









1. Introduction
1.1. Background & Motivation
A report on the first CAS technology survey (Casualty Actuarial Society 2022) noted the following:
-
Excel is prevalent in day-to-day actuarial workflows.
-
Survey respondents acknowledged Excel was highly relevant to the actuarial pricing and reserving disciplines.
-
A high percentage of survey respondents self-assessed as having an advanced skill level in Excel, with many simultaneously expressing a desire to increase their proficiency.
Further, a review of the Excel development blog (“Excel Blog” 2024) reveals a steady stream of updates to this well-known spreadsheet application. While some of these are minor, many are expansive. This has not gone unnoticed by the actuarial community, as a recent CAS report on data and technology topics (CAS Data and Technology Working Party 2016) observes that Excel has undergone changes that make it a competitor specifically of business intelligence (BI) tools.
However, some of these changes may not be immediately obvious to a busy actuary who only sees occasional rearrangements of the Excel ribbon and whose training and day-to-day work may not have exposed her to features beyond pivot tables, lookups, and macros.
Taken at face value, these observations would suggest that CAS members, particularly those with reserving and ratemaking responsibilities, could be well-served by assistance with accelerating their Excel learning.
1.2. Outline & Scope
This paper provides a summary of Excel features introduced since the early 2010s, accompanied by workbook examples built with a slant toward reserving computations. The narrative of this paper will include a discussion of foundational topics, along with comments on the workbook examples. The examples are simple and constructed on a much smaller scale than what is expected to be encountered in real-world implementations. Some common pitfalls and suggestions will be reviewed, and additional resources will be highlighted.
The target reader is assumed to know how to confidently navigate Excel and to have some familiarity with data transformations in general. Further, some more advanced examples are provided for those with an appetite for authoring code. The examples are designed to be evocative, and the accompanying discussion will not be exhaustive. Section 5.3 recommends several guides that methodically review these features in greater detail. Further, some actuaries may discern more effective ways to structure various routines or transformations than exhibited here.
Finally, these examples were built using Microsoft 365. Features requiring an internet connection were not included in the scope, but some are briefly discussed in Section 5.2. As a disclaimer, Power Pivot (discussed in Section 3) may need to be activated as an add-in, and some formulas discussed in Section 4 may not be accessible for earlier versions of Excel, in which case the accompanying workbook examples will not function properly.
2. Power Query – Low-Code/No-Code Data Wrangling
2.1. Overview of Power Query
2.1.1. Introduction
Power Query is an Extract-Transform-Load (ETL) package used to connect an Excel workbook to external data sources, manipulate this data, and export it to the spreadsheet environment for further analysis. As with other low-code or no-code BI packages that may be familiar to actuaries (Chen and Siu 2024), users can construct queries without having to compose any code. Nonetheless, a familiarity with Power Query’s language, M, can be helpful to modify code generated by Power Query’s automated prompts, add documentation and legibility, or write queries from the ground up. While many examples in this section include discussion of M, most of Power Query’s features can be accessed without knowledge of the language. Documentation, including references for functions cited in this paper, can be found on Microsoft’s website (“Power Query M Formula Language” 2024).
Power Query can connect to text files, other Excel workbooks, *.pdf documents, web sources, databases, and information contained within the current Excel workbook itself (such as information contained in tables, other named ranges, or entire worksheets). It has built-in prompts that guide the user through the steps required to generate connections to these sources. Upon a source being connected via one of these prompts, a query is generated and stored within the Power Query Editor environment, and the user may apply further transformations to the imported data, including interacting with other data sources that have also been imported via Power Query. This process may be repeated for other data sources and can be structured to automatically import a directory containing identically formatted sources (for example, a folder containing several dozen *.csv documents). Additionally, when connecting to a database (such as an SQL database), code reflecting that database’s native query language can be incorporated directly into the Power Query statement to minimize transformations within Excel. Finally, the processed data may be exported to the spreadsheet environment in several ways, such as into a table, a pivot table, or stored within the workbook’s Data Model (to be discussed in greater depth in Section 3). Once a query executed, the output is static. The query must be refreshed to produce new output. Queries may be refreshed manually or according to other events, such as a schedule or upon opening the workbook.
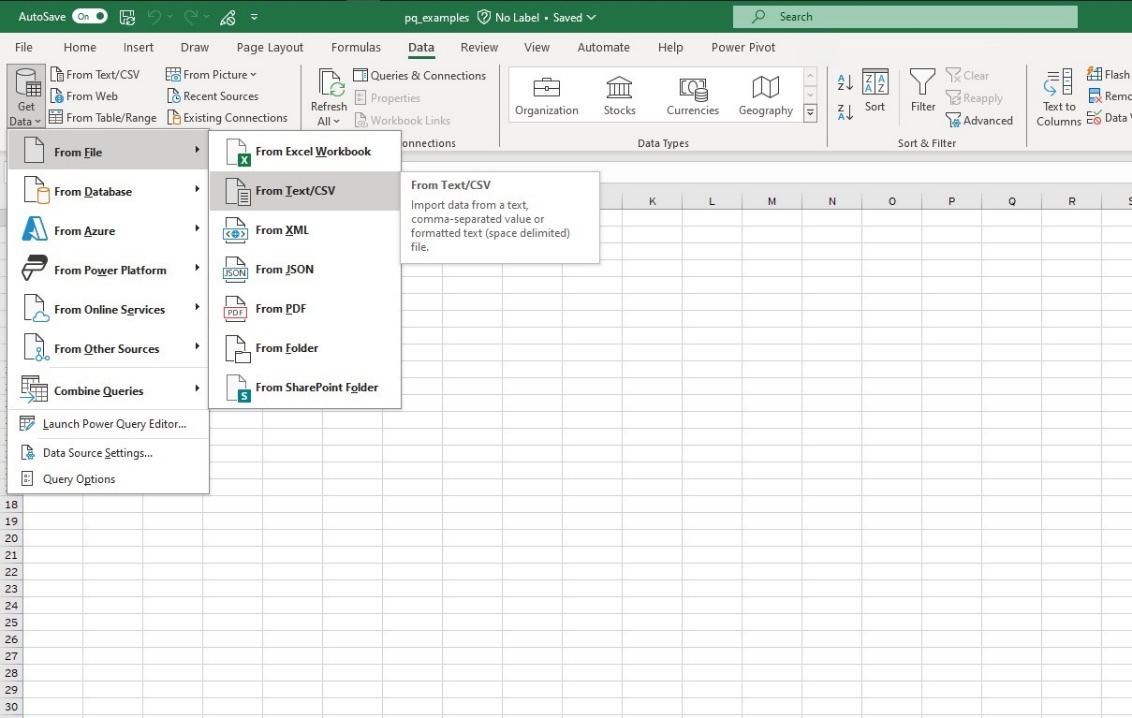
Power Query may be accessed several ways:
-
Open the Power Query Editor from the Excel ribbon to build new queries or edit existing ones within the editor itself (figure 2.01).
-
Initiate the construction of a new query for specific items, such as connecting to a new data source, or merge existing queries directly from the Excel ribbon (figure 2.02).
-
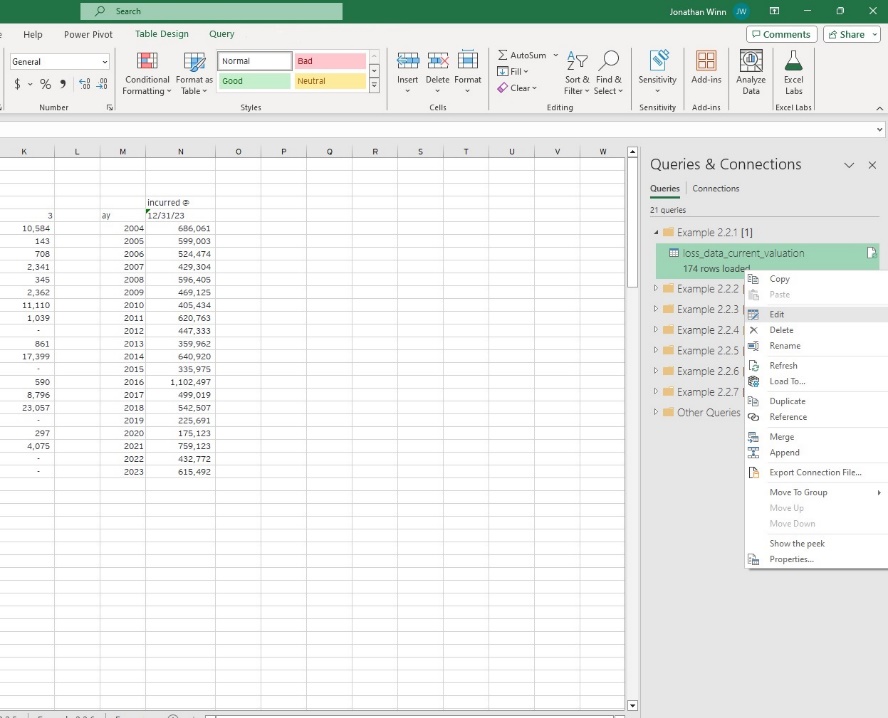
Select an existing query to edit from the Queries & Connections pane (figure 2.03; this pane may be viewed by selecting “Queries & Connections” under the “Data” ribbon).
