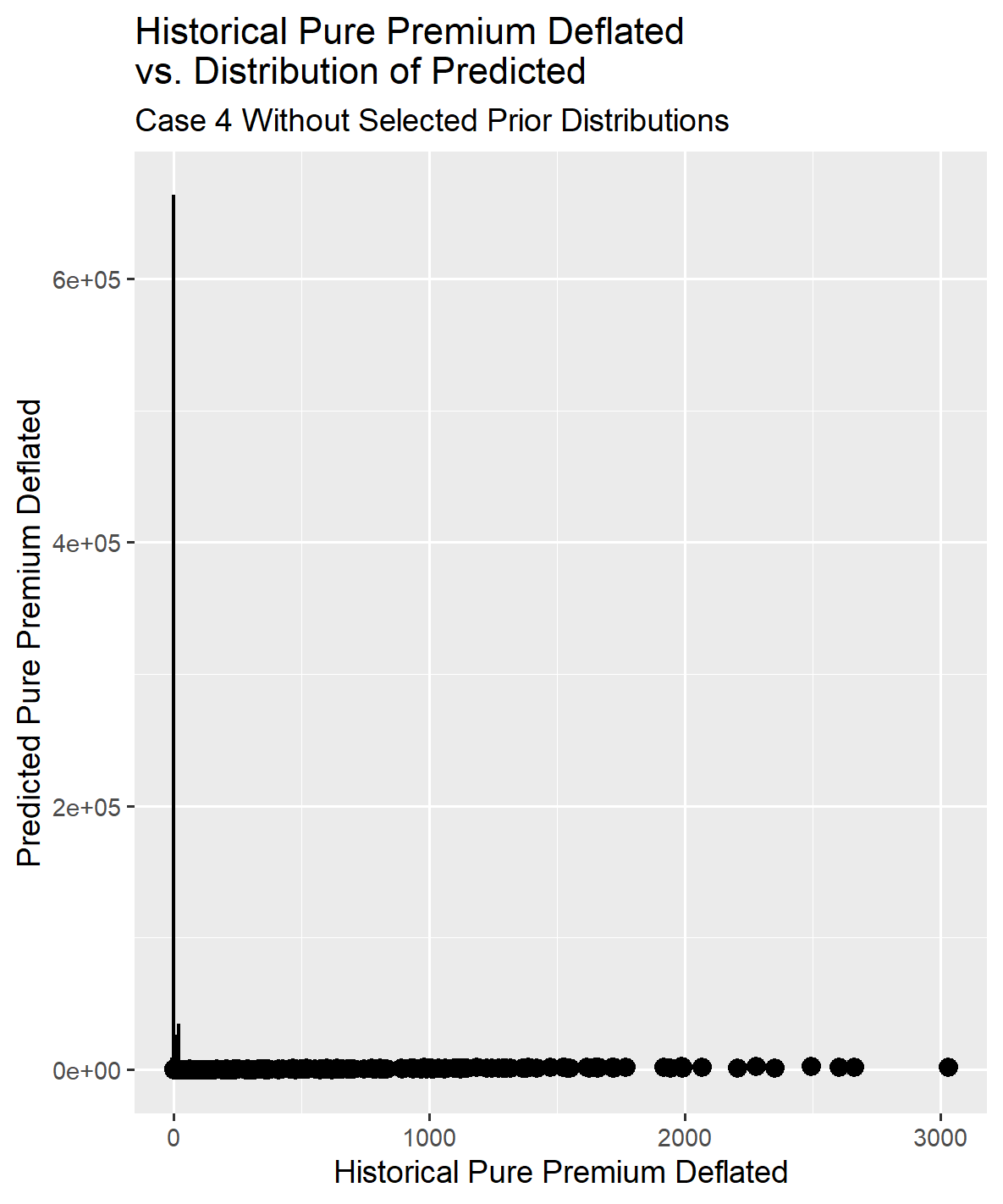
It was necessary to drop the Cal_Yr_Time and Dev_Yr_10_Spline variable from the model to obtain sensible coefficient results. The remaining coefficients now exhibit higher standard errors compared to earlier models, and the coefficient estimate for sigma has increased notably. Unfortunately, this adjustment has resulted in the graph comparing actual to modeled deflated pure premium values being distorted to such an extent that it is no longer informative.



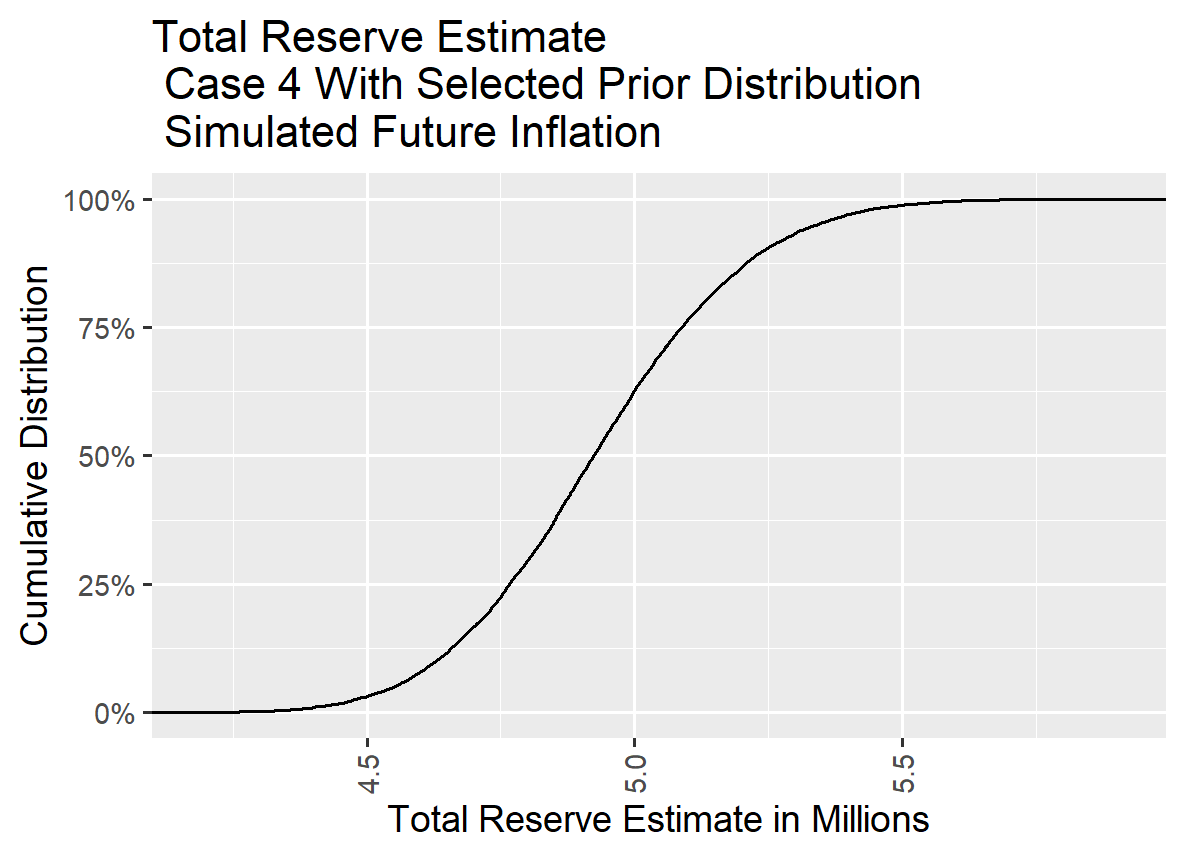
V.3. Case 4 Comparison of Results With and Without Prior Distribution Selected
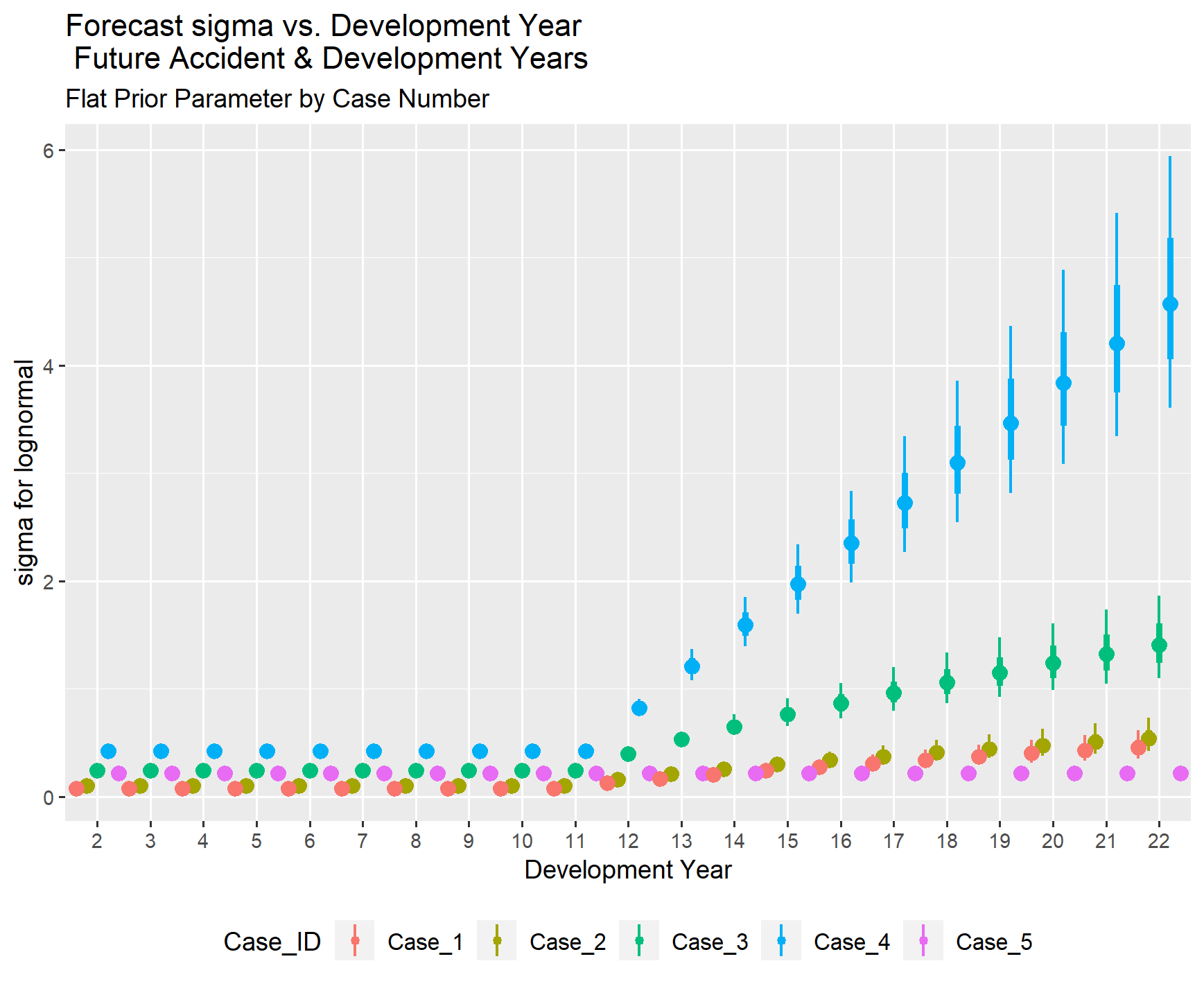
The reserve estimates for Case 4 without selected priors can become excessively large due to a significant increase in the sigma value in the tail of the accident year development period. Additionally, as the exposure amount decreases, the variance around the parameter estimates increases, leading to instability in the estimates.