-
Using a keyboard shortcut (alt + F12).



2.1.2. Importing data
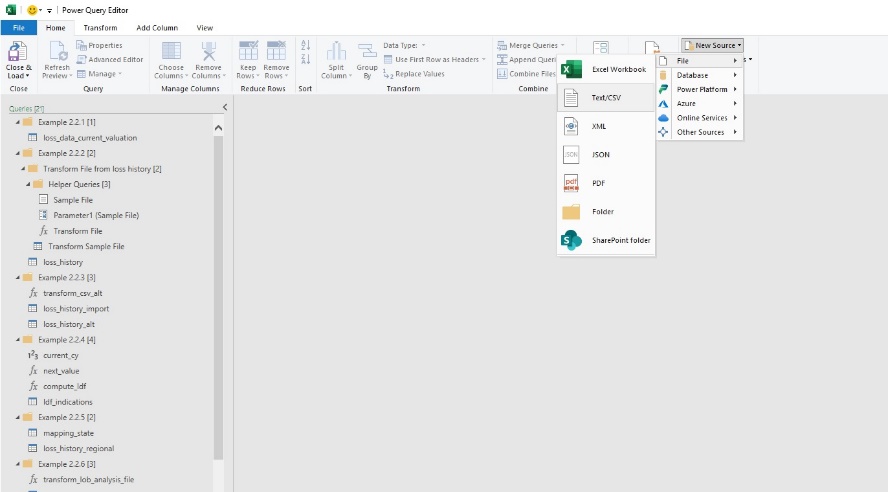
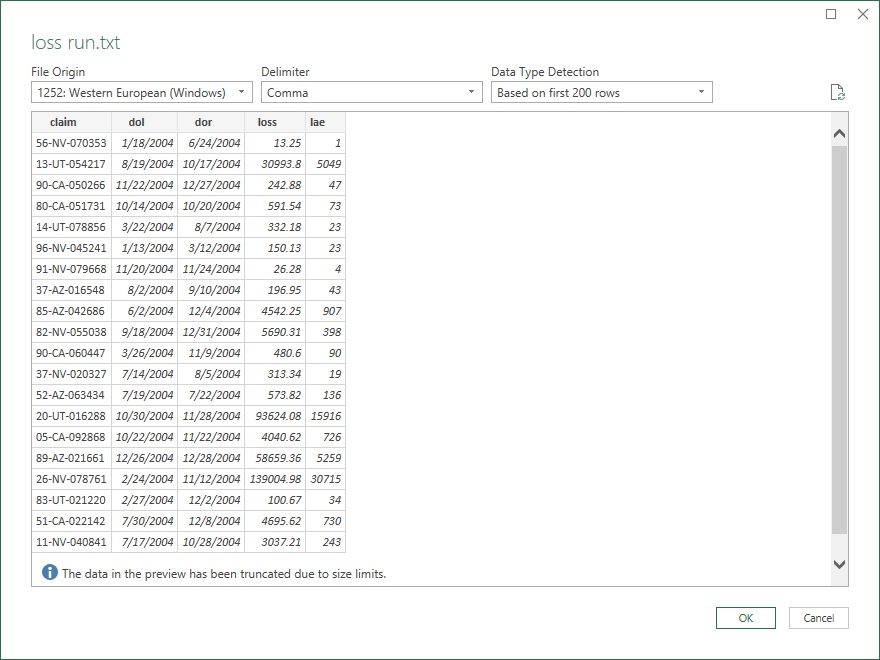
Suppose it is desired to import and summarize a loss run based on inception-to-date claim data stored in a text file. (Note that the discussion in Sections 2.1.2, 2.1.3, and 2.1.4 reference Example 2.2.1 below). The user may initiate the import either on the ribbon (figure 2.04) or within the Power Query Editor itself (figure 2.05) and be guided through the process. With the automated prompts for all data types, the user will be shown a preview of the data to be imported prior to the query being generated (figure 2.06; this is the prompt that appeared to import the *.csv file in question).
Once the prompt has completed, the Power Query Editor will open and the new query will appear alongside other queries on the left side of the screen; the M code for the last line of the new query will be displayed in the formula bar on the middle of the screen along with a preview of the query results; and a record of individual M statements will be shown under “Applied Steps” on the right side of the screen.



2.1.3. Processing data within the Power Query Editor
As with importing data, the user can access different automated prompts for manipulating data, and these are shown on the “Home,” “Transform,” “Add Columns,” and “View” ribbons within the Power Query Editor. Further, the user may right-click on individual columns shown in the preview window to initiate a new transformation.
As new transformations are performed, the Editor will generate M code for each step, and the step will also be recorded in the Applied Steps window. Clicking on any of the steps will revert the preview to the data implied at that step, which is an invaluable tool for debugging. Further, it is possible to review and edit the generated code directly in the formula bar or from within “Advanced Editor” view by either right-clicking on the individual query or launching the editor from the “View” ribbon.
Returning to the current example, several steps have been performed (to review, the Power Query Editor must first be open, the loss_data_current_valuation query selected, and then the steps may be reviewed in the Applied Steps window on the right-hand side of the screen):
-
Used the first row as headers (this step was automatically added).
-
Converted data types (this step was automatically added). The LAE column was converted to a whole number, which is not desired. This can be remedied by inserting another data type change step, or manually edit the M code in the formula. Any automated data type transformation should be reviewed as this is a common area for errors to arise and propagate.
-
Renamed dol and dor columns to ay and ry.
-
Added a state column by extracting between hyphen delimiters.
-
Added a custom column calculating incurred loss and LAE (incd_tot).
-
Grouped and sorted data, as it was only desired to create a summary and not retain claim-level detail.
2.1.4. Exporting processed data to the workbook
Once work within the Power Query Editor is complete, the user can either exit the Editor (in which case all new queries will be automatically exported as tables into newly created worksheets by default), or select an option under “Close & Load.” In this case, the data was exported to a table. This can be changed for future query executions by right-clicking on the query name in the spreadsheet environment and selecting a different option. In general, when in a testing or development phase of a project, selecting “Only Create Connection” will result in less clutter and better performance as only the query statements are retained and no additional data is generated within the workbook. Note, however, that connection-only queries cannot be accessed by external workbooks. This is because no data is generated or saved by Excel for connection-only queries, unlike queries that have been exported to a table or a pivot table. When constructing dashboards, loading either to the Data Model or a single pivot table may be the preferred option. If the Data Model is not being employed, a table should be the first choice, and the exported data will enjoy the advantages of the usual table structure. This would include ease of referencing the information within the table from elsewhere in the workbook, and the user may add formulas within the table that will be retained if the underlying query is refreshed.
In this example, the r_lag column was added to the table, and a triangle was constructed on the right-hand side for analysis. If, for whatever reason, the underlying query was refreshed and new rows of data were added, or fewer rows were loaded, the r_lag column would grow or shrink as appropriate. If new columns of data were added, the r_lag column would be translated to the right and still be functional. However, if either the ay or ry column was renamed or removed and the query refreshed, r_lag would return an error.
2.2. Spreadsheet Examples
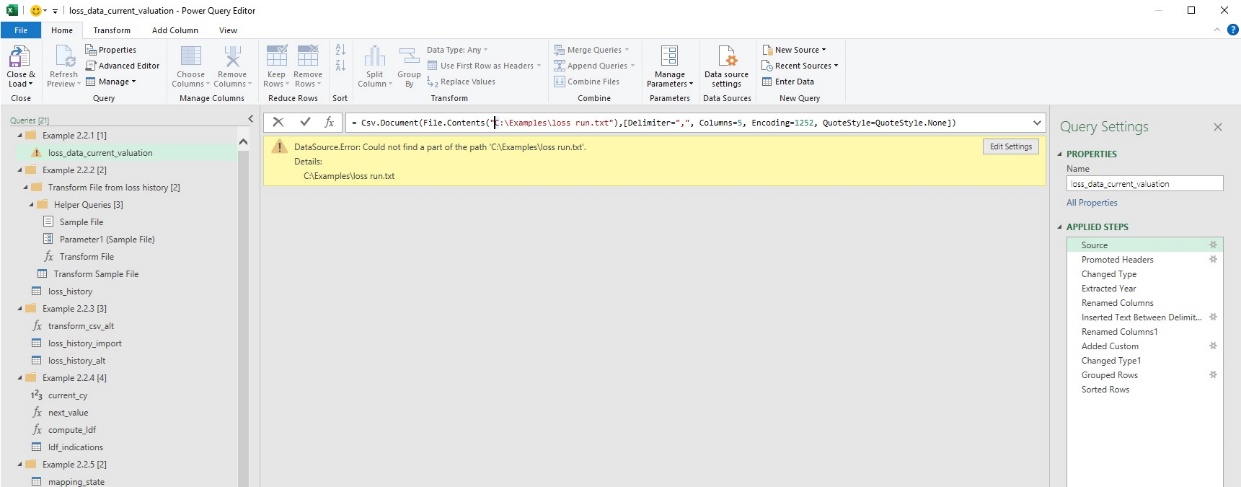
All examples below can be found in the attachment pq_examples.xlsx, under similarly titled worksheets and query groupings. The directory references have been anonymized, and the user must update the directory reference on her own machine to point to where the sample input files are housed (most of the queries will not run but will instead indicate the DataSource.NotFound error). The simplest way to do this for most examples will be to go to the first step of each query and manually edit the “Source” step within Applied Steps (figure 2.07) or the Advanced Editor, if necessary, as well as the demarcated cells in the spreadsheet environment for Examples 2.2.3 and 2.2.6. Doing this will provide a good introduction to working directly with either the formula bar or Advanced Editor.

2.2.1. Data from a single file (automated prompts)
The steps discussed in Sections 2.1.2, 2.1.3, and 2.1.4 relate to the processes captured on the worksheet titled “Example 2.2.1,” and the associated query group “Example 2.2.1.” For background, this is a loss run showing claim-level records and inception-to-date financial data. The results of the one query in this example (loss_data_current_valuation) was loaded into the table with the same title.
2.2.2. Data from multiple identical files (automated prompts)
When importing an entire folder of files using automated prompts (which may be accomplished from the Excel ribbon by selecting “Get Data” → “From File” → “From Folder”), the user first identifies the target directory, and several options are given for the order of operations for combining and transforming data. In this example, the option to “Combine & Transform” was selected, and several helper queries were automatically generated:
-
loss_history – This is the query which will be used as the main output. It applies the function “Transform File” to all files taken individually (functions to be discussed in Section 2.2.4). For this example, loss_history was edited further to change the fields to appropriate types, use the name of each file to add the cy field, aggregate the data, and sort the data. Finally, this was loaded into a pivot table.
-
Transform Sample File – This query may be modified to change the transformations applied to individual files. It was automatically generated in such a way that any changes to its code will be passed to the “Transform File” function.
-
Helper Queries – These queries operate in the background to assist loss_history and “Transform Sample File.”
When importing data from a folder, it may help to manually review earlier steps in Applied Steps to ensure no hidden files or other files not otherwise intended to be imported get included. This could be remedied by applying filters based on the names or types of files in the target directory, for example. This can be seen by looking at a preview of Folder.Files( ) (in this case, occurring at the “Source” step of loss_history), which lists all the files in the target directory. Remaining at the preview of the “Source” step, one feature of Power Query worth noting is that the values in the “Content” and “Attributes” fields are not simple numerical or character values, but rather references to the underlying files’ data stored in binary format and a list, respectively. Power Query is flexible regarding the way records can be referenced, and it is possible to include records which point to table or lists, and pass those entire tables through transformations. Clicking on the individual cell will give a preview of the contents of that item at the bottom of the preview section in the Power Query Editor (figures 2.08, figures 2.09).


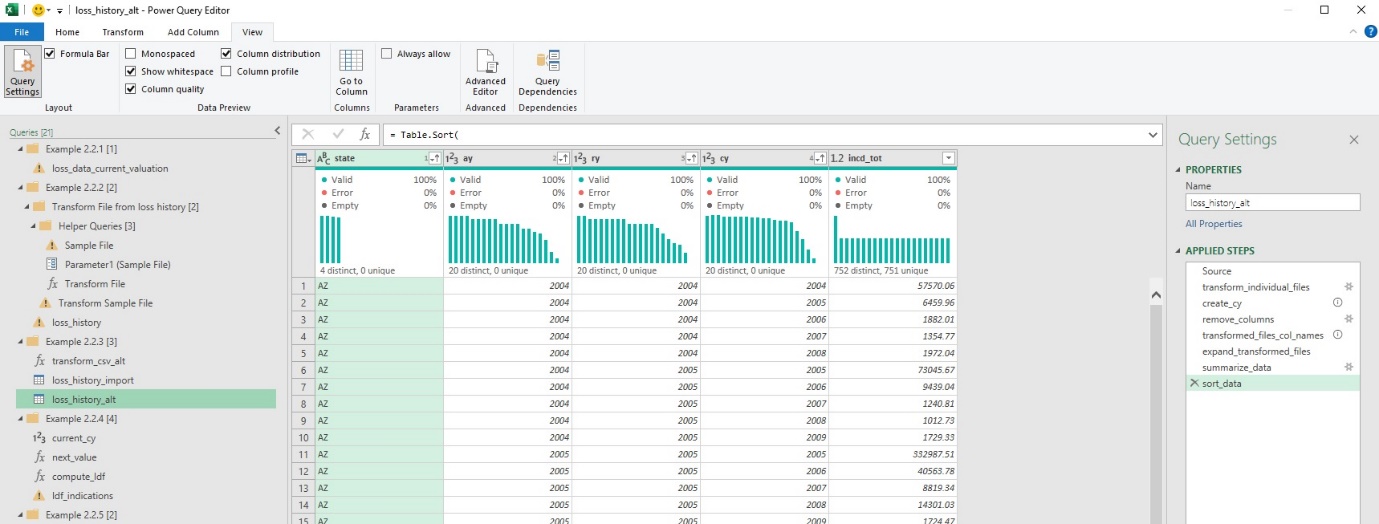
2.2.3. Data from multiple identical files (alternate implementation)
Although using automated prompts may allow for quick construction of queries, it can be advantageous to either modify the code for reasons such as improving legibility, organization, or adding documentation. Example 2.2.3 includes an alternate implementation of the process in Example 2.2.2.
-
A function is used to import the value of a named range (loss_history_filepath), which, if the target directory changes, allows it to be changed in-spreadsheet rather than in the M code itself. To avoid a common error (Formula.Firewall) that can arise when referencing multiple data sources in a single query, a separate query was written to first import the directory of files (loss_history_import), and then process in a separate step (loss_history_alt).
-
A single function was written to handle transforming individual files (transform_csv_alt). A disadvantage of this layout is that it is difficult to view the operation of the function via Applied Steps.
-
All M code was reformatted to increase legibility, both by adding tabs and spacing as well as by having cleaner naming conventions. Documentation was also added to the M code using // to identify comments. Comments that take up multiple lines can be identified by a prefix of /* and a suffix of */. Note that different documentation within the “let” statement can be seen on Applied Steps.
-
Within the loss_history_alt query, some choices were made to illustrate two features of using the Advanced Editor:
-
Nesting a “let” statement when creating the cy field. This simplifies the information exhibited in Applied Steps, but doing so can make it harder to diagnose issues via viewing different transformation steps because several transformations are collapsed within the create_cy step.
-
Executing different steps “out of order.” In this case, an intermediate step was used prior to the expand_transformed_files step. Specifically, transformed_files_col_names, which is intended to dynamically extract the column names from the output of the transform_csv_alt query, was first defined in reference to an earlier step, transform_individual_files. The following step, expand_transformed_files, references the two earlier steps remove_columns and transformed_files_col_names.
-
2.2.4. Functions
As seen in Sections 2.2.2 and 2.2.3, customized functions may be created and referenced within proper queries. Functions can take a variety of inputs, such as scalars, lists, and tables. A function can be written as a blank query or copied from an existing query and edited into functional form using the Advanced Editor. In the previous examples, functions were used for transforming the content of imported *.csv files (transform_csv_alt), as well as reading in values stored in named ranges in the current workbook (get_scalar). Example 2.2.4 contains examples of more functions, including one familiar to actuaries that computes loss development factors based on the loss_history_alt query. Several other illustrative features added include additional list and table manipulations, the use of Table.Buffer( ) to improve performance, formula nesting, and using non-standard aggregation when calling Table.Group( ).