For Case 4, the graph overlaying the distribution with a uniform prior and selected prior distribution values is not informative because the values for the flat prior distribution became excessively large in some cases. However, it was retained to maintain consistency in the sequence of information displayed across Cases 1 to 5







VI. Case 5 Modeling Results
Case 5 has 11 accident years (2011 through 2021) with a uniform reported claim count of 100 reported claims at 12 months for each accident year and we assume that incremental losses will continue out to a maximum of 22 years of development. We only have 11 years of development history though for the oldest accident year.
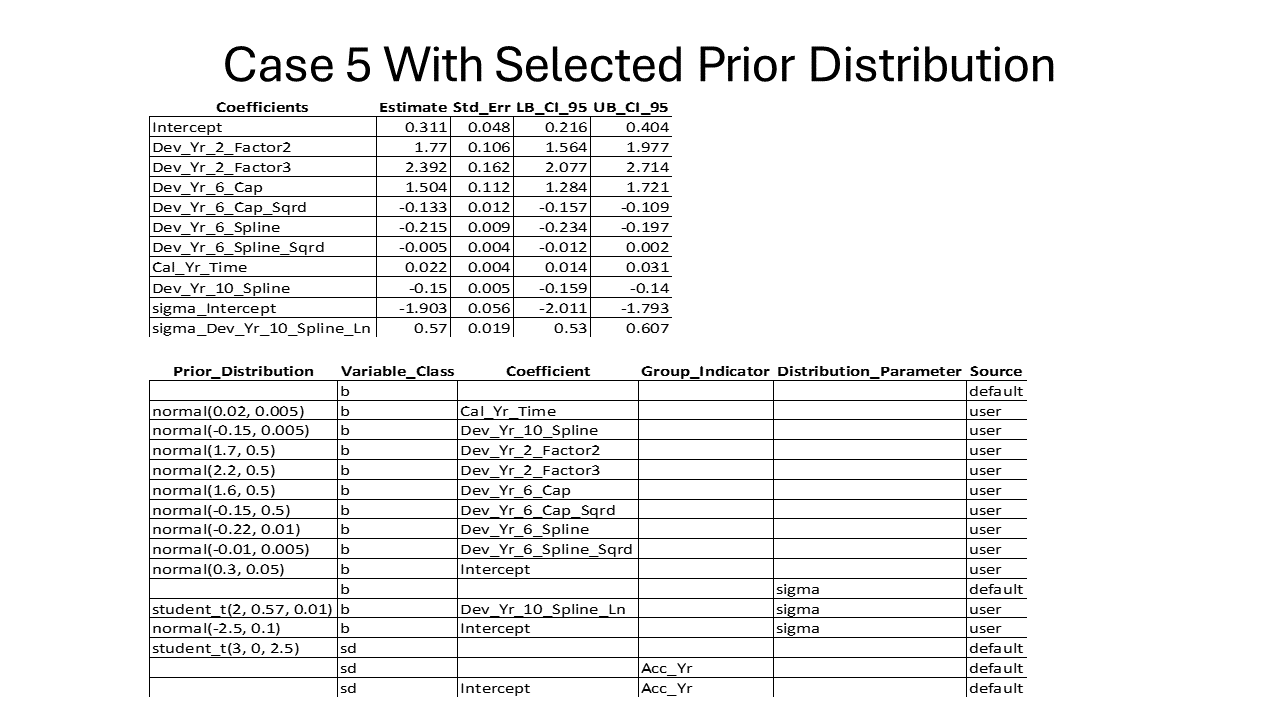
VI.1. Case 5 Model Results for Selected Prior Distribution
In this case, a lack of development information beyond 10 years necessitates supplementing the model with the parameter estimates from a larger data set, as demonstrated in Case 1, to obtain plausible reserve estimates. Specifically, due to the absence of development information after ten years, the distribution around the estimated parameters for the period beyond six years of development was constrained to be very small within the prior selection.