In practice, there may be more expedient ways to compute chain ladder indications, and this example is not necessarily intended to reflect recommended usage. It may be more efficient to structure triangles within a SQL statement or compute the result of methods elsewhere in the flow of an analysis. Nonetheless, we have found utility embedding traditional actuarial reserve models within Power Query to perform light-touch exercises using fixed assumptions for interim experience monitoring and forecasting.
2.2.5. Data from current Excel workbook
The previous examples have shown how a named range from the current workbook can be referenced by a query. To build a new query in this way, the user could select either a table or a named range within the spreadsheet environment and click “From Table/Range” button on the ribbon. Example 2.2.5 shows a table (mapping_state) being brought in by the get_table function, and then merged with the loss_history_alt query to summarize the data according to larger regional definitions. Merging queries can be done using automated prompts or by invoking a function such as Table.NestedJoin. In this case, the loss_history_regional query was made within the Power Query Editor by selecting “Merge queries as new” for loss_history_alt and merging with mapping_state using a many-to-one left join.
2.2.6. Data from other Excel workbooks
When connecting to another Excel workbook, Power Query can read in data for several structures stored in a workbook, such as individual sheets, named ranges, and tables. Care should be taken which is imported, and in practice maximizing reliance on tables rather than unstructured data in worksheets is preferable. In the case of Example 2.2.6, a customized approach is used to bring in the values from a named range contained within each similarly structured workbook (analysis_summary) and exported into a table. Timestamps showing when the files were each last saved and accessed by the query are also returned.
2.2.7. Data from a (fictitious) database using embedded SQL code
Example 2.2.7 contains an implementation of a connection to a fictitious SQL database. The user may connect to a SQL database using an automated prompt, which requires entering the server and database address, SQL statement, and credentials. In this case, the final query statement was edited in the Advanced Editor to allow the valuation date to be dynamically spliced into the SQL statement passed to the server.
2.2.8. Topics not reviewed
Several topics were not reviewed, and interested users may explore for themselves:
-
While some data cleansing was included in the workbook examples, there are many functions used to clean data, and strategies for handling messy data in general were not discussed.
-
Text analytic features built into Power Query.
-
Power Query’s duration syntax, used to work with dates and times.
-
More advanced functions using table and list types, in particular generating and accumulating functions.
-
Connecting to many commonly encountered data types, including JSON, PDF, other databases, files stored on SharePoint, and web sources.
-
Parameters within the Power Query Editor. While custom functions were discussed, one may define parameters within the Power Query Editor, and these parameters may be accessed by queries or functions. This feature was not explored in this paper because, in our experience, parameters can be brought into the Power Query environment by accessing named ranges and tables in the current workbook. The advantage is that the parameters can be modified and queries refreshed without opening the Power Query Editor. Nonetheless, this feature may be of interest, and was perhaps designed with the Power BI implementation of Power Query in mind.
2.3. Additional Guidance
2.3.1. Effective query writing
In addition to the points raised in the preceding discussion, some suggestions for effectively building queries include:
-
When initially drafting a query, we have found it to be efficient to first maximize reliance on Excel’s automated prompts and then revisit the automatically generated code to debug or edit for efficiency and tidier M statements.
-
If the underlying data set has the potential for a dynamic number of columns, be sensitive to the possible downstream impact when composing query statements that reference specific column names. If a column name is referenced in a step but the underlying column is not loaded at that point in the query’s operation, an error will be returned. An example would be when the user wants to keep a fixed set of columns (say A, B, and C), and remove all others (which could vary). A possible way to proceed would be to highlight the columns to be retained and instruct the query to “remove other columns” rather than selecting the currently loaded columns to be removed and instruct the query to “remove columns.”
Several built-in features to aid query writing are worth noting:
-
Intellisense is available within the Advanced Editor to help with authoring code, and many actuaries used to writing code may be used to features like this.
-
The “Column from Example” in the “Add Column” ribbon of the Power Query Editor can automatically generate a new custom column based on the user providing examples row by row. Any code generated should be scrutinized, but we have found this effective especially when parsing text-related data.
-
The “Data Preview” options under the “View” ribbon can help when initially reviewing large data sets to ensure an understanding of the underlying data types and distribution of values (figure 2.10).
-
If a query returns errors, Power Query can generate separate queries that return the values generating the errors, which can aid in debugging (figure 2.11; in this case the user could click on the “1 error” prompt and a separate query would be generated that would return the row generating the error for diagnostic purposes).


Several pitfalls have been previously discussed, but two are worth mentioning in this section:
-
Unlike formulas written in-spreadsheet, M is a case-sensitive language, so care should be taken with this feature when referencing user-defined objects or when debugging.
-
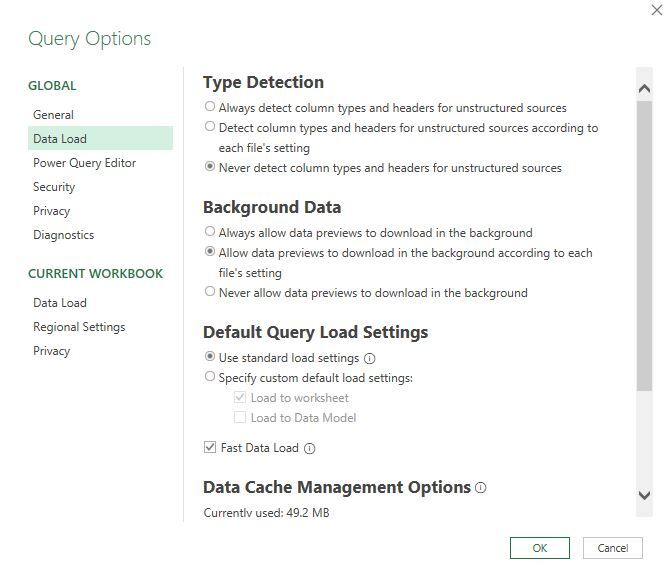
The code automatically generated using Excel’s automated prompts may include several distinct M statements, some of which may have been introduced without the user’s awareness. These should be reviewed to verify there are no unintended downstream impacts. Many of these are benign, but the “Changed Types” step (specifically, a call of the Table.TransformColumnTypes( ) function), can result in unintentional type change (this was alluded to in Section 2.1.2). In general, we have found suppressing type detection to be a leading practice (figure 2.12; this may be accessed from the Excel ribbon via “Data” → “Get Data” → “Query Options”).
2.3.2. Performance considerations
When working with larger data sets, performance could become an issue. Some considerations and suggestions include:
-
If a step in your query is being referenced multiple times, or out of order, place the code for that step within a Table.Buffer( ) or List.Buffer( ) statement, depending on the data type, to prevent unnecessary reruns of earlier steps. Example 2.2.4 includes several instances of Table.Buffer( ).
-
When working with larger data sets, performance can be improved by applying any relevant filtering as soon as possible in the order of query steps and applying summarizing or sorting toward the end.
-
Certain costlier data transformations have the potential for overuse and should be used strategically, lest they become drains on memory. Examples include pivoting and unpivoting, grouping, and merging.
-
When executing queries that reference external databases, Power Query naturally will try to maximize the amount of actual evaluation performed by that external source rather than Excel, to the extent allowed by the capabilities of that database and according to the syntax of the underlying M statement (this is called “query folding”). Nonetheless, to the extent that it is practical, the user may find performance improvements by explicitly including transformations within the step that includes the external source’s native procedural language instead of applying those transformations directly with Power Query (such as the SQL statement in Example 2.2.7).
-
When authoring a new query, if the external data source is large or the connection is slow, consider creating an identically structured and smaller data set as a locally saved flat file (e.g., a *.csv) and connect to that file instead. This will speed up any initial writing and debugging, though caution should be exercised when generalizing to the full source lest working with a subset of the data source does not allow proper exploration of all relevant features of the data. The query can be later modified to connect to the proper data source when the workbook is placed into production. Similarly, if a folder of files is being imported, consider linking to a locally saved copy of that folder with only several files included.
-
If the initial data import and cleansing for a project is complicated and involves long runtime, multiple sources, or many steps, consider using a single workbook solely devoted for data preparation. The cleansed data can be exported into a table, and that table can be referenced by downstream workbooks. An example could be a Data.xlsx file that houses query statements that connect to an actuarial data warehouse and export loss triangles into tables. External workbooks containing the actuarial analysis for individual lines of business could then be structured to connect to the tables in Data.xlsx.