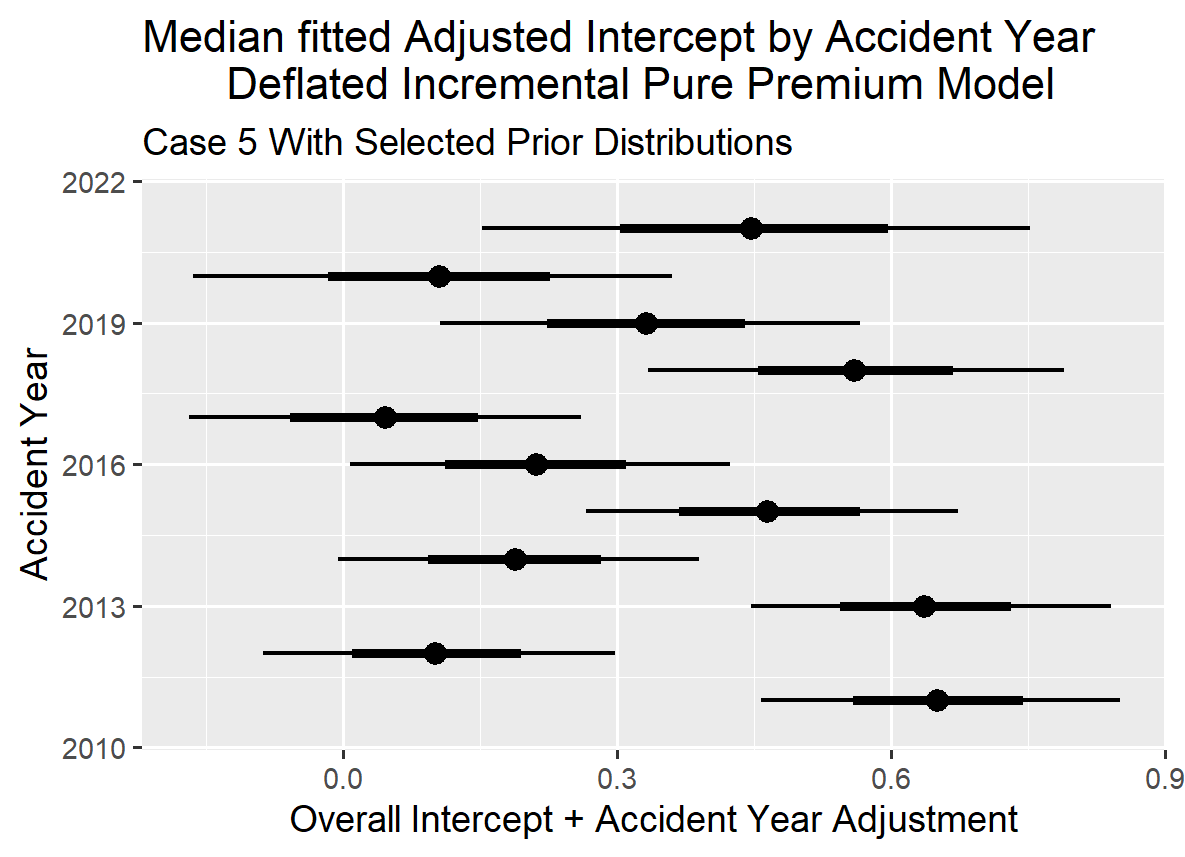
By comparing the parameter results from the summary below to the prior distributions used, it is evident that incorporating the information from the loss triangle did shift the mean estimate, even with limited data for coefficients related to early development periods. This demonstrates that when a prior distribution is used as a compliment of credibility in a Bayesian MCMC model, the information within the loss triangle can still impact the results. The prior distribution effectively places guardrails around the estimation process for posterior distribution parameters for coefficients related to later development years.
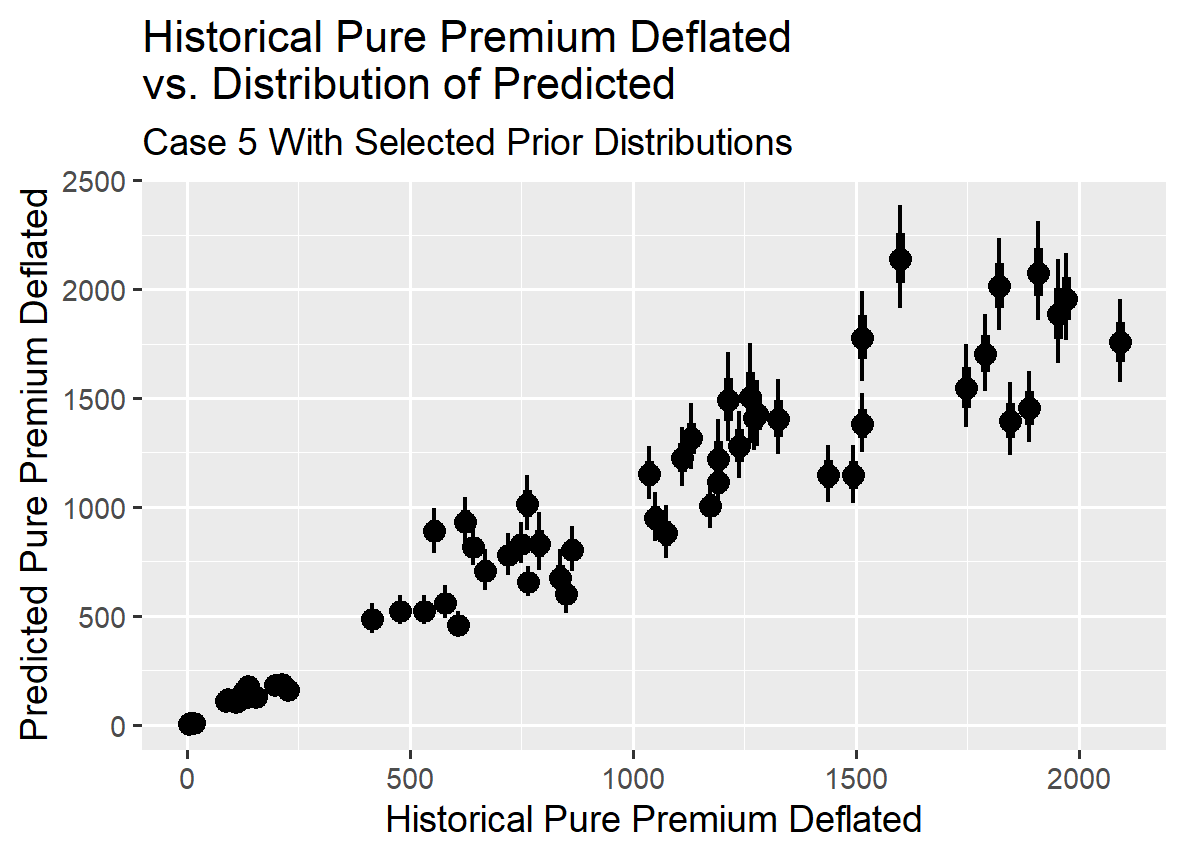
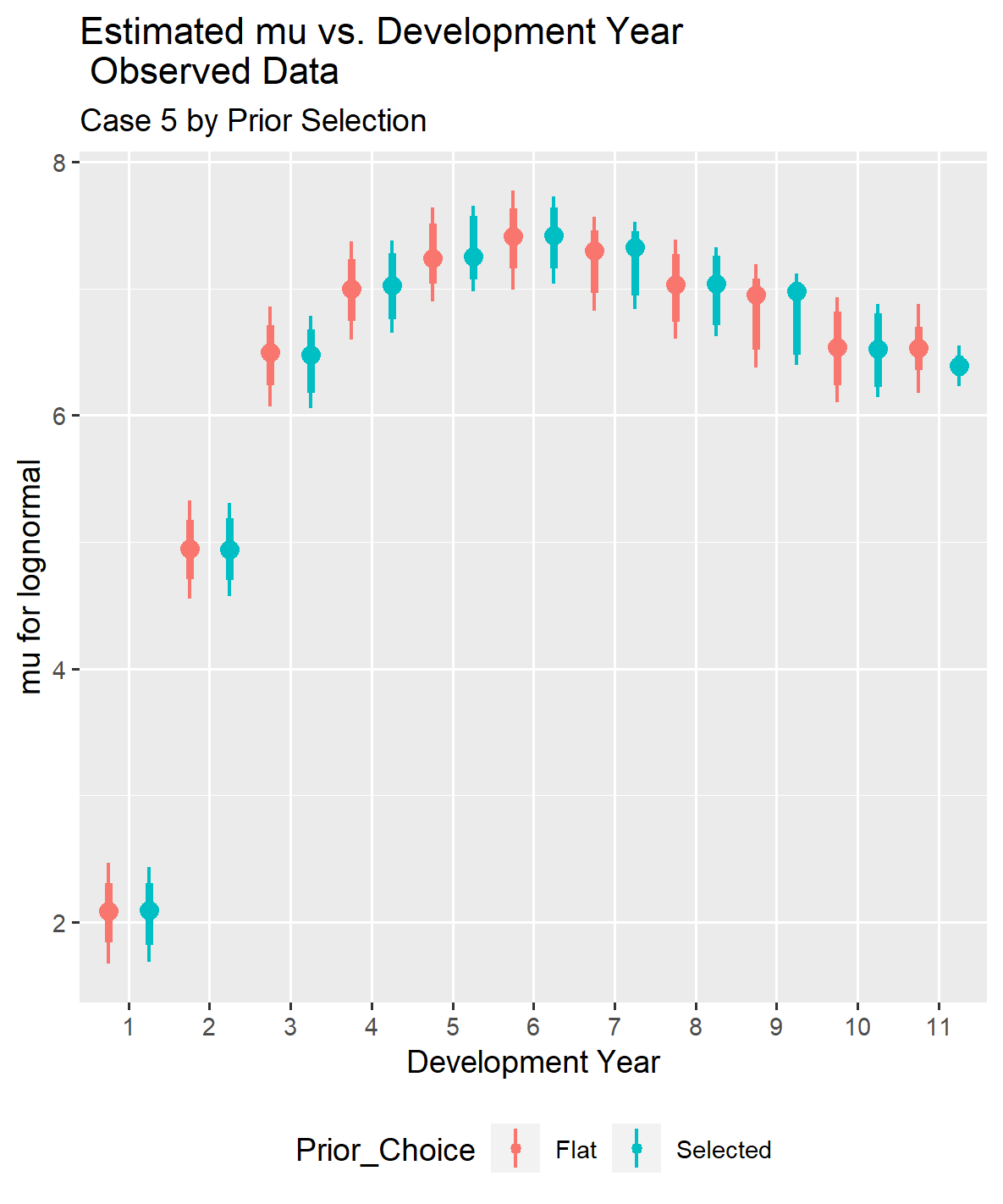
The graph showing the historical normalized incremental losses (pure premium deflated) compared to the modeled results, along with residuals graphs, indicates that the model provides a reasonable fit to the observations in the loss triangle.