2.3.3. Project management considerations
When exploring the possibility of connecting directly to your company’s databases, we would recommend discussions with IT or the appropriate BI team to assist with not only establishing connections, but structuring the connection in a way that conforms to internal protocols. This is a crucial step, as IT policy may prioritize other users’ access to, for example, a claims database. They can therefore provide guidance when authoring query statements so that any queries submitted by the actuarial team are not interfering with higher-priority database functions. Further, these conversations could also identify data sources that do not currently have Power Query connections and a mechanism for delivery of the data in a usable format could be developed. An example could be that a monthly job is created to deliver a *.csv to a shared directory or appended to a table within the actuarial data warehouse, and the actuarial team’s power query statements connect to that source.
As with any use of technology, steps should be taken to maintain auditability of the work itself as well as guarding against errors. Beyond relying upon basic model governance leading practices, we have several specific suggestions related to Power Query:
-
Relying on workbook protection features to prevent query modification for workbooks in production.
-
When authoring queries, establish that all data transformations are exhibited on Applied Steps for ease of reviewing (or, if not, can be easily comprehended by in-code comments).
-
When accessing multiple data sources, accessing a single data source multiple times, or accessing a larger transactional database, consider including summary queries to aid in any sort of cross-checking or validation of completeness and accuracy.
-
To improve auditability, when accessing external files or querying external databases, return any timestamps showing the runtime of that database or when the external data file was modified (as in Example 2.2.6). Within the Power Query Editor itself, the local timestamp can also be returned showing when the query was run using DateTime.LocalNow( ).
-
Outside of the Power Query Editor, the workbook itself can be organized in a logical flow to aid review. An example could be as follows:
-
After including any sign-off sheets or documentation as per company model governance policies, add a single worksheet at the left-most portion of the workbook for storing any named ranges directly accessed by Power Query.
-
Next, include worksheet(s) housing tables exported by Power Query grouped and organized by purpose or structure.
-
Next, include all worksheets for performing calculations and making selections.
-
Finally, include all worksheets containing summary information or other outputs referenced by external files.
-
2.4. Actuarial Use Cases
Because Power Query is meant to be used for general data cleansing and manipulation, there is a wide variety of possibilities for implementation within actuarial workflows. Further, as many actuarial processes may include Excel as a step, there is the potential to leverage familiarity with existing workbooks by rehousing data preparatory steps within Excel to simplify and possibly accelerate the production of analysis workbooks. Furthermore, if Power Query is used entirely to process data (i.e., starting with raw data sources versus using an intermediary piece of software that exports the processed data into Excel), the entire ETL trail will be documented and quickly accessible in a single location. This can enhance transparency and simplify audits and technical reviews.
If Excel’s spreadsheet environment is being used to perform data preparation steps, this work could be moved within Power Query itself, with the following possible gains:
-
The steps recorded by the Power Query Editor may be easier to review or audit than transformations embedded in the spreadsheet itself.
-
Locating transformations within Power Query (and also adding protection to the workbook structure) can guard against unintentional errors, which could be introduced into an unprotected worksheet used for data preparation, particularly if any manual steps were involved.
-
Power Query’s own transformations are likely to be performed more quickly and can include timestamps, unlike calculations within the spreadsheet.
-
Power Query can connect directly to external data sources, rather than any manual import that was previously performed.
-
Disk space is saved, as data does not need to be stored for intermediate steps, and only the final cleansed data would need to be saved.
Finally, Power Query’s particular UI may enable low-code/no-code options for scalable functionality previously only accessible via authoring macros using VBA. Hurst (2021) discusses both the efficiency gains that may be achieved and requisite risk management techniques that should be considered, should Power Query either supplant or supplement legacy in-spreadsheet computations.
3. Power Pivot – Data Modeling Engine
3.1. Introduction & Overview
Power Pivot is a feature that allows for construction of more complex and informative data models than is possible with traditional pivot tables. In this context, what is meant by a “data model” is not a statistical model fit to a set of data, but rather the structure arising from a family of tables, relationships among those tables, as well as any expressions (which will be called “measures”) based on the data. Once constructed, these tables and measures can be deployed into pivot tables or charts in-spreadsheet for analysis or exhibition.
A workbook’s Data Model can be accessed from either the “Power Pivot” ribbon or the “Data” ribbon (figure 3.01). Multiple tables can be stored within the Data Model, and there is no limit to rows or columns similar to those placed on worksheets (though there are memory limits, which vary by version of Excel). Tables can be imported in a several ways, such as manually pasting in information, linking a table defined in the spreadsheet environment, linking to another source using Power Pivot’s automated prompt, or exporting into the Data Model via Power Query. The information stored in tables linked to other sources can’t be directly modified in the Power Pivot window; however, the contents of the linked tables can be refreshed manually or on a schedule.

Once tables have been imported into the Data Model, calculated columns can be added to them (figure 3.02; the calculated column “year” was added as an example, but not retained in the workbook example). The syntax for adding on calculated columns is very similar to that used for spreadsheet formulas, and the reference syntax is similar to that used by tables. As a leading practice, the use of calculated columns should be minimized because measures are more efficient, and overuse of calculated columns can potentially cause memory issues. Additionally, if Power Query is used to import and transform the information stored in the Data Model, it will be more efficient to create a column as part of the Power Query routine rather than adding a calculated column in the Data Model.

Relationships between different tables can be defined by the user and are most easily visualized by the “Diagram View” (figure 3.03). More information is also available on the “Design” ribbon, under “Relationships.” To help with performance, a “star schema” structure should be favored, where any tables used to map redundant information (a.k.a. “dimension” tables; an example being detailed coverage information mapped to larger line of business groupings) only link to tables containing high volumes of individual records (a.k.a. “fact” tables; an example being individual claim financial records).

Once the structure of the Data Model has been defined as respects individual tables and their relationships, measures can be written to perform computations and summaries. A measure is a function that is computed directly based on values in the Data Model and can be deployed into pivot tables and charts that reference both measures and columns in the Data Model. The language used to write measures is DAX (short for “Data Analysis Expressions”). Measures can be written within the Data Model, under individual tables (figure 3.04), or within the spreadsheet environment, under the “Power Pivot” ribbon (figure 3.05). A measure will be associated with a single table in the Data Model; however, columns from multiple tables in the Data Model can be referenced within a single measure, and measures may reference other measures. Longtime Excel users may be familiar with “calculated fields” in pivot tables, and measures are similar in that respect, but much more powerful.


Unlike the M language, which is not essential for a user to learn to be effective with Power Query due to the many routines that compose M statements automatically, it is important for the user to have a good working knowledge of DAX in order to write measures. However, the DAX syntax is very intuitive and similar to many in-spreadsheet functions. Documentation for DAX, including references for various functions cited in this paper, can be found on Microsoft’s website (“DAX Reference” 2024).
Finally, the information within the Data Model and associated measures is accessed by creating a pivot table or pivot chart using the workbook’s Data Model (figure 3.06). All tables and measures within the Data Model will be available for use within a single pivot table, and features such as slicers and timelines can also be synchronized with the Data Model.

3.2. Spreadsheet Examples
3.2.1. Experience review
The file pp_experience_review.xlsx was set up to be a simple dashboard that begins with tables of calendar month premium and loss data and calculate QTD loss ratios. Two tables of data were import via Power Query from *.csv files, mappings to larger regional areas and producers were added by linking tables within the spreadsheet environment, and a master table of dates was automatically generated by selecting the “Date Table” feature on the “Design” ribbon in Power Pivot. Relationships were added, several measures were added, and a pivot table with associated slicers was defined.
-
loss_ratio: A generic loss ratio calculation.
-
loss_ratio_qtd: QTD loss ratio calculation using the TOTALQTD( ) function.
-
loss_ratio_qtd_cw: This measure calculates QTD loss ratios, but is designed to calculate independently of any filters applied to the pivot table. Additionally, this was defined using the CALCULATE( ) function, which takes as its first argument the particular expression to compute, and then takes different filtering statements as other arguments. In this case, a filter was applied to determine relevant dates in the particular quarter, and the ALL( ) express was called. The purpose of ALL( ) is to remove any filter applied by the context defined by a particular pivot table prior to the implementation of CALCULATE( ). Therefore, when different options for producer or region are selected on the slicer in the worksheet “pivot qtd”, the value of loss_ratio_qtd_cw will not change.