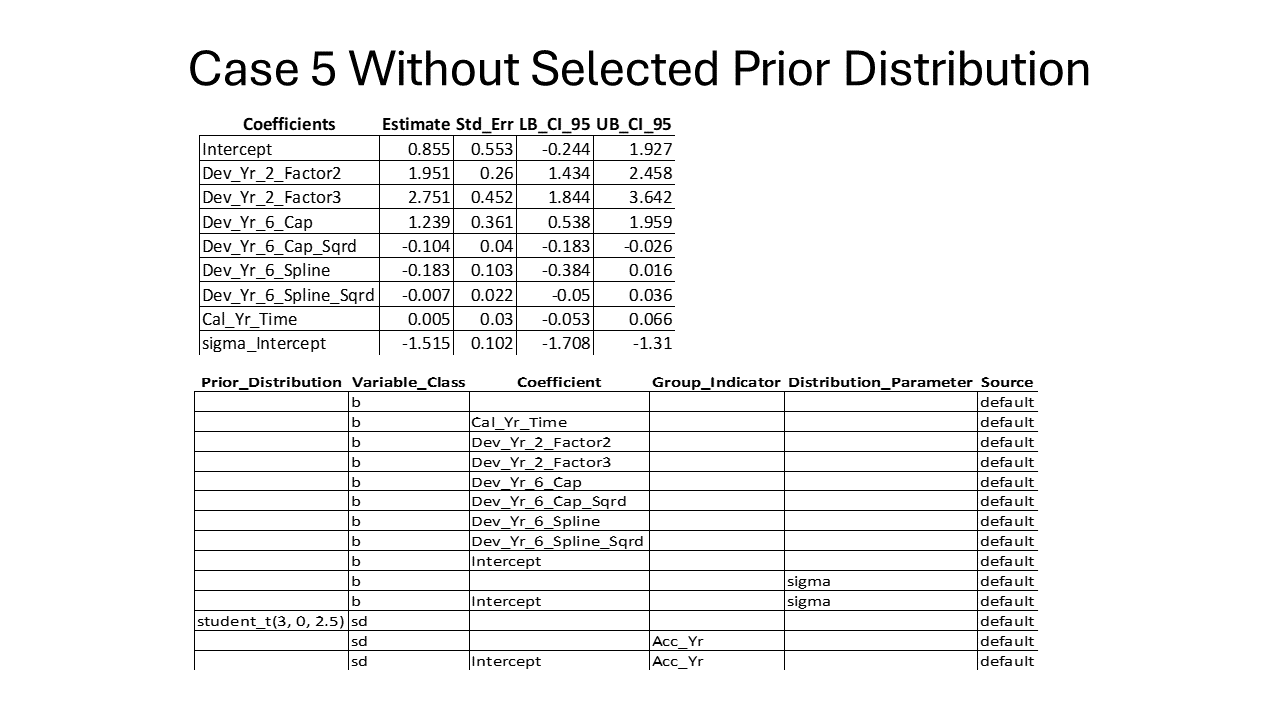
VI.2. Case 5 With Flat Prior
Due to the lack of information beyond ten years of development, it was necessary to exclude the parameters for the ten-year development spline explanatory variables for both mu and sigma.
If you examine the confidence interval results below, you’ll notice that for development years beyond six, the confidence interval includes zero. This suggests that using those variables becomes questionable. This poses a challenge because forecasting incremental payments out to 22 years of development is essential for squaring the triangle.
On a positive note, the fit for the observed data is reasonable, indicating that choosing to tighten the standard errors for a subset of the selected prior distributions could be an effective approach. You may have enough information for early development periods to allow the results from the data set to influence the fit, but you can tighten up the standard deviation for later time periods where there is limited or no data. That approach allows one to utilize the data at hand to the extent it is reliable and supplement the lack of data with outside knowledge (actuarial experience) to obtain a plausible reserve distribution forecast.



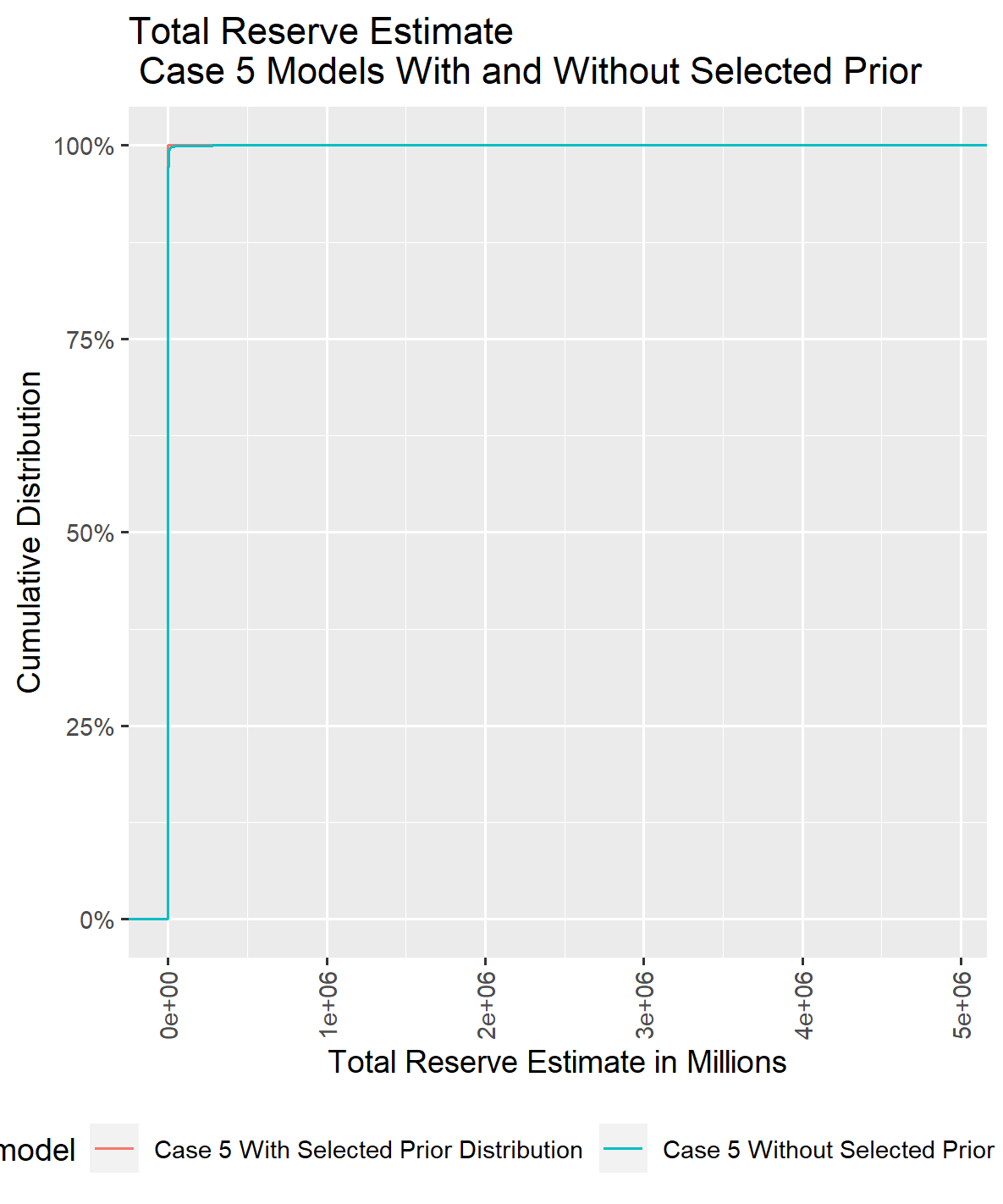
VI.3. Case 5 Comparison of With and Without Selected Prior Distributions
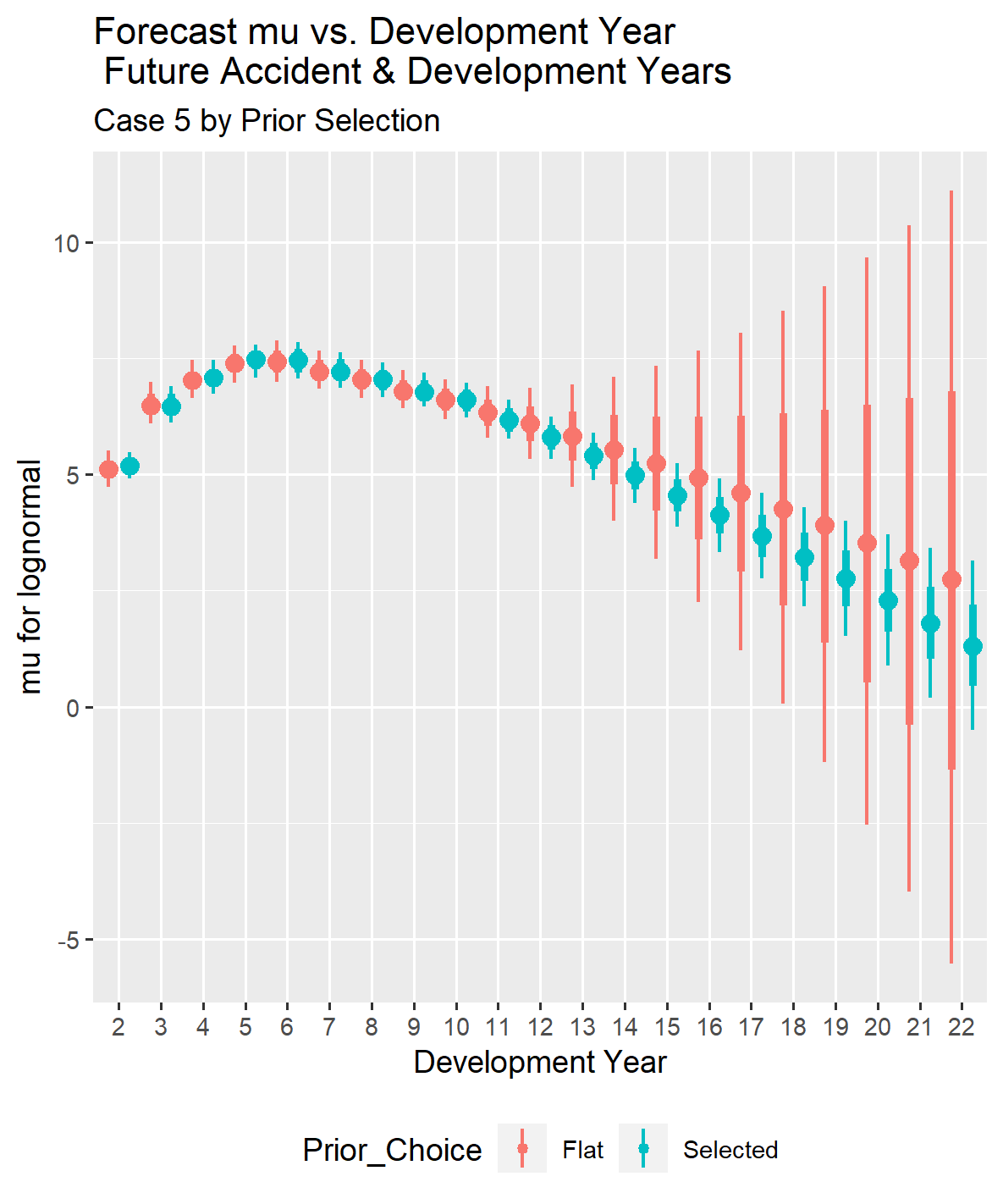
With no information for development years beyond ten years, reserve estimates become unstable when projecting incremental payments from eleven years to twenty-two years without a selected prior distribution. Additionally, sigma tends to increase gradually after ten years of development, but this trend cannot be accurately reflected in modeling without the ability to select prior distributions for the explanatory variables beyond ten years of development.