3.2.2. Allocating aggregate reserves
The file pp_allocation.xlsx was set up to allocate the IBNR selected from a reserve analysis to smaller subgroups and dynamically exhibit the implied loss ratio by segment, as well as provide a table for the finance department. In this case, the underlying segment data was manually pasted into the Data Model (not a leading practice, but shown as an example), and the overall aggregate IBNR and weights are contained in a table. If the weights are changed, the connection should be refreshed and the pivot and chart will update. A series of measures were defined to clearly break up the steps of allocating according to the different methods and a final average. Several features are worth highlighting:
-
Two calculated columns, key_mga and key_state, were made. In practice it is better to define these fields prior to the load into the Data Model to improve performance and memory usage.
-
ALLEXCEPT( ) was used to calculate totals by segment, but not by ay.
-
RELATED( ) was used in a manner similar to look up functions, in order to match a particular segment–ay pair to the aggregate IBNR for that ay. RELATEDTABLE( ) can be used in a converse way across a many-to-one relationship to return a table of rows that are related to a single value.
-
SUMX( ) was used to iterate the allocation operation across each individual row of analysis_summary and aggregate via summation. Note that this is different than the more traditional SUM( ) function, which takes a single column as its input. SUMX( ) is part of a class of iterator functions that iterate a particular expression over a particular table and may aggregate the results. Other examples include AVERAGEX( ), MINX( ), MAXX( ), COUNTX( ), CONCATENATEX( ), as well as FILTER( ). Note that FILTER( ), while technically an iterator, actually returns a subset of a particular table based on the results of the filtering criteria applied to each row of that table.
-
DIVIDE( ) was used instead of the divide operator to handle divide-by-zero errors, in this case returning BLANK( ).
3.2.3. Claim data manipulation
The file pp_claim_data.xlsx takes the loss development history data set used in Section 2 and applies further transformations in Power Query to create a dimension table for claim information and a fact table for claim financial information. Measures are then defined to calculate claim counts, limited losses (via selecting limits on slicers), and loss development factors. The structure and measure definitions were chosen to illustrate the importance of understanding relationships between tables and different evaluation contexts, as well as to highlight more complicated DAX functions and the use of disconnected tables.
A disconnected table that gives the perimeter of a loss development triangle was defined and manually input into the Data Model (d_triangle); a measure defining ay-based loss development factors was written (ldf_ay); and a measure counting reported claim counts (claim_count). These measures are more complex than those from the previous sections, insofar as several intermediate steps using VAR and RETURN declarations were introduced. Additionally, the function DISTINCTCOUNT( ) was used to count claims by counting unique claim numbers appearing in the scope of the measure, and DAX’s operator for a logical “and” (&&) was used in a FILTER( ) call. On the “pivot tri” worksheet, two pivot tables are shown with the same measures, but different years from different tables within the Data Model along the vertical axis resulting in a subtle difference. The first uses the year field in d_triangle (as intended by the measure’s definition), and the second uses the ay field in d_claim, and a diagonal of 1.000s is returned by the latter. This is because of the way the context determined by the pivot table interacts with the max_age variable defined in the ldf_ay measure. If, as in the case of the first pivot table, year = 2023, then max_age = 12 and the MIN(d_triangle[age]) will equal 12, as d_triangle has been filtered by the context of the pivot table. If, on the other hand ay = 2023 (which is a field from d_claim) as in the case of the second pivot table, then max_age = 240 and MIN(d_triangle[age]) remains at 12, as d_triangle has not had a filter directly applied to it as d_triangle is disconnected from d_claim.
Two other disconnected tables containing single columns of numbers (limit_below and limit_above) were defined and linked to slicers in order to dynamically calculate layers of loss by calling the excess_loss measure. The excess_loss measure uses SUMMARIZE( ) to first calculate gross losses by claim, and then SUMX( ) is used to iterate down the rows of the resulting claim-level information in the intermediary table my_table and calculate excess layer losses. The measures limit_below_selected and limit_above_selected are used in an idiosyncratic way with the slicer to allow the user to select the top and bottom of the desired excess loss corridor. If filters were removed from the slicers, zeros would be returned for excess_loss as the bottom limit would be 1,000,000 and the top limit would be 2,500. The first pivot table on the “xs tri” worksheet calculates inception-to-date excess factors as intended. However, the next three tables both produce incorrect excess triangles results due to different issues, discussed in order below, and the final table includes a correct implementation, but requires a more complicated measure (excess_factor_tri):
-
The ay x cy triangle is incorrect as only the transactions within each cell enter into the excess_loss calculation. Therefore, the first diagonal is correct (and calculates essentially the excess factors at age 12 ), but all subsequent cells are incorrect.
-
The ay x age triangle is incorrect as age is defined for d_triangle, a disconnected table. Therefore, no distinction is made by cy, and the value is constant across each row.
-
The year x age triangle is incorrect because both year and age are fields in the d_triangle table, which is disconnected from both f_loss and d_claim. Therefore, the same value is being returned for the excess_factor measure in all cases, and this value is equal to the excess factor calculated for all transactions with state = “AZ,” which can be verified by removing the ay filter on the first pivot table on this worksheet.
3.2.4. Topics not reviewed
-
Preceding examples highlighted that unintuitive results can be generated within pivot tables due to the interaction of measures and filters. More thorough discussions of “row context” and “filter context” concepts, which can shed light on this issue, can be found both on the web and in the DAX references mentioned in Section 5.3.
-
As with M, and base Excel, there are many built-in DAX expressions that the interested reader is invited to explore. In particular:
-
There is an abundance of DAX expressions designed to manipulate and summarize time series, which may be valuable to some readers.
-
Iterator functions (which typically end in “X”), alluded to previously.
-
Many DAX expressions designed to manipulate and return tables were not discussed.
-
3.3. Additional Guidance
3.3.1. Structuring the Data Model
-
In order to maintain a star schema, consider ways to maximize information stored in the fewest number of dimension tables (or lookup tables) and avoid creating relationships between dimension tables. An example of a structure to avoid would be a fact table of claim transactions related to a dimension table of products, which is then related to a dimension table of alternate product groupings or product subgroups. It is preferable to have a larger dimension table that includes information on both the larger and finer lookups within a single, larger dimension table. This may be accomplished by additional processing prior to the Data Model load, which creates a cross join between the two dimension tables.
-
Consider ways to minimize the number of data transformations that have to happen within the Data Model itself, especially via calculated columns. For users familiar with tables, it may seem intuitive and preferable to add calculated columns to tables. However, this can potentially create memory and performance issues and should be avoided as a matter of leading practice. Additional pre-processing steps could occur upstream either within the original source database or, if using Power Query, within the query statements prior to the Data Model load.
-
Related to the previous point, consider removing columns from the Data Model entirely if they are not needed to maintain inter-table relationships or to inform any measures or anticipated pivot tables, as excluding them will free up memory.
-
When working with any information indexed over time, having a single master table with date information is crucial to maintain ease-of-use and accuracy with many of DAX’s time functions. Power Pivot can generate one automatically (via the “Date Table” command on the “Design” ribbon), but if additional nuancing is needed, one may need to be generated via Power Query.
3.3.2. Writing measures
-
Measures can be composed within Power Pivot (shown at the bottom of their associated tables) or in-spreadsheet. In general, the latter is preferable as that option has better error checking and formatting features and can be accessed while working with pivot tables in-spreadsheet.
-
When composing and debugging a new measure, it can be helpful to first structure the desired pivot table where the measure will used and have that open while composing the measure. This will allow the user to evaluate the results of the measure with different pivot table contexts applied. It is also possible to apply filters to the different tables within the Power Pivot environment and view the results of various measures (which are displayed at the bottom of their associated tables).
-
Care should be taken to understand any interactions that filters within an individual pivot table may have with the context assumed by a particular measure, as non-intuitive values may emerge.
-
Any filtering statements applied within a particular measure will override any filters that are active in the context of a particular pivot table using that measure. Further, pivot table grand totals for measures are computed by applying the measure to the underlying table in aggregate rather than adding up the results of the measure applied to individual pivot table cells. As an example of both, consider the “premium grand total” worksheet from Section 3.2.1, which shows a grand total of premium by year and returns total premium figures both individually and in aggregate, alongside the measure premium_2023, which returns the same value for each row and in total.
-
While DAX syntax is very readable and DAX expressions have intuitive names, it is helpful to have familiarity with the type of structure(s) particular functions take as input and provide as outputs in order to evaluate or debug a particular measure (whether scalars, columns, rows, or entire tables).
3.3.3. Accessing the Data Model and measures
-
There are a variety of formatting options for pivot charts, conditional formatting as applied to pivot tables, and a KPI feature available with Power Pivot. All these can aid in visualizing results. However, these options may not prove to be as expansive or compelling as those offered by Power BI, and if the actuary has access to Power BI for delivering results, that software package may be a better choice. Fortunately, Data Models and measures built in Excel can easily be translated to the Power BI environment.
-
For complex dashboards built on large Data Models, the use of many slicers that reference multiple pivot tables can cause performance issues. The user may want to review the slicer setup and adjust cross-referencing to minimize these issues.
-
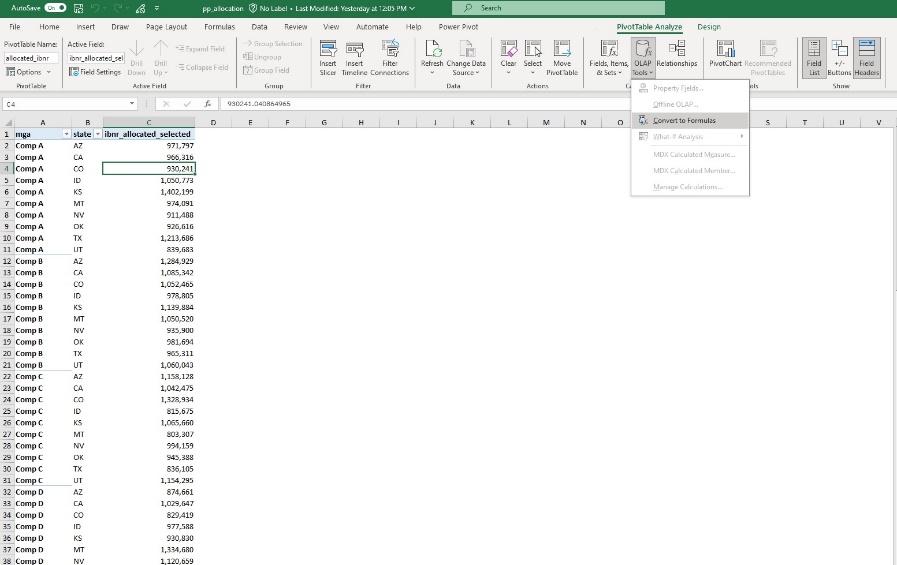
Longtime Excel users may have encountered GETPIVOTDATA( ), which can generate values from a pivot table external to that table’s structure elsewhere in-spreadsheet. Similarly, information can be extracted from the Data Model using Cube functions. Cube functions can be written from the ground up, and existing pivot tables based on the Data Model can be converted to Cube formulas by selecting the target pivot table and “Convert to Formula” on the “PivotTable Analyze” ribbon (figure 3.07). An example of this can be seen on the “for finance cube” worksheet from Section 3.2.2.

3.4 Actuarial Use Cases
Actuarial teams are frequently called upon to present compelling visualizations and provide informative detail underlying their analyses. Power Pivot is an easily accessible and powerful option for executing this task in the familiar environment of Excel, especially when coupled with Power Query for data preparation. Further, as an internal dashboarding tool, we have found this to be just as effective as other BI packages, particularly when reviewing experience during monthly close activities.
In addition to visualizing results of actuarial analyses, Power Pivot naturally lends itself to building analytic tools to inform many financial functions that take large volumes of data as input, including the results of actuarial analyses. Examples would be FP&A and capital modeling activities.
Finally, as many reserving teams have financial reporting responsibilities, we have found the Data Model to be an intuitive and effective means to rapidly prepare, review, and submit many accounting calculations that teams often find themselves owning. Examples include allocation of reserve indications and the computation of reinsurance balances and intercompany eliminations.
4. Enhanced Spreadsheet Environment
4.1. Introduction & Overview
Though many spreadsheet users may not think of themselves as programmers, spreadsheet development is a form of software development. Indeed, Hermans et al (2016) argues that spreadsheets are, in fact, code, and describes how software development techniques could be repurposed for spreadsheets as quality control measures. Further, a 2021 report by O’Reilly (2021) noted how Excel can be properly thought of as a low-code tool, though certain limits on its structure prohibit widely used software development features which allow for convenient version control (e.g., Git repositories) and diagnosing errors.
The features discussed in this section represent changes to in-spreadsheet functionality that make working with Excel feel more like coding. These features have a greater likelihood of being familiar to actuaries who are accustomed to working in Excel’s spreadsheet environment than Power Query and Power Pivot do. Further, as they are embedded in-spreadsheet, they are much more accessible than Power Query and Power Pivot.
Documentation for the various functions cited here may be easily found within the Excel application itself, or via searching for particular functions within the Excel documentation published on Microsoft’s website (Excel Help & Learning, 2024).
The attached workbook dynamic_arrays_lambda.xlsx includes simple examples of the features discussed in this section.
4.2. Dynamic arrays and supporting functions
Many actuaries will be familiar with the awkwardness of using arrays to perform matrix-based calculations, as a block of cells may be converted to an “array formula” by highlighting that block and hitting CTRL + SHIFT + ENTER (Bartholomew (2019) observes that this has contributed to the unpopularity of array formulas relative to their potential benefits).
With the introduction of dynamic arrays into Excel, the spreadsheet environment can now treat a reference to a range of cells in an intuitive and nimble fashion. For example, if a function naturally generates arrays (including legacy formulas such as LINEST( )), the values will spill out into the necessary rows and columns in a dynamic way, as they adjust to the necessary dimensions required by the formula. If there are cells containing values or formulas within the range necessitated by a particular dynamic array, a “#SPILL!” error will be generated.
To reference a particular dynamic array as an array, the hash (#) character needs to be added to the cell reference. When writing functions or mathematical operations with dynamic arrays, calculations are performed in an intuitive fashion that matches cells to relative cells. It is important for actuaries to note, though, that mathematical operations do not naturally treat an array structure as a matrix, and legacy formulas that take matrices as arguments must be used, such as MMULT ( ).
Named ranges can be defined based on dynamic arrays, but this must be done in the named range editor to include the # designator. These dynamic named ranges can be referenced in a similar fashion to static named ranges downstream elsewhere in-spreadsheet, for data validation, chart references for flexible visualization, or passed into Power Query statements in a fashion similar to named ranges based on tables or static ranges.
One limitation of dynamic arrays is that tables cannot take a dynamic array as an input. However, if a formula designed to output arrays only returns a 1 x 1 array (i.e., a scalar) as an output (such as FILTER( )), there will be no errors returned within the table.
Several functions were introduced with dynamic arrays in mind starting in 2020, and more have been introduced since then. Particularly useful functions aiding in dynamic array manipulation in include UNIQUE( ), FILTER( ), and SORT( ). Note that many of these functions will return a #CALC! error if an empty array is computed, so some care may need to be taken to handle this error when constructing formulas. The functions SEQUENCE( ) and RANDARRAY( ) deserve to be highlighted as they can be used to generate arrays from non-array inputs, and there are functions built to combine distinct arrays into a single array such as HSTACK( ) and VSTACK( ).
4.3. LAMBDA( ) and LET( )
With the introduction of LAMBDA( ), custom functions can be composed in Excel’s named range editor (accessed most easily via CTRL + F3), and several other functions which take LAMBDA( ) expressions were also introduced. LAMBDA( ) allows the user to create custom in-spreadsheet functions without having to resort to using them via add-ins or developing them in VBA. Additionally, the LET( ) function allows users to do this in a limited way within the context of the LET( ) expression itself, which can improve legibility and also possibly improve performance by limiting the number of times a particular computation is performed. Functions defined by LAMBDA( ) expressions are portable throughout the entire workbook. While custom functions could always be created via VBA, the learning curve for both LET( ) and LAMBDA( ) expressions is not nearly as steep.
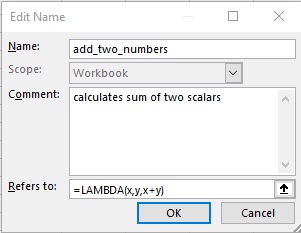
To create a LAMBDA( ) expression, once the structure of the formula is known, it can be added as a new named range in the named range editor (figure 4.01), and accompanying documentation can also be included. An arbitrary number of arguments can be given for the function, and the last argument of LAMBDA( ) is what will be returned upon evaluation. For example, if the function add_two_numbers is defined as LAMBDA(x,y,x+y), it can be called in the spreadsheet environment as add_two_number(3,4) = 7. Arrays can also be used as arguments, which can provide for very powerful expressions to be crafted. For functions taking optional arguments, ISOMITTED( ) may be employed to handle omissions in the function definition. LAMBDA( ) declarations can take other functions within their evaluation statements, and recursion is also possible.