VII. Comparison Across Cases
VII.1. Comparison Across Cases for Selected Prior Parameters
Tightening the standard error parameter in the prior distributions for Cases 3, 4 and 5 resulted in minimal changes to the spread for the mu parameter estimates, even with less information. The sigma estimate for Case 3 is noticeably different and higher than those for Cases 1 and 2, which may realistically reflect the reduced information, while still producing plausible reserve forecasts. In Case 4, the sigma estimate is out of pattern with the rest but was set at a constant for the beyond ten years development period to ensure the MCMC routine converged to a plausible set of answers.




VII.2. Comparison Across Cases for Flat Prior Parameters
The variability in the forecast for mu and sigma exhibited more pronounced changes in the length of the confidence intervals as the information in the loss triangles varied, especially when compared to the results using selected prior distribution parameters. It is natural and reasonable to expect an increase in variability in the loss reserve forecast as the information in the loss triangle diminishes. The degree to which an actuary chooses to tighten the standard error range in a set of selected prior distributions requires professional judgement. Extensive experience in a given line may provide confidence in how the mean value should vary over time, but there remains an inherent increase in volatility as the sample size decreases.
The results for Case 5 clearly demonstrate the necessity of selecting prior distribution parameters to compensate for the lack of development history beyond eleven years when forecasting future time periods. The confidence intervals for mu beyond ten years are much larger than those for Case 3, and the forecast for mu does not decline at the same rate as seen in data sets that include experience for that time period. The assumption that sigma should remain flat as an accident year ages is not sensible, given the behavior observed in the data sets (and likely to be a true statement in general). This case generalizes the notion that some form of a selected prior distribution is essential when observations are not available for the time period being forecast.




VIII. Conclusion
The examples in this paper demonstrate how the Bayesian MCMC modeling environment can give an actuary the ability to supplement limited information in a sparse data set with experience gained from doing reserve analyses and general insurance knowledge. If you have observed development curves for a given line over time, you have an idea of what a plausible development curve should look like and how the stability in the development pattern varies as an accident year ages. Similarly, if you have worked with a given line of business for a while, you are likely to believe that the annual loss cost trend on top of a general inflation index is some small positive number rather than believing it is uniformly distributed over the real number line.
Using the terminology from the CAS exams, the prior distribution feature in a Bayesian MCMC analysis allows the actuary to effectively establish the compliment of credibility (or guardrails) for the population variable coefficients in a regression equation within the Bayesian MCMC environment. Variables that fall into the group category use the overall mean results in the data set across the group as the compliment of credibility. Note that while the examples in this paper used the group variables to introduce a form of tempered interaction with the intercept by group member, one could also apply this technique to shown an interaction effect with continuous variables that describe the smooth curve for a group variable like a business unit.
The paper is centered around examples of applying Bayesian MCMC to reserve modeling problems. There are many good textbooks on Bayesian MCMC and numerous articles and websites that provide a wealth of information. Providing a few examples that specifically address how to apply those techniques to loss reserving with sparse data is intended to help actuaries apply Bayesian MCMC concepts in practice.
The code that produced these examples is available to anyone interested in exploring the steps involved in building the models and generating the result summaries. To maintain a reasonable length, the paper does not delve into the mechanics of creating the model and organizing the results to evaluate the model. However, accessing the files, executing the code, and experimenting with different models and data sets exhibiting various behavior characteristics can be highly beneficial.
The paper also demonstrates that using simulation allows one to experiment with this technique and understand how different adjustments to the prior distributions affect the end results. There are various modeling forms available within the Bayesian MCMC environment, and using simulated data sets creates a safe sandbox for trying out those options.
The practical application of Bayesian MCMC became feasible after development of advances in software and algorithms between 2015 to 2020. Before this period, the time required to run a Bayesian MCMC, organize the information, and evaluate the results often made it impractical. However, the introduction of STAN, which uses the Hamiltonian algorithm to guide the MCMC search process, significantly reduced the time to run a Bayesian MCMC model constraint. The software and algorithms for organizing and evaluating the results of Bayesian MCMC modeling exercises also saw substantial improvements during this time.
While the software and algorithms available to run a Bayesian MCMC analysis have improved rapidly over recent years, it still requires an investment of time to learn how the technique works and how to operate the software. My hope is that this paper will provide some motivation to make that investment.