_defined_in_the_named_range_editor.jpg)
LAMBDA( ) can also be used in an ad hoc manner within the spreadsheet environment, perhaps to design a function before entering it into the named range editor. When writing a LAMBDA( ) expression this way, specific inputs must be provided as arguments, otherwise a #CALC! error will be returned. When developing a new function via LAMBDA( ) expressions, in-spreadsheet LAMBDA( ) calls can be used to first build and test the expression prior to defining it in the named range editor.
There are also several functions that are designed to call LAMBDA( ) within their own expression and apply the LAMBDA( ) expression in a particular context, such as applying a formula to every row in an array (e.g., BYROW( )). LAMBDA( ) expressions defined as functions in the named range editor may also be called in this respect.
The elr_generalized_cape_cod function in the sample workbook shows a LAMBDA( ) function with several nested LAMBDA( ) and LET( ) statements, as well as an implementation of optional arguments. Interested users may also review Bartholomew (2023) and Wittwer (2024), which both have elaborate examples using recursion.
4.4. Actuarial use cases
While many power users of Excel may rejoice with new functions like UNIQUE( ), in our view, the introduction of dynamic arrays, LET( ), and LAMBDA( ) do not have the potential to be as transformative to actuarial workflows as the other features discussed in this paper. Nonetheless, Excel’s spreadsheet environment is (and will likely continue to be) widely used both for exploratory data analysis, prototyping, and operationalized actuarial modeling and data processing for smaller data sets. Therefore, these features do reflect, at the minimum, true quality-of-life improvements and, as a maximum, perhaps they will foment a shift in how users construct spreadsheet models. In our view, the interaction of the dynamic array functionality with LAMBDA( ) expressions (both taking arrays as inputs, and using functions to apply LAMBDA( ) expressions to arrays) does represent a substantial step forward in options for constructing in-spreadsheet models.
Several positive suggestions for using these features follow:
-
Consider how large blocks of calculations (whose dimensions may vary) can be reformulated into array expressions for simplicity and efficiency when referencing between worksheets or workbooks.
-
There will always be a need to quickly wrangle smaller data sets in-spreadsheet. Functions that are designed to work with dynamic arrays shine in this regard. For actuarial teams that frequently interact with new or changing data sets, having familiarity with these formulas can expedite in-spreadsheet data wrangling and improve its auditability.
-
Consider how the use of named ranges can be leveraged to clarify the logical flow of in-spreadsheet calculations, both by using named ranges to be defined by dynamic arrays and with LAMBDA( ) expressions. Also, consider requiring documentation associated with the named range definitions. For LAMBDA( ) expressions defined in the named range editor, consider including a worksheet that has a copy of the LAMBDA( ) expression’s code formatted in a readable fashion to aid technical review, as the formula bar within the named range editor does not allow for functions to be viewed in a format that spans multiple rows (for which the in-spreadsheet formula bar does allow). For a suggestion, see the elr_generalized_cape_cod worksheet in dynamic_arrays_lambda.xlsx. Additionally, the Excel Labs add-in provides a text editor interface that may be used to define LAMBDA( ) functions in a more legible way.
-
Aside from improving the general auditability of in-spreadsheet calculations, consider how functions currently housed within VBA or via add-ins can be moved in-spreadsheet with LAMBDA( ) expressions.
Regarding the model risk introduced by these features, we would agree with Bartholomew (2023) insofar as the reduction of manual steps can reduce accompanying risk and quality issues. However, any increased complexity of in-spreadsheet calculations carries with it an increase in certain types of model risk that actuaries should recognize in their model governance protocols. The examples adduced in Bartholomew (2023) and Wittwer (2024) should make this clear. A study by Sarkar et al (2022), in which over 2,500 spreadsheet users were surveyed on their impressions of LAMBDA( ) expressions, noted that the increased abstraction was accompanied by the need to increase efforts directed toward achieving and maintaining spreadsheet integrity.
5. Conclusion
5.1. Excel and the actuary
While the reader may sense our enthusiasm for Excel, it is important to recognize that there are limitations that persist despite the improvements discussed in this paper. To mention several (see also Birch et al. (2017) for a discussion of Excel’s strengths and weaknesses):
-
Excel is not ideal for resource-intensive modeling that may be better served by distributed computing solutions, and it does not offer easily accessible out-of-the-box statistical tools. Further, an actuarial manager may determine that it is prudent to purchase proprietary actuarial software that places minimal technical demands on her team to develop and maintain in-house analytical templates.
-
Actuaries should avoid using Excel to store data—there are simply too many risk factors and inefficiencies in doing so. Further, actuaries should consider how the results of their analyses (e.g., ultimate loss selections, stochastic cash flows) can be archived and maintained on a database for easy access later (perhaps with Power Query!).
-
As alluded to previously, there are limited collaboration options and diagnostic tools available for Excel qua a software development program, particularly in comparison with what is on offer to create, for example, a Python application. However, as cloud-based options emerge, the tides could shift in this regard. For instance, Excel for the web has the ability for multiple users to edit a file with changes tracked.
-
The flexibility granted by Excel’s sandbox-like environment coupled with its wide adoption among end users can be a “double-edged sword” (Sarkar et al. 2022), possibly exacerbated by the aforementioned lack of development features. In our view, however, quality issues typically arise due to a lack of proper model governance, whether it be a failure to establish controls or follow existing procedures, rather than arising from the form of the software itself.
Despite these caveats, Excel has proved itself to have staying power as the most successful end-user programming software application on offer (Hermans et al. 2016). Therefore, we actuaries should view its ubiquity within financial services organizations as an opportunity to consider how it can be leveraged to improve the quality of our work.
If interested, how should an actuarial team begin to use Power Query, for example? Medium-to-larger organizations likely have one or two Excel champions who could provide consultation, training, and help with integrating these more advanced features as part of ongoing modernization efforts. Additionally, if actuaries are familiar with Power BI, competency gained by using Power Query and Power Pivot is easily translatable between that program and Excel, as both applications use these features. Finally, in addition to the resources mentioned in Section 5.3, there is a wealth of free training on the web.
5.2. Features not discussed
While the scope of this paper was focused on features in the desktop version of Excel, we would encourage interested actuaries to explore capabilities that are either designed for or accessible only for web-based implementations of Excel, particularly options for collaboration and automation. Also available are artificial intelligence add-ons (Microsoft Copilot, Azure Machine Learning), process automation features (Office Scripts and Power Automate), and Excel Labs (which allows for crafting in-cell statements and LAMBDA( ) expressions in a more traditional code editor, as well as implementation of generative AI functions). Finally, the ability to write Python code directly in-spreadsheet is currently in limited release and stands to make this widely used language more accessible to actuaries.
5.3. Additional resources
In addition to the online documentation mentioned previously (“DAX Reference” 2024; Excel Help & Learning, 2024; “Power Query M Formula Language” 2024), we have found several other references to be helpful.
Raviv (Raviv 2015) provides a thorough guide to Power Query that includes both its Excel and Power BI implementations, and includes many examples. This book concludes with a focused discussion of advanced text analytic features. For a more introductory approach that also includes both Excel and Power BI implementations, the shorter volume by Puls and Escobar is excellent (Puls and Escobar 2021).
For those interested in understanding the DAX language in greater depth, Russo and Ferrari (Russo and Ferrari 2019) produced a comprehensive guide that is relevant to Data Models constructed within Excel, Power BI, and SQL Server Analysis Services (Russo and Ferrari 2019).
Though outdated due to the versions of Excel at the time of its authorship, we found the guide by Collie and Singh (Collie and Singh 2016) to be an extremely effective introduction to working with the Data Model, as well as providing a friendly introduction to Power Query.
Finally, Mount (Mount 2024) covers the features discussed in this paper and several other topics, including the use of certain machine learning add-ins as well as using Python to interact with Excel.
Acknowledgment
The author is grateful for the encouragement and feedback provided by Lynne Bloom, Dawn Fowle, David Rosenzweig, and Scott Whitson.
Supplementary material
An archive titled “Examples.zip” is included as an attachment to this paper. This file may be decompressed and saved locally. The file structure should be maintained, and several query statements should be updated manually by the user to reflect the folder’s location, as indicated in the narrative of this text.
Biography of the Author
Jonathan Winn currently provides consulting and actuarial services. Previously, he was Vice President and P&C Appointed Actuary at a national multiline insurance carrier and spent over a decade at a global actuarial consulting organization. He has a degree in Applied Mathematics and Computational Science from Caltech, is a Fellow of the CAS, and is a member of the American Academy of Actuaries